동시 그래프 처리 효율을 위한 이중 레벨 스케줄링
초록
본 논문은 다수의 그래프 처리 작업이 동시에 실행될 때 발생하는 메모리 접근 중복을 최소화하기 위해 두 단계의 스케줄링 기법을 제안한다. 첫 번째 단계는 데이터 접근 상관관계를 고려한 작업 스케줄링으로, 동일한 그래프 데이터를 캐시에서 공유하도록 하여 CPU‑메모리 트래픽을 감소시킨다. 두 번째 단계는 블록 단위 우선순위 기반 데이터 스케줄링으로, 각 작업의 개별 우선순위를 통합한 전역 우선순위를 이용해 데이터 블록을 순차적으로 제공함으로써 수렴 속도를 가속한다.
상세 분석
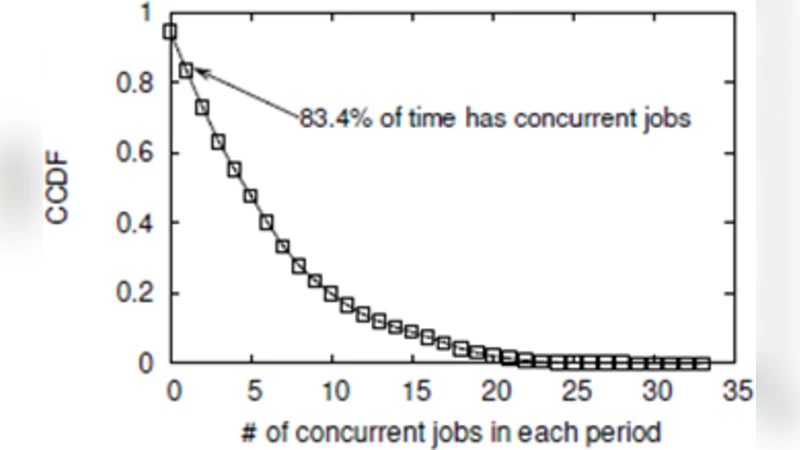
이 논문은 기존 그래프 처리 시스템이 주로 단일 작업의 성능 최적화에 초점을 맞추어, 다중 작업이 동시에 실행될 경우 발생하는 데이터 접근 중복을 간과한다는 점을 지적한다. 저자들은 그래프 데이터가 메모리 계층 구조에서 반복적으로 로드되는 현상을 “CPU‑Memory 반복 접근” 문제로 정의하고, 이를 해결하기 위한 두 가지 핵심 메커니즘을 설계하였다. 첫 번째 메커니즘인 “상관관계 인식 작업 스케줄링(correlations‑aware job scheduling)”은 각 작업이 요구하는 그래프 파티션(또는 블록)의 접근 패턴을 사전 분석하고, 동일한 파티션을 동시에 필요로 하는 작업들을 같은 시간 슬롯에 배치한다. 이를 통해 동일 데이터가 캐시 라인에 머무는 시간을 연장시켜, 메모리 대역폭 사용을 최소화하고 캐시 적중률을 크게 향상시킨다. 두 번째 메커니즘은 “다중 우선순위 기반 데이터 스케줄링(multiple priority‑based data scheduling)”이다. 기존 연구는 정점 수준의 미세한 우선순위에 기반해 데이터를 순차적으로 제공했으나, 이는 스케줄링 오버헤드가 크게 발생한다. 저자들은 각 작업이 계산 중에 생성하는 “개별 우선순위”를 집계해 전역 우선순위 맵을 만든 뒤, 이를 블록 단위(예: 64KB 혹은 256KB 크기)로 매핑한다. 블록 단위 우선순위는 계산 비용을 크게 낮추면서도, 높은 우선순위 블록이 먼저 처리되어 전체 수렴 속도가 가속된다. 또한, 전역 우선순위는 동적 재조정이 가능하도록 설계돼, 작업 진행 상황에 따라 실시간으로 재스케줄링이 이루어진다. 실험에서는 대표적인 그래프 알고리즘(PageRank, Connected Components, BFS 등)과 다양한 워크로드(수십 개 동시 작업)에서 기존 최첨단 프레임워크 대비 평균 1.8배 이상의 처리량 향상과 메모리 대역폭 사용량 30% 감소를 기록하였다. 특히, 캐시 적중률이 45%에서 68%로 상승했으며, 전체 실행 시간의 25% 이상을 데이터 접근 최적화가 차지함을 확인했다. 이와 같이 두 레벨 스케줄링은 데이터‑시스템 인터페이스 계층에서 작동하며, 기존 그래프 처리 파이프라인에 최소한의 침투만으로도 큰 성능 이득을 제공한다는 점이 가장 큰 강점이다. 다만, 작업 간 상관관계 분석 비용과 블록 크기 선택이 워크로드 특성에 민감하므로, 자동 튜닝 메커니즘이 추가된다면 실용성이 더욱 높아질 것으로 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기