GHTraffic 데이터셋 서비스 지향 컴퓨팅 재현 연구를 위한 새로운 자원
초록
본 논문은 GitHub API 트래픽을 기반으로 실제와 합성 HTTP 트랜잭션을 결합한 대규모 데이터셋 GHTraffic을 소개한다. 데이터셋은 성능 벤치마킹, 기능 테스트, 서비스 가상화 등 다양한 연구·실험에 활용될 수 있도록 설계되었으며, 크기·다양성·재현성·표준 준수 등 6가지 요구사항을 만족한다.
상세 분석
GHTraffic은 현대 웹 서비스가 활용하는 풍부한 HTTP 기능을 포괄적으로 담은 최초의 공개 데이터셋이라고 할 수 있다. 저자들은 먼저 서비스 지향 컴퓨팅(SOC) 분야에서 재현 가능한 실험을 지원하기 위해 “데이터셋 → 실험 → 결과”의 순환 구조가 필요함을 강조한다. 이를 위해 실제 운영 중인 대규모 서비스인 GitHub의 REST API 호출을 역공학하여 기본 트랜잭션을 추출하고, 스냅샷 기반 GHTorrent 데이터베이스와 교차 검증한다. 그러나 스냅샷은 상태 변화를 일으키는 GET 요청이나 실패 응답 등 관측되지 않는 트랜잭션을 누락한다는 한계가 있다. 저자들은 이 문제를 해결하기 위해 비상태 변경 요청(주로 조회)과 실패 시나리오를 합성 데이터로 보강하였다.
데이터셋 설계 단계에서 저자들은 네 가지 주요 사용 사례(성능 벤치마킹, 기능 테스트, 서비스 가상화, 학술 연구)를 도출하고, 각각에 대응하는 요구사항 R1–R6을 정의하였다. R1은 “대규모이면서 관리 가능한” 크기를 의미하며, 이를 위해 여러 규모(소형·중형·대형) 에디션을 제공한다. R2는 사용 편의성을 위해 JSON 기반 스키마와 파싱 스크립트를 포함한다. R3는 데이터가 실제 서비스 로그에서 추출되거나 명확한 합성 규칙에 따라 생성되었음을 보장한다. R4는 최신 HTTP/REST 관행을 반영하기 위해 GitHub API의 최신 버전을 사용한다. R5와 R6은 HTTP 표준(메서드, 상태 코드, 헤더) 준수와 다양한 메서드(GET, POST, PUT, DELETE, PATCH 등) 및 응답 코드(200, 201, 204, 400, 401, 403, 404, 500 등)를 포함한다.
관련 연구와 비교했을 때, 기존 벤치마크(TPC‑W, SPECweb2009 등)와 보안 데이터셋(DARPA, CSIC) 등은 주로 GET/POST와 200 응답에 국한되어 현대 API가 활용하는 풍부한 HTTP 메서드와 상태 코드를 충분히 반영하지 못한다. GHTraffic은 이러한 편향을 극복하고, 실제 서비스에서 발생하는 복합적인 요청 흐름과 오류 상황을 포함한다.
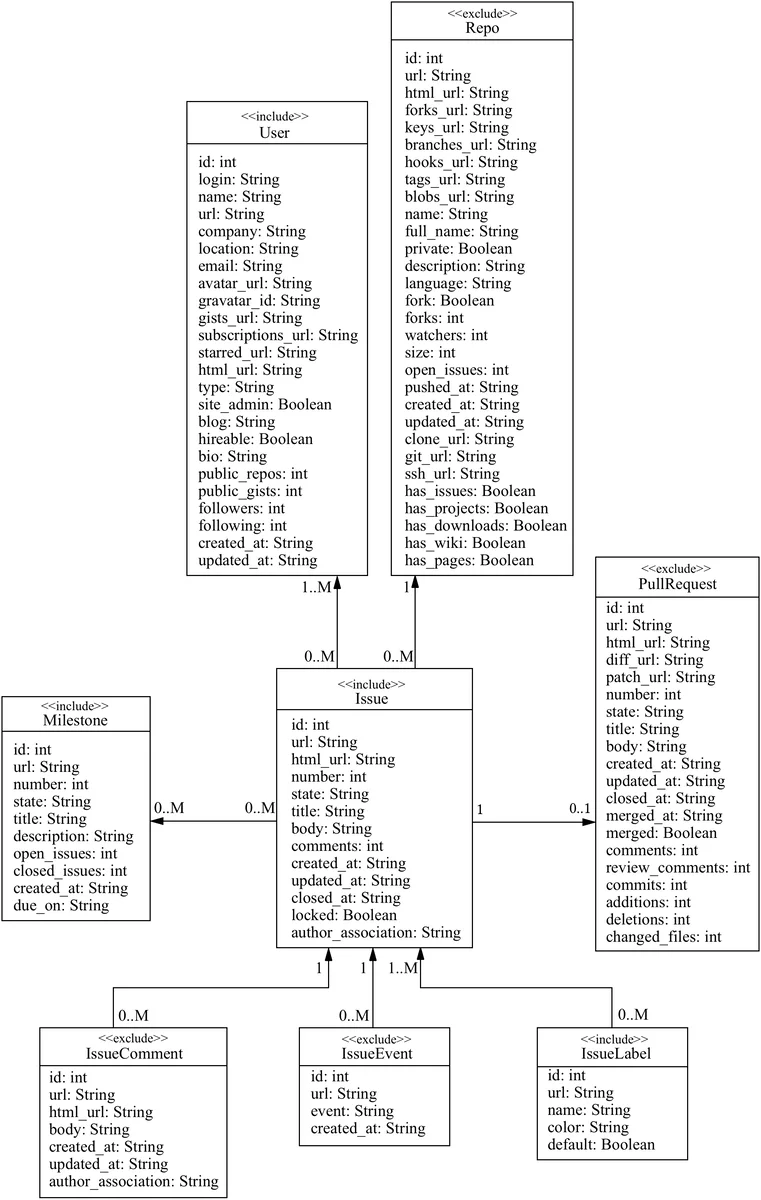
구축 과정에서는 GitHub Issue 트래킹 시스템을 중심으로 데이터 범위를 제한하였다. Issue, User, Milestone, Label 네 개의 엔터티를 선택하고, 각 엔터티에 대한 CRUD 연산을 모두 모델링했다. 스냅샷에서 추출한 트랜잭션은 1억 건 이상이며, 합성 트랜잭션을 추가해 전체 규모를 1.5배 이상 확대했다. 데이터는 압축된 JSON 라인 파일 형태로 제공되며, 메타데이터 파일에 스키마와 필드 설명이 포함된다.
평가에서는 트랜잭션 분포, 메서드 비율, 상태 코드 비율, 시간적 특성 등을 분석했으며, 실제 GitHub API 호출 패턴과 높은 일치도를 보였다. 또한, 제공된 스크립트를 이용해 벤치마크 테스트와 서비스 가상화 모델 학습을 수행한 사례를 제시한다.
위협 요소로는 역공학 과정에서 누락된 요청, API 버전 변화에 따른 데이터 불일치, 합성 데이터의 현실성 부족 등을 언급한다. 이를 최소화하기 위해 지속적인 업데이트와 커뮤니티 피드백을 받겠다는 방침을 제시한다.
결론적으로 GHTraffic은 SOC 연구자와 엔지니어에게 재현 가능한 실험 환경을 제공함으로써, 성능 평가, 기능 검증, 머신러닝 기반 서비스 가상화 등 다양한 분야에서 표준 데이터셋으로 활용될 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기