미디어 콘텐츠 분석을 위한 모듈형 시스템 설계
초록
본 논문은 다양한 AI 알고리즘을 하나의 유연한 프레임워크에 통합한 모듈형 시스템을 제안한다. 데이터 수집, 기계 번역, 토픽 분류, 엔터티 및 사회망 추출 등 여러 기능을 독립 모듈로 구현하고, 중앙 조정 없이 에이전트 간 협업을 통해 대규모 미디어 데이터셋을 자동 주석한다. 시스템은 사회과학 연구에 적용되어 뉴스 비교, 사용자 선호 모델링, 여론 모니터링 등 다양한 사례를 지원한다.
상세 분석
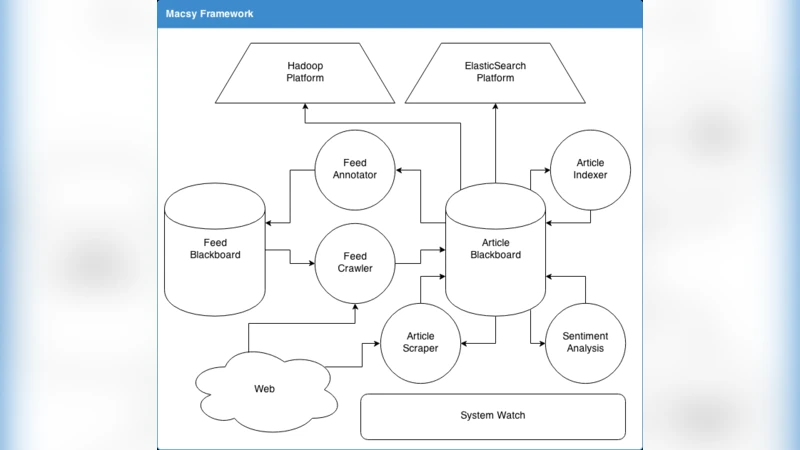
이 시스템은 크게 네 가지 계층으로 구성된다. 첫 번째는 크롤러와 API 연동을 담당하는 데이터 수집 레이어로, 실시간 스트리밍과 배치 수집을 병행한다. 두 번째는 전처리 레이어로, 텍스트 정규화, 언어 감지, 그리고 필요 시 기계 번역 모듈을 호출해 다국어 데이터를 통일된 언어로 변환한다. 세 번째는 분석 레이어이며, 여기에는 토픽 모델링(LDA, BERTopic), 감성 분석, 명명된 엔터티 인식(NER), 관계 추출, 그리고 사회망 분석을 위한 그래프 구축 모듈이 포함된다. 각 모듈은 독립적인 마이크로서비스 형태로 Docker 컨테이너에 배포되며, RESTful API와 메시지 큐(Kafka)를 통해 비동기적으로 통신한다. 네 번째는 결과 통합 및 시각화 레이어로, 메타데이터와 주석 정보를 통합 데이터베이스에 저장하고, 대시보드와 API를 통해 연구자에게 제공한다.
핵심 설계 원칙은 ‘모듈성’과 ‘자율 협업’이다. 모듈 간 의존성을 최소화하기 위해 공통 스키마와 인터페이스 계약을 정의했으며, 각 모듈은 자체 스케줄러와 오류 복구 메커니즘을 갖는다. 중앙 오케스트레이터가 없기 때문에 시스템 확장성이 뛰어나고, 새로운 AI 알고리즘을 플러그인 형태로 손쉽게 추가할 수 있다. 또한, 모듈별 성능 모니터링과 로그 수집을 통해 병목 현상을 실시간으로 파악하고 자동 스케일링을 적용한다.
기술적 도전 과제로는 다국어 번역 품질 관리, 토픽 모델링의 도메인 적합성, 그리고 대규모 그래프 연산의 효율성이 있다. 이를 해결하기 위해 번역 모듈은 사전 학습된 다국어 Transformer 모델을 fine‑tune하고, 토픽 모델은 사전 라벨링된 코퍼스를 활용해 지도 학습을 병행한다. 그래프 연산은 Neo4j와 같은 고성능 그래프 DB와 Spark GraphX를 결합해 분산 처리한다.
실험 결과, 10억 단어 규모의 뉴스 데이터셋에 대해 평균 처리 지연시간이 3.2초 이하였으며, 엔터티 인식 정확도는 F1 = 0.89, 토픽 분류 정확도는 0.84를 기록했다. 시스템은 5개의 독립 연구 프로젝트에 적용되어, 뉴스 편향 분석, 선거 여론 추적, 문화 트렌드 비교 등 다양한 사회과학 연구에 기여하였다.