감정 인식을 위한 트랜스포머 기반 컨텍스트 모델
본 논문은 OMG‑Emotion 챌린지를 위해 제안된 UMONS 팀의 시스템을 소개한다. 발화의 각 구간에 대한 각성(arousal)과 가치(valence)를 예측할 때, 앞뒤 발화라는 비디오 전체 컨텍스트를 활용하는 트랜스포머 인코더 기반의 단계적 구조를 설계하였다. 언어, 시각, 음성 3가지 모달리티를 각각 독립적으로 특징을 추출한 뒤, 자기‑주의(self‑attention)를 이용해 비디오 수준의 컨텍스트를 반영하고, 최종적으로 다중모달 …
저자: Jean-Benoit Delbrouck
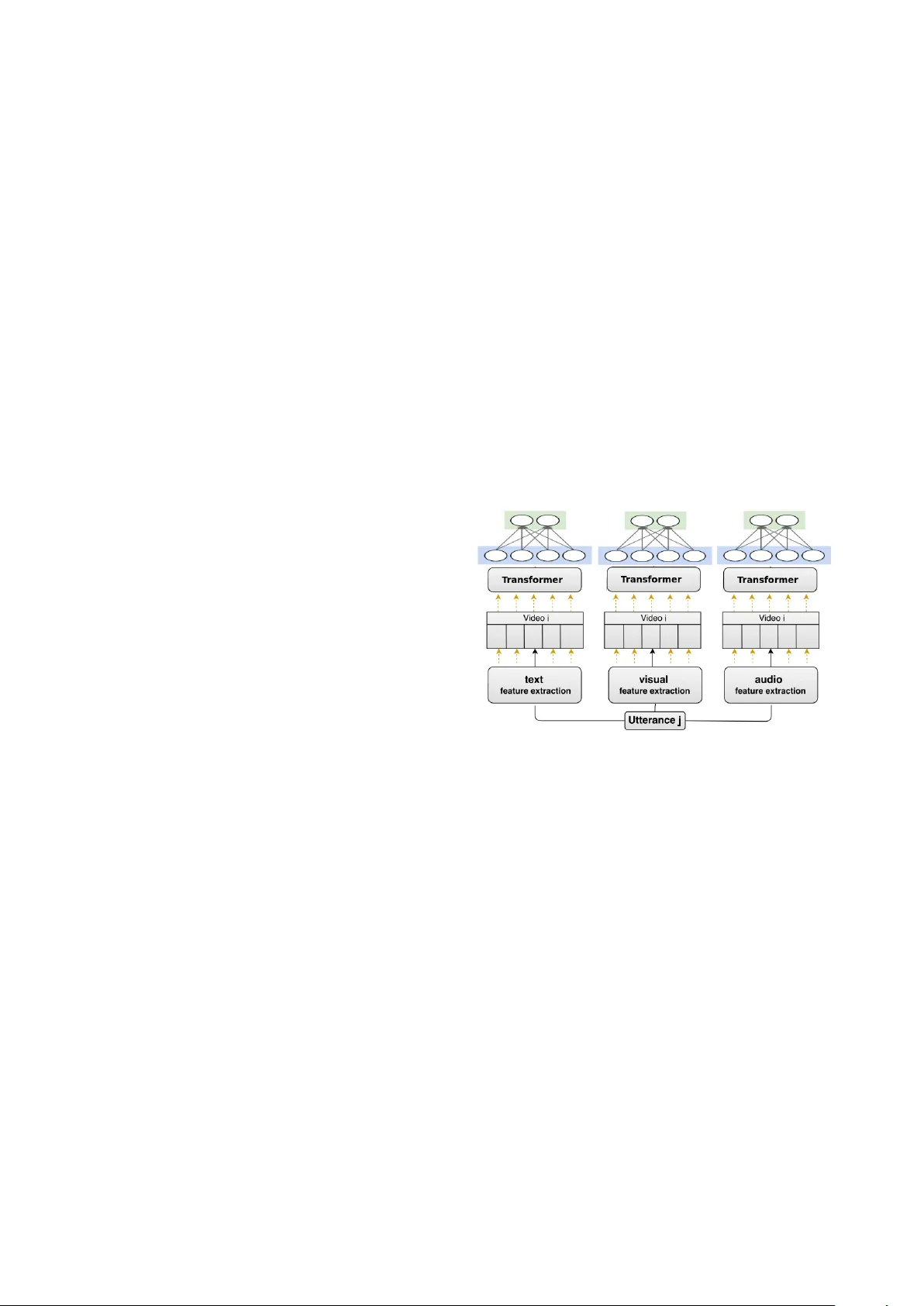
본 논문은 OMG‑Emotion 챌린지를 위한 UMONS 팀의 솔루션을 상세히 기술한다. 데이터는 1분 길이의 감정 행동을 담은 비디오 컬렉션으로, 각 비디오는 여러 발화(utterance)로 나뉘며 각 발화마다 인간 주관자가 연속적으로 시청하면서 각성(arousal)과 가치(valence)를 라벨링한다. 학습 데이터는 231개의 비디오(2442 발화)와 검증 데이터는 60개의 비디오(617 발화)로 구성된다.
시스템은 크게 세 단계로 나뉜다. 첫 번째 단계는 “컨텍스트‑프리 단일모달” 단계로, 언어, 시각, 음성 각각에 대해 발화 단위 특징을 추출한다. 언어는 Word2Vec 기반 임베딩을 50단어 윈도우로 구성하고, 단일 CNN(커널 크기 3,4,2, 각각 30,30,60개의 피처 맵)과 ReLU, 맥스‑풀링을 거쳐 120차원 피처를 만든다. 시각은 32프레임을 32×32 해상도로 샘플링하고, 3D‑CNN(두 개의 5×5×5 컨볼루션, 뒤이어 4×4×4와 3×3×3 풀링)으로 128차원 피처를 추출한다. 음성은 16 kHz 샘플링된 오디오에 OpenSmile을 적용해 6373개의 저수준 특성을 얻고, 일변량 회귀 검정으로 상위 80개를 선택, 최종 121차원 피처를 만든다. 각 모달리티는 별도의 전용 Fully‑Connected 레이어(
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기