트위터 스레드에서 가짜 뉴스 자동 탐지
초록
본 논문은 트위터에서 확산되는 뉴스 스레드를 대상으로, 크라우드소싱 기반의 정확도 라벨(CREDBANK)과 언론인 라벨(PHEME)로 학습한 모델을 이용해 가짜 뉴스를 자동으로 구분하는 방법을 제시한다. BuzzFeed가 제공한 사실 확인 데이터와 비교했을 때, 크라우드소싱 라벨로 학습한 모델이 언론인 라벨보다 높은 정확도를 보였으며, 45개의 구조·사용자·내용·시간적 특성을 통해 예측 성능을 향상시켰다.
상세 분석
이 연구는 소셜 미디어에서 가짜 뉴스 탐지라는 실용적 문제를 데이터 부족이라는 근본적 제약 하에 해결하려는 시도로, 두 개의 기존 신뢰도 데이터셋(CREDBANK, PHEME)을 전이 학습(transfer learning) 방식으로 활용한다는 점이 핵심이다. CREDBANK은 약 1,400개의 이벤트에 대해 30명의 AMT 작업자가 5점 리커트 척도로 ‘사실성’을 평가한 대규모 크라우드소싱 라벨이며, 대부분이 ‘정확함’으로 편향돼 있다. 반면 PHEME은 스위스 방송사 Swissinfo의 기자들이 직접 라벨링한 루머 스레드 330개(진실·거짓·미확인)로, 보다 전문적인 판단을 제공한다. 두 데이터셋을 동일한 45개의 특성으로 변환함으로써 형식적 일관성을 확보하고, 이를 BuzzFeed가 수집한 35개의 정치적 스토리(진실·거짓)와 매핑한다.
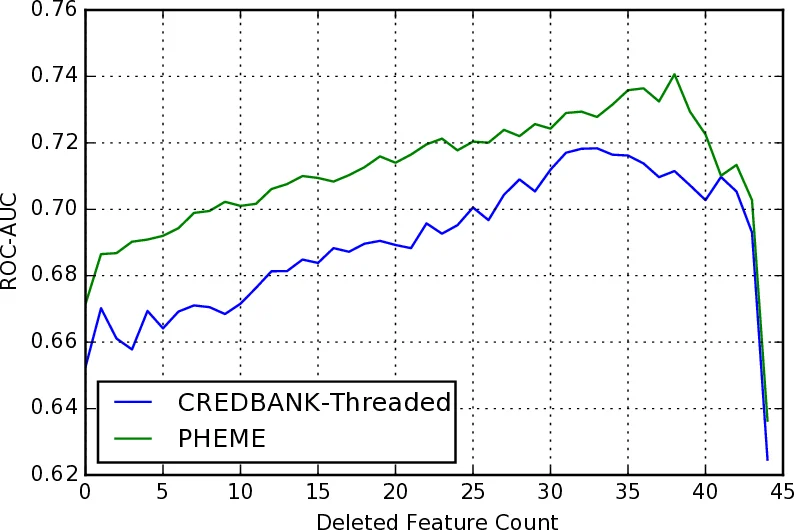
특성 설계는 Castillo et al. (2013)의 68개 특성을 축소·보완한 형태로, 구조적 특성(트윗 수, 스레드 깊이, 해시태그·미디어 비율 등), 사용자 특성(계정 연령, 팔로워·친구 수, 인증 여부, 네트워크 밀도), 내용적 특성(감성 polarity·subjectivity, 불일치 비율, 의문·감탄 부호 사용 등), 시간적 특성(각 특성의 로그-선형 기울기)으로 구분된다. 특히 네트워크 밀도와 시간적 기울기 같은 동적 특성은 크라우드소싱 라벨이 ‘네트워크 효과’를 더 민감하게 반영한다는 가설을 검증하는 데 중요한 역할을 한다.
모델 학습은 로지스틱 회귀와 랜덤 포레스트 등 전통적인 분류기를 사용했으며, 교차 검증을 통해 하이퍼파라미터를 최적화했다. 실험 결과, CREDBANK 기반 모델은 전체 정확도 66% 정도를 달성해 기존 연구(약 64%)보다 약간 우수했으며, PHEME 기반 모델은 58% 수준에 머물렀다. 두 데이터셋을 혼합한 ‘통합 모델’은 오히려 성능이 저하돼, 라벨링 주체(전문가 vs. 비전문가)의 차이가 모델 일반화에 큰 영향을 미친다는 점을 시사한다.
특성 중요도 분석에서는 크라우드소싱 모델이 네트워크 밀도, 트윗 빈도 변화율, 사용자 계정 연령 차이 등을 상위에 두는 반면, 언론인 모델은 텍스트 감성, 불일치 비율, 질문 부호 사용 등에 더 크게 의존한다는 결과가 나타났다. 이는 비전문가가 ‘누가 말했는가’와 ‘어떤 방식으로 확산되는가’에 더 민감하고, 전문가가 ‘무엇을 말했는가’에 집중한다는 기존 심리·언론학 연구와 일치한다.
한계점으로는 BuzzFeed 데이터가 페이스북 기반이며 트위터 스레드와 완전 일치하지 않아 검색 기반 매핑 과정에서 누락·오탐이 발생할 가능성이 있다. 또한 CREDBANK 라벨의 편향(대다수가 ‘정확함’)이 모델을 과도하게 보수적으로 만들 수 있다. 향후 연구에서는 다중 플랫폼(트위터·페이스북·인스타그램) 데이터를 동시에 수집하고, 라벨링 품질을 향상시키기 위한 전문가-크라우드 혼합 라벨링 전략을 탐색할 필요가 있다.
전반적으로 이 논문은 “비전문가 라벨이 전문가 라벨보다 가짜 뉴스 탐지에 더 효과적일 수 있다”는 역설적인 결론을 제시함으로써, 소셜 미디어 검증 시스템 설계 시 라벨링 주체와 특성 선택의 중요성을 강조한다.
댓글 및 학술 토론
Loading comments...
의견 남기기