노래 음성 음소 구간 분할을 위한 계층적 시작점 추정
초록
본 논문은 경극 독창 음성 데이터를 이용해, 음절·음소 시작점 검출 함수를 동시에 학습하는 CNN과 사전 제공된 대략적 지속시간 정보를 전이 확률로 활용하는 지속시간 기반 HMM을 결합한 두 단계 방식으로 언어에 독립적인 음소 구간 분할 방법을 제안한다. 제안법은 기존 HSMM 기반 강제 정렬 대비 온셋 검출 F1 75 %·음소 구간 정확도 84 %를 달성하며, 특히 음절·음소 경계 추정에서 큰 향상을 보인다.
상세 분석
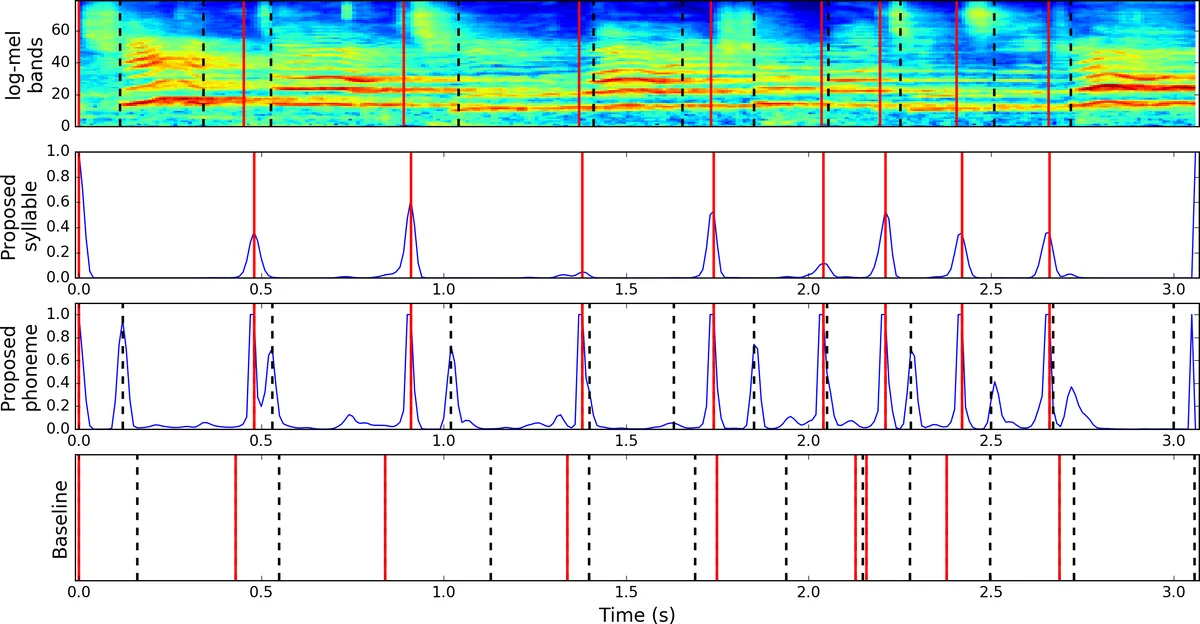
이 연구는 노래 교육, 특히 경극과 같은 전통 음악에서 발음 정확성을 자동으로 평가하기 위한 전처리 단계인 음소 구간 분할에 초점을 맞춘다. 기존 음성 강제 정렬 방법은 언어 의존적이며, 대규모 라벨링된 코퍼스가 필요하지만, 저자는 언어에 구애받지 않는 접근법을 설계한다. 핵심 아이디어는 두 가지 정보를 결합하는 것이다. 첫 번째는 CNN 기반의 온셋 검출 함수(ODF)로, 로그‑멜 스펙트로그램을 80 × 15 크기의 컨텍스트 윈도우로 입력받아 음절과 음소의 시작점을 동시에 예측한다. 여기서는 하드 파라미터 공유 방식의 멀티태스크 학습을 적용해, 두 출력이 동일한 특성 추출 층을 공유함으로써 데이터 부족 문제를 완화하고 일반화 성능을 높인다. 라벨링은 실제 온셋에 ±70 ms 범위 내의 이웃 프레임까지 긍정 샘플로 확대하고, 이웃 샘플에 0.25의 가중치를 부여해 인간 주석의 불확실성을 보정한다. 손실 함수는 이진 교차 엔트로피이며, 두 태스크에 동일 가중치를 부여해 학습한다.
두 번째 단계는 사전 제공된 교사 음성의 음절·음소 지속시간 정보를 활용한 지속시간‑인포드 HMM이다. 각 음절·음소는 평균 지속시간 μ와 표준편차 σ=γ·μ (γ=0.35) 로 정의된 가우시안 분포를 전이 확률로 사용한다. 이렇게 하면 학생 음성에서 온셋이 발생할 가능성이 높은 시점을 사전에 모델링할 수 있다. HMM의 은닉 상태는 프레임 단위 후보 온셋 위치이며, 방출 확률은 CNN이 출력한 ODF 값이다. Viterbi 알고리즘의 로그 형태를 이용해 최적 경로를 탐색하고, 첫 번째와 마지막 상태는 각각 구절 시작·끝으로 고정한다. 이 과정은 음절 경계 추정 후, 각 음절 내부에서 다시 음소 경계를 추정하는 두 단계로 계층적으로 수행된다.
데이터셋은 경극 남·여 역할 유형을 포함한 95개의 독창 녹음(훈련 56, 테스트 39)으로, 구절·음절·음소 수준에서 수동 주석이 제공된다. 총 29개의 음소 클래스를 포함하며, 비음성·식별 불가 음소도 라벨링한다. 제안 방법은 동일 데이터에 대해 1‑state monophone DNN‑HSMM 기반 강제 정렬을 baseline으로 설정하고, 25 ms 내 오차를 허용한 온셋 검출 F1와 구간 정확도(정답 라벨링 구간 길이 비율)로 평가한다. 결과는 제안 방법이 온셋 F1 75.2 %·음소 구간 정확도 84.6 %를 기록해, baseline의 44.5 %·65.8 %에 비해 현저히 우수함을 보여준다. 특히 음절 수준에서도 75.8 %·60.7 %의 성능을 달성해, 계층적 추정이 전체 파이프라인에 긍정적 영향을 미침을 확인한다.
이 논문의 주요 기여는 (1) 언어 독립적인 음소 구간 분할을 위한 멀티태스크 CNN‑ODF 설계, (2) 교사 음성의 대략적 지속시간을 활용한 확률적 HMM 전이 모델링, (3) 경극 독창 음성에 특화된 공개 데이터셋 제공이다. 한계점으로는 교사와 학생 간의 음성 품질 차이, 배경 악기 존재 시 전처리 필요성, 그리고 지속시간 모델의 고정 γ값이 모든 스타일에 최적이 아닐 가능성을 들 수 있다. 향후 연구에서는 악기와의 혼합 신호에 대한 강인성 강화, 지속시간 모델의 학습 기반 적응, 그리고 음소 라벨링 없이도 완전한 비지도 학습을 목표로 할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기