시각적 기반 문장 표현 학습
초록
본 논문은 이미지 캡션 데이터를 활용해 문장을 시각적 의미와 연결시키는 모델을 제안한다. 캡션을 입력으로 이미지 특징을 예측하도록 학습한 BiLSTM 기반 인코더는 COCO 이미지·캡션 검색에서 높은 성능을 보이며, 학습된 문장 표현을 다양한 NLP 전이 작업에 적용했을 때 텍스트 전용 모델보다 향상된 결과를 얻는다. 또한, 시각적 정합성을 학습함으로써 단어 임베딩 자체도 개선됨을 확인한다.
상세 분석
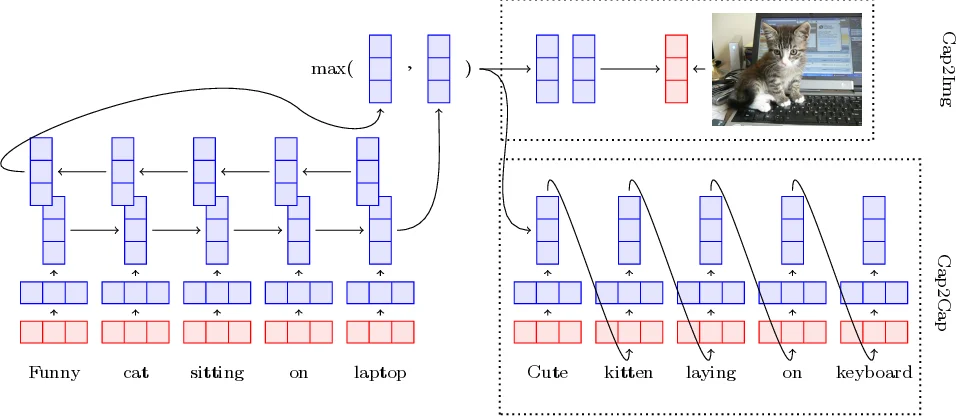
이 연구는 ‘시각적 grounding’이라는 관점을 통해 문장 수준의 의미 표현을 강화한다는 점에서 의미가 크다. 기존의 문장 임베딩은 대규모 텍스트 코퍼스에서 비지도 학습하거나, 문맥을 예측하는 방식(Skip‑Thought, InferSent 등)으로 구축되었으며, 시각적 정보와의 연계가 부족해 구체적·시각적 의미를 충분히 포착하지 못한다는 한계가 있었다. 논문은 이러한 한계를 극복하기 위해 두 단계의 학습 목표를 설계한다. 첫 번째는 캡션을 입력받아 이미지의 잠재 특징(ResNet‑101 마지막 레이어)을 직접 예측하는 Cap2Img 모델이다. 여기서는 순위 손실(rank loss)을 사용해 정답 이미지와 부정 샘플 간의 코사인 유사도를 최대화함으로써, 문장이 시각적 공간에 매핑되도록 강제한다. 두 번째는 동일 이미지에 대한 서로 다른 캡션 쌍을 이용해 한 캡션을 입력하면 다른 캡션을 생성하도록 학습하는 Cap2Cap 모델이다. 이는 직접적인 이미지 정보를 사용하지 않지만, 이미지라는 공통 매개체를 통해 간접적인 정합성을 학습한다. 마지막으로 두 목표를 동시에 최적화하는 Cap2Both 모델을 제시해 강한(perceptual)와 약한(implicit) grounding을 모두 활용한다.
모델 아키텍처는 고정된 300‑dim GloVe 임베딩을 선형 변환 U를 통해 ‘grounded word space’로 매핑한 뒤, BiLSTM(양방향, 1024 차원)으로 문장을 인코딩한다. 양방향 LSTM의 최종 은닉 상태를 요소별 최대값(max‑pool)으로 결합해 문장 벡터 h_T를 얻고, 이를 여러 비선형 투사층(ELU 활성화)으로 이미지 특징 혹은 캡션 디코더에 연결한다. 손실 함수는 이미지‑캡션 정합을 위한 마진 γ와 부정 샘플 집합 N_a를 포함한 순위 손실과, 캡션‑캡션 재구성을 위한 교차 엔트로피 손실을 각각 사용한다.
실험에서는 COCO 5K 이미지·캡션 검색에서 GroundSent‑Both가 가장 높은 Recall@1/5/10을 기록했으며, 학습된 문장 벡터를 SentEval 프레임워크에 그대로 적용해 7개의 전이 작업(SST‑2, MRPC, STS‑B, TREC 등)에서 텍스트 전용 Skip‑Thought 대비 평균 2~3%p 향상을 보였다. 특히 구체적 의미를 요구하는 이미지·텍스트 매칭 작업에서 큰 이득을 얻었으며, 추상적 의미가 중심인 텍스트 분류에서는 언어‑전용 표현과의 단순 concatenation이 최적 성능을 제공한다는 점을 확인했다.
또한, grounding 과정에서 학습된 단어 임베딩을 별도로 평가한 결과, 비grounded GloVe 대비 유사도 평가(SimLex‑999, WordSim‑353)에서 일관된 개선을 보였다. 이는 시각적 정합성을 학습함으로써 단어 수준에서도 의미적 구분력이 강화된다는 중요한 시사점을 제공한다.
한계점으로는 COCO 데이터가 주로 구체적 사물·장면을 다루기 때문에 추상적 개념에 대한 커버리지가 낮다는 점을 들 수 있다. 저자들은 이를 보완하기 위해 대규모 텍스트 코퍼스(Toronto Books)에서 사전 학습된 언어‑전용 문장 임베딩을 결합(concatenation)했으며, 향후 멀티태스크 학습으로 두 표현을 공동 최적화하는 방안을 제시한다. 전체적으로 이 논문은 시각적 grounding을 통한 문장 표현 학습이 텍스트 전용 방법에 비해 실질적인 이점을 제공함을 실험적으로 입증하고, 향후 멀티모달 언어 모델 설계에 중요한 방향성을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기