기술적 분석과 유전 알고리즘을 활용한 외환 예측 모델 설계
초록
**
본 논문은 EUR/USD 시계열에 대해 6가지 기술적 지표를 기반으로 특징을 생성하고, 유전 알고리즘(GA)으로 최적의 특징·파라미터 조합을 탐색한다. 선택된 특징을 입력으로 Naive Bayes 분류기를 학습시켜 시계열의 상승·하락을 이진 예측하고, 교차 검증 및 별도 검증 세트를 통해 성능을 평가한다. GA‑최적화 전후 ROI가 0.43 %에서 10.29 %로 크게 향상되었으며, t‑SNE 시각화를 통해 결정 경계와 특징 구조를 시각적으로 확인한다.
**
상세 분석
**
이 연구는 외환 시장에서 기술적 분석(Technical Analysis, TA)이 제공하는 다양한 변환 지표를 머신러닝 모델에 적용하는 방법론적 가능성을 탐색한다. 저자는 RSI, CCI, MACD, ROC, Stochastic Oscillator, ATR 등 6가지 대표적인 TA 지표를 사용했으며, 각 지표마다 윈도우 길이·가중치 등 조정 가능한 파라미터가 존재한다. 이러한 파라미터 공간은 10^21 이상의 조합을 만들 수 있어 전수 탐색이 불가능하므로, 저자는 변이·교배·선택 과정을 갖는 유전 알고리즘(GA)을 도입하였다. 특히, 기존 GA에 ‘랜덤 이민자(Random Immigrants)’와 ‘하이퍼 변이(Hyper‑mutation)’ 메커니즘을 추가해 탐색 초기에 다양성을 확보하고, 수렴 정체 시 변이율을 일시적으로 상승시켜 지역 최적에 머무르는 위험을 완화한다.
GA는 각 개체를 ‘특징 선택 + 파라미터 설정’의 비트/실수 벡터로 정의하고, 적합도 함수는 교차 검증(CV) 기반의 분류 정확도와 ROI(투자 수익률)를 복합적으로 고려한다. 최적화 과정에서 선택된 특징 집합은 중복되는 이동 평균 기반 지표를 제거하고, 정보량이 높은 변환만을 남겨 Naive Bayes(NB) 분류기의 독립성 가정을 어느 정도 만족시킨다. NB는 가우시안 분포를 가정한 조건부 확률 모델로, 학습·예측 비용이 O(N·C) 수준으로 경량이며 과적합에 강한 특성을 가진다.
실험 데이터는 2013‑01‑01부터 2017‑03‑09까지의 EUR/USD 시계열을 1시간 간격으로 샘플링한 것으로, 전체 데이터를 70 % 훈련·30 % 검증으로 나누고, 훈련 단계에서 5‑fold CV를 수행한다. 목표 변수는 현재 시점의 종가 변화가 양(1)인지 음(0)인지를 나타내는 단순 이진 라벨이며, 예측 확률이 사전 정의된 ‘거부 임계값(P_rejection)’ 이하이면 거래를 회피하도록 설계했다.
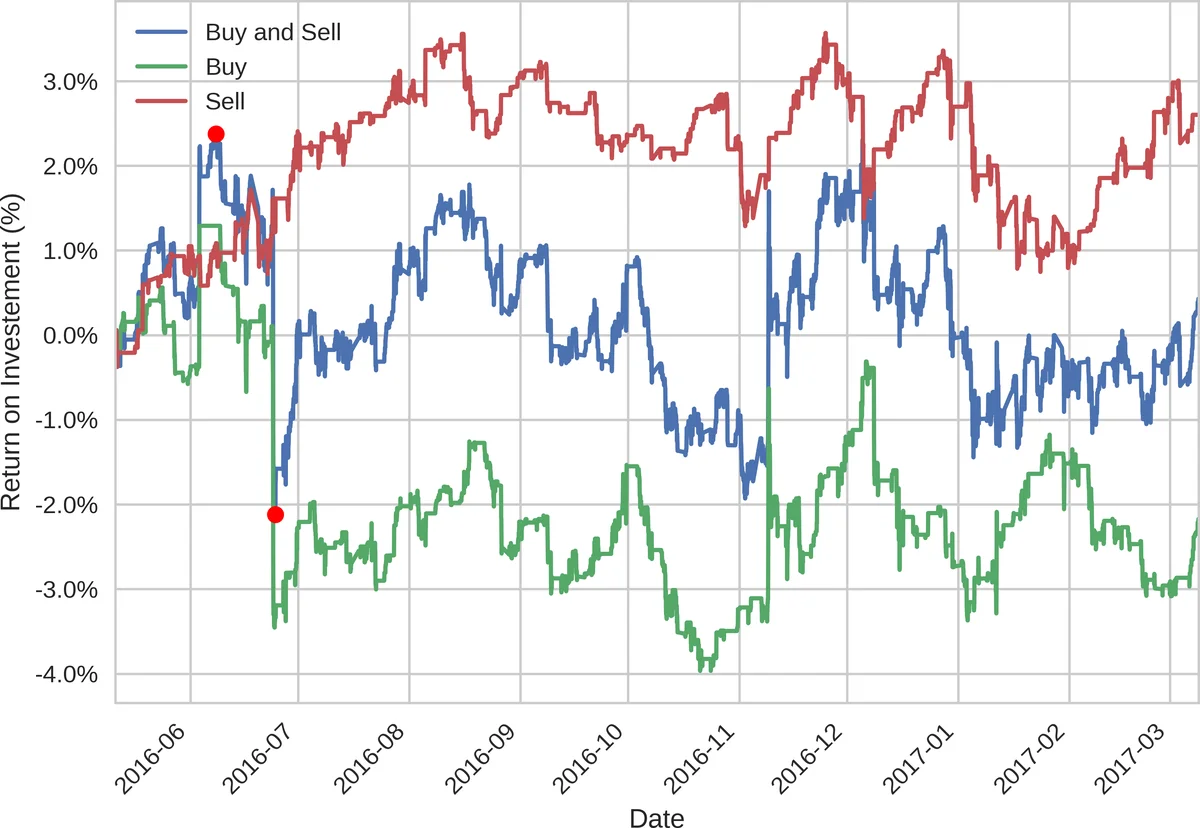
핵심 결과는 GA‑최적화 전 NB 모델이 검증 세트에서 0.43 %의 ROI를 기록한 반면, 최적화 후 10.29 %로 약 24배 상승했다는 점이다. 또한, t‑SNE(다차원 임베딩) 시각화를 통해 최적화된 특징 공간이 명확히 구분되는 클러스터 구조를 형성함을 확인했으며, 이는 모델이 실제 시장 패턴을 어느 정도 포착했음을 시사한다.
하지만 몇 가지 한계도 존재한다. 첫째, 라벨 정의가 단순히 가격 상승·하락을 기준으로 하여 거래 비용·슬리피지·레버리지 등을 반영하지 않아 실제 운용 시 ROI가 과대평가될 가능성이 있다. 둘째, NB의 독립성 가정이 TA 지표 간 상관관계를 완전히 제거하지 못해 모델 편향이 남을 수 있다. 셋째, GA 파라미터(인구 규모, 세대 수, 변이·교배 확률 등)와 실험 재현성을 위한 상세 설정이 논문에 충분히 기술되지 않아 외부 검증이 어려운 점이 있다. 마지막으로, 검증 기간이 2017년까지이며, 최근의 고빈도·알고리즘 트레이딩 환경을 반영하지 못한다는 점도 고려해야 한다.
전반적으로 이 연구는 “기술적 분석 → 특징 선택 → 경량 분류기”라는 파이프라인을 체계화하고, GA와 t‑SNE를 결합해 모델 해석성을 높인 점에서 학술적·실무적 의의가 크다. 향후 연구에서는 다중 자산·다중 시간대 확장, 거래 비용 모델링, 딥러닝 기반 대체 모델과의 비교, 그리고 GA의 메타‑최적화 등을 통해 실용성을 더욱 강화할 수 있을 것이다.
**
댓글 및 학술 토론
Loading comments...
의견 남기기