대화형 보상 학습으로 강화학습 기반 업무형 챗봇 성능 향상
초록
본 논문은 사용자 피드백 없이도 대화 성공 여부를 판단할 수 있는 보상 함수를 적대적 학습으로 구축하고, 이를 정책 그래디언트 강화학습에 적용해 업무형 대화 시스템의 성공률을 크게 향상시킨다.
상세 분석
이 연구는 두 개의 신경망, 즉 대화 생성기(Generator)와 보상 추정기(Discriminator)를 동시에 학습시키는 적대적 프레임워크를 제안한다. 생성기는 LSTM 기반의 대화 상태 추적기와 슬롯‑값 베리핑 트래커, 그리고 정책 네트워크로 구성되며, 매 턴마다 사용자 입력(다이얼로그 액트)과 이전 시스템 응답을 인코딩해 대화 상태 sₖ를 업데이트한다. 슬롯‑별 확률 분포 P(lₘₖ)는 단일 히든 레이어 MLP로 계산되고, 정책 네트워크는 현재 상태 sₖ, 슬롯‑값 분포 vₖ, 외부 검색 결과 요약 Eₖ를 입력으로 받아 다음 시스템 액트 aₖ의 확률을 출력한다.
보상 추정기인 판별자는 양방향 LSTM을 사용해 전체 대화 시퀀스를 인코딩한다. 각 턴의 입력은 사용자 액트 Uₖ, 시스템 액트 Aₖ, 그리고 검색 결과 요약 Eₖ를 연결한 벡터이며, LSTM 출력 hₖ를 다양한 풀링 기법(마지막 상태, max‑pool, avg‑pool, attention) 중 하나로 결합해 대화 레벨 표현 d를 만든다. 최종적으로 시그모이드 레이어를 통해 d가 ‘성공적인 대화’일 확률 D(d)를 산출한다.
생성기의 파라미터 θ_G는 REINFORCE 기반 정책 그래디언트로 최적화된다. 에피소드 종료 시점에만 보상 r_K = D(d) 가 주어지며, 이를 할인 인자 γ 로 각 턴에 전파해 Rₖ를 계산한다. 베이스라인 V(sₖ)는 별도의 피드포워드 네트워크로 추정해 분산을 감소시킨다. 판별기 θ_D는 인간이 만든 성공 대화와 생성기가 만든 대화를 각각 양성·음성 샘플로 사용해 교차 엔트로피 손실을 최소화한다.
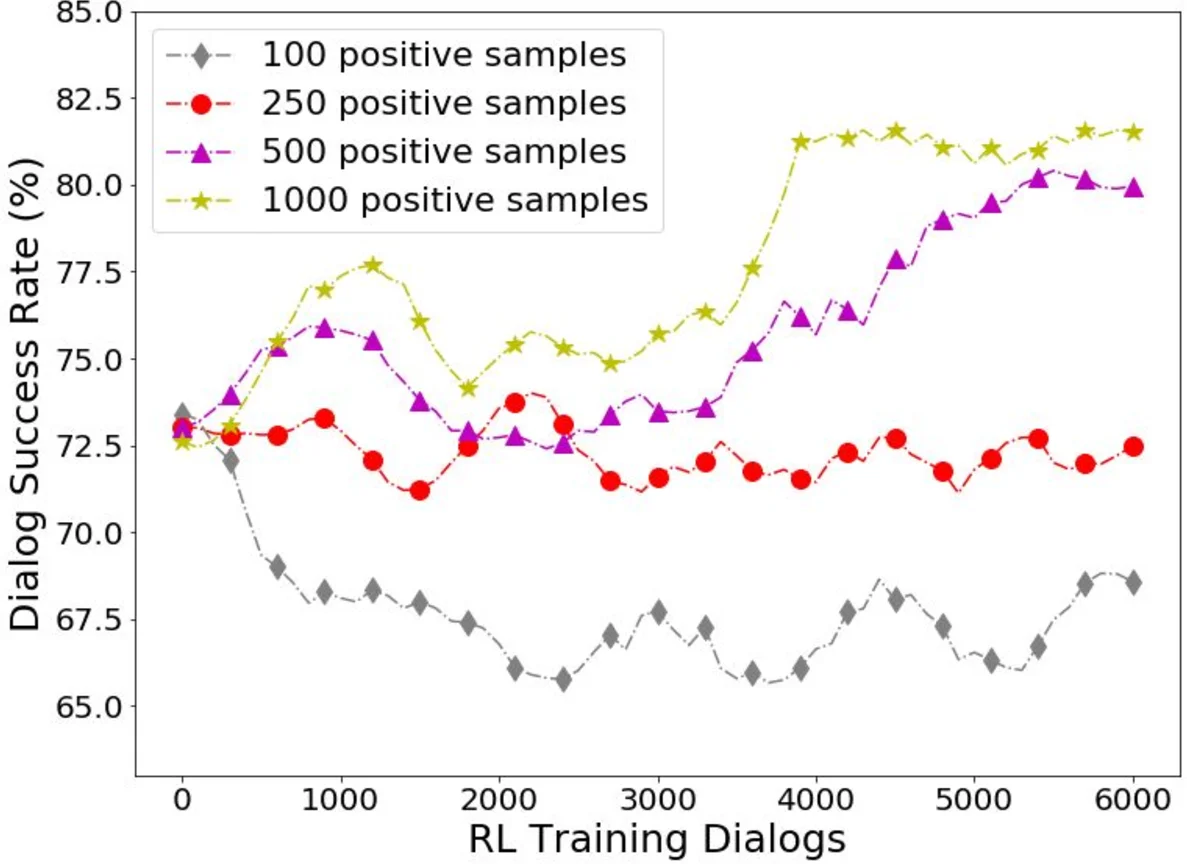
핵심 기여는 (1) 명시적 사용자 평점 없이도 대화 성공을 판단하는 보상 함수를 자동 학습한다는 점, (2) 이 보상을 정책 학습에 직접 활용해 샘플 효율성을 크게 개선한다는 점, (3) 온라인 학습 시 발생할 수 있는 공변량 이동(covariate shift) 문제를 부분적인 사용자 피드백으로 보정하는 전략을 제시한다는 점이다. 실험은 DSTC2 레스토랑 도메인에서 수행했으며, 제안 방법은 기존 강화학습 기반 하이브리드 모델 및 설계된 보상 함수를 사용하는 베이스라인보다 높은 성공률을 기록했다. 특히, 제한된 라벨링 데이터(성공 대화)만으로도 충분히 학습이 가능함을 보였으며, 판별기의 풀링 방식에 따라 성능 차이가 있음을 분석했다.
댓글 및 학술 토론
Loading comments...
의견 남기기