고속 SSC‑플립 디코딩을 통한 폴라 코드 성능 향상
본 논문은 기존 고속 SC 기반인 Fast‑SSC 알고리즘에 SC‑Flip 기법을 결합하여, 평균 실행 시간은 크게 단축하면서도 리스트 디코딩에 근접한 오류 정정 성능을 구현한 Fast‑SSC‑Flip 디코더를 제안한다.
저자: Pascal Giard, Andreas Burg
본 논문은 5G 등 차세대 이동통신에서 채택된 폴라 코드를 고속으로 디코딩하기 위한 새로운 알고리즘, Fast‑SSC‑Flip을 제안한다. 기존 폴라 코드 디코딩 방법으로는 복잡도가 낮은 SC와 그 변형인 SC‑Flip, 그리고 높은 성능을 제공하지만 복잡도가 큰 리스트 SC(SCL)가 있다. SC‑Flip은 SC에 CRC 기반 재시도 메커니즘을 추가해 리스트 디코딩에 근접한 성능을 얻지만, 실행 시간이 가변적이고 최악 지연이 크게 늘어나는 단점이 있다. 한편 Fast‑SSC는 폴라 코드를 여러 구성 코드(정보, 반복, 이중‑반복, SPC 등)로 분해하고, 각 구성에 특화된 전용 디코더를 사용해 평균 처리량을 크게 향상시킨다. 저자들은 이 두 접근법을 결합해 Fast‑SSC‑Flip을 설계하였다.
우선 Fast‑SSC의 트리 구조를 그대로 유지하면서, 각 리프 노드에서 SC‑Flip이 요구하는 “결정 LLR”을 계산하도록 알고리즘을 확장한다. 정보 노드에서는 각 비트의 절대 LLR을 그대로 사용하고, 반복 노드에서는 모든 입력 LLR의 합을 결정 LLR로 정의한다. 이중‑반복 노드에서는 짝·홀 인덱스를 각각 독립적인 반복 노드로 취급해 두 개의 결정 LLR을 얻는다. SPC 노드에서는 패리티 제약을 반영해 근사식 λₙ = |αᵢ| + s·(−1)^{p}·min|α| 를 도입했으며, 스케일링 팩터 s를 0.5~1 사이에서 조정해 성능 손실을 최소화한다.
디코딩 흐름은 첫 번째 SC‑Flip 시도와 동일하게 Fast‑SSC를 수행하면서 각 정보 비트에 대한 결정 LLR을 리스트에 저장한다. CRC 검증이 실패하면 리스트에서 가장 작은 LLR을 가진 비트를 선택해 뒤집고, 그 지점부터 디코딩을 재개한다. 최대 시도 횟수 Tₘₐₓ를 미리 정해두어 최악 지연을 제한한다.
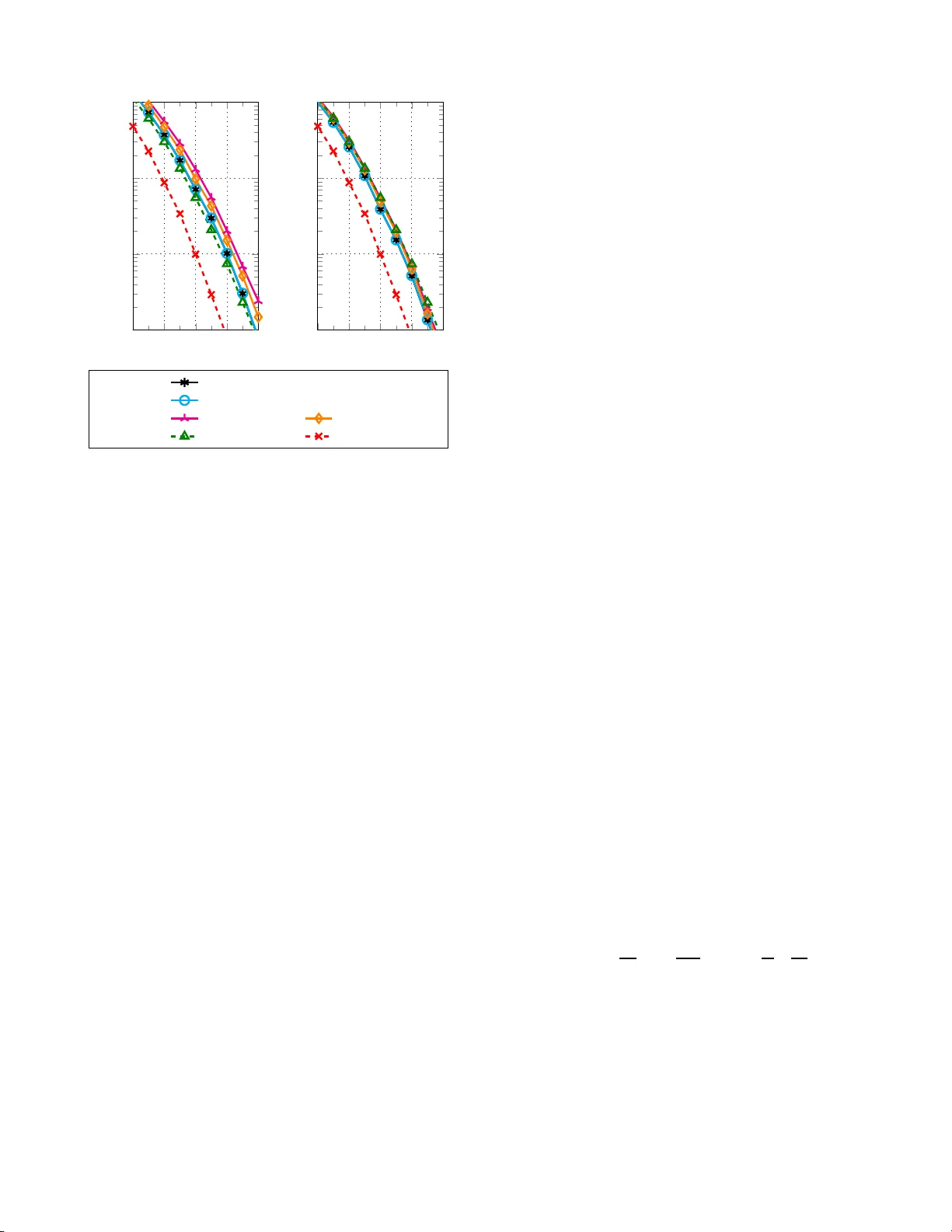
하드웨어 구현 측면에서는 Fast‑SSC의 파이프라인 구조에 결정 LLR 저장 레지스터와 비트 플립 제어 로직을 추가하는 정도로 구현이 가능하며, 면적·전력 증가가 미미하다. 실험에서는 (512, 128) 폴라 코드에 16‑bit CRC를 적용하고, Tₘₐₓ=8 및 16일 때 FER를 측정했다. 결과는 기존 SC‑Flip과 거의 동일한 FER를 보였으며, SPC 노드를 포함했을 경우 s=0.5일 때 0.1 dB 정도의 소폭 손실이 있었다. 평균 실행 시간은 기존 SC‑Flip 구현 대비 약 8~10배 빨라, 실시간 통신 시스템에 적합한 성능‑복잡도 균형을 제공한다. 또한, 리스트 디코딩(L=2, 4)과 비교했을 때 FER 차이는 0.05~0.1 dB 수준에 불과해, 복잡도와 지연을 크게 낮추면서도 높은 오류 정정 능력을 유지한다는 결론을 얻었다.
결론적으로 Fast‑SSC‑Flip은 고속 SC 기반 디코딩에 SC‑Flip의 재시도 메커니즘을 효율적으로 통합함으로써, 평균 처리량을 크게 향상시키고, 최악 지연을 제한하면서도 리스트 디코딩에 근접한 오류 정정 성능을 달성한다. 이는 차세대 무선 시스템에서 폴라 코드를 실용적으로 활용하기 위한 중요한 진전으로 평가된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기