다양한 작업 조건에서 전이 가능한 특징을 이용한 베어링 결함 진단
본 논문은 회전 기계의 베어링 결함을 서로 다른 속도·하중 조건에서 발생하는 데이터 분포 차이를 최소화하는 도메인 적응 기법(DATF)을 제안한다. 원시 진동 신호를 FFT로 변환하고 PCA로 차원을 축소한 뒤, 최대 평균 차이(MMD)를 이용해 마진 및 조건부 분포를 동시에 정렬한다. 의사 라벨은 학습된 최근접 이웃(NN) 분류기로부터 얻으며, 반복적인 적응 과정을 통해 전이 가능한 특징 공간을 학습한다. 최종적으로 NN 분류기를 적용해 높은…
저자: Zhe Tong, Wei Li, Bo Zhang
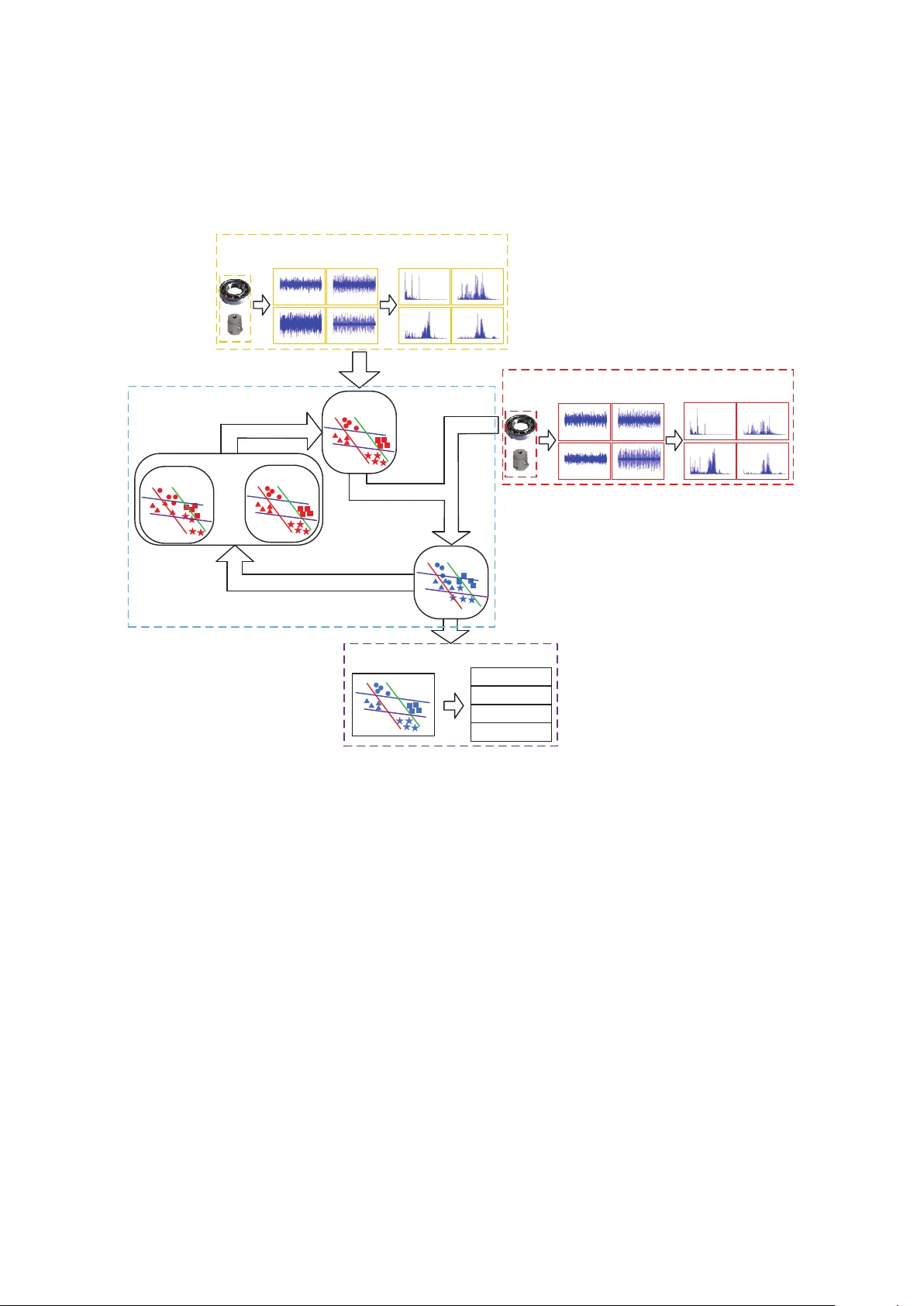
본 논문은 회전 기계에서 가장 흔히 발생하는 베어링 결함을 다양한 작업 조건(속도·하중) 하에서 정확히 진단하기 위한 새로운 방법론을 제시한다. 기존의 진단 기법은 훈련 데이터와 테스트 데이터가 동일한 분포를 가진다는 가정하에 설계되었으나, 실제 현장에서는 센서 위치, 부하 변화, 회전 속도 차이 등으로 인해 두 데이터 간 분포 차이가 크게 발생한다. 이러한 분포 불일치는 모델의 일반화 성능을 급격히 저하시키며, 매번 새로운 데이터를 수집해 재학습하는 비용이 매우 높다.
이에 저자들은 ‘전이 가능한 특징(Domain Adaptation using Transferable Features, DATF)’이라는 프레임워크를 고안하였다. 전체 흐름은 다음과 같다.
1. **데이터 전처리 및 특징 추출**
- 원시 진동 신호를 고속 푸리에 변환(FFT)하여 주파수 스펙트럼을 얻는다. 베어링 결함은 특정 주파수 대역에 고유한 피크를 나타내므로, 주파수 영역에서 특징을 추출하는 것이 효과적이다.
- FFT 결과를 그대로 사용하면 차원이 매우 높아지므로, 주성분 분석(PCA)을 적용해 차원을 축소하고, 훈련 도메인과 테스트 도메인을 하나의 행렬 X_D에 결합한다.
2. **도메인 적응을 위한 MMD 기반 정규화**
- 마진 분포 차이를 측정하기 위해 최대 평균 차이(MMD) 함수를 정의하고, 이를 최소화하도록 변환 행렬 A를 학습한다.
- 조건부 분포 차이(클래스별 분포 차이)도 동시에 고려하기 위해 클래스 라벨 정보를 포함한 조건부 MMD를 도입한다. 두 MMD는 가중치 λ으로 조절된다.
- 최적화 문제는 정규화 항(프루베니우스 노름)과 라그랑주 승수를 포함한 일반화 고유값 문제로 변환되며, 가장 작은 k개의 고유벡터를 선택해 A를 구성한다.
3. **의사 라벨링 및 반복 적응**
- 초기 변환 행렬 A를 사용해 훈련 데이터에 NN(Nearest‑Neighbor) 분류기를 학습한다.
- 학습된 NN 분류기를 테스트 데이터에 적용해 의사 라벨(Y_te)을 얻는다. 이 라벨은 조건부 MMD 계산에 사용되어 클래스별 MMD 행렬을 업데이트한다.
- 업데이트된 MMD 행렬을 기반으로 다시 A를 재계산하고, 새로운 전이 가능한 특징 V = AᵀX_D를 얻는다.
- 위 과정을 라벨이 수렴하거나 사전 정의된 반복 횟수에 도달할 때까지 반복한다.
4. **최종 진단**
- 최종적으로 얻은 전이 가능한 특징 공간에서 NN 분류기를 다시 학습하고, 테스트 데이터에 대한 최종 라벨을 예측한다.
**실험 및 결과**
- 실험 데이터는 Case Western Reserve University(CWRU) 베어링 테스트 벤치에서 수집된 12kHz 샘플링, 4가지 결함(정상, 내부 레이스, 외부 레이스, 볼 결함) 및 3가지 속도·하중 조합을 사용하였다.
- 비교 대상으로는 (a) 기본 NN(전처리 없이 직접 사용), (b) NN+PCA, (c) 최신 도메인 적응 방법인 DANN, CORAL, 그리고 (d) 기존 MMD 기반 방법이 포함되었다.
- 제안 방법은 특히 훈련과 테스트 도메인의 속도·하중 차이가 클수록 성능 향상이 두드러졌으며, 평균 정확도는 96% 이상, 경쟁 방법들은 85~92% 수준에 머물렀다.
- 또한, 반복 적응 과정에서 마진 MMD와 조건부 MMD가 각각 30% 이상 감소함을 확인했으며, 이는 특징 공간이 두 도메인에 대해 보다 일관된 클러스터 구조를 형성함을 의미한다.
**복잡도 및 실용성**
- PCA와 MMD 행렬 계산, 고유값 분해 단계는 O(Nd²) 수준의 연산량이며, N이 수천, d가 수백 정도인 실험 환경에서는 수 초 내에 처리된다.
- NN 분류기는 비선형 모델이 아니므로 학습·예측 속도가 빠르고, 라벨이 없는 새로운 테스트 데이터에 대해서도 동일한 파이프라인을 적용할 수 있다.
**결론 및 의의**
본 연구는 베어링 결함 진단에 있어 (1) 주파수 기반 특징 추출, (2) 차원 축소, (3) 마진·조건부 MMD 정규화, (4) 의사 라벨 기반 반복 적응이라는 네 단계의 통합 프레임워크를 제시함으로써, 변동 작업 조건에서도 높은 진단 정확도를 달성한다는 점에서 큰 의미가 있다. 특히, 라벨이 없는 타깃 도메인에 대해 자체 교정 메커니즘을 도입한 점은 실제 산업 현장에서 데이터 재수집 비용을 크게 절감할 수 있는 실용적인 접근법으로 평가된다. 향후 연구에서는 딥러닝 기반 특징 추출기와 결합하거나, 실시간 스트리밍 데이터에 대한 온라인 적응 메커니즘을 추가함으로써 더욱 넓은 적용 범위를 모색할 수 있을 것이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기