컨볼루션 신경망, 음성 분리에서 재귀 모델을 능가한다
본 논문은 기존의 BLSTM 기반 음성 분리 모델을 대체할 수 있는 dilated convolutional neural network(CNN) 구조를 제안한다. 제안 모델은 파라미터 수를 10배 이상 줄이면서도 동일하거나 더 높은 SDR 성능을 달성하고, 긴 시퀀스, 간헐적 잡음, 그리고 실제 환경에서 녹음된 RealTalkLibri 데이터셋과 같은 새로운 도메인에 대해 뛰어난 일반화 능력을 보인다.
저자: Shariq Mobin, Brian Cheung, Bruno Olshausen
본 논문은 음성 신호가 섞인 복합 음향 환경에서 개별 화자를 정확히 분리하는 문제를 다루며, 기존에 높은 성능을 보였던 양방향 LSTM(BLSTM) 기반 모델을 대체할 수 있는 dilated convolutional neural network(CNN) 구조를 제안한다. 연구 배경으로는 인간 청각이 복잡한 음향 신호를 효과적으로 분리하는 메커니즘을 모방하고자 하는 Computational Auditory Scene Analysis(CASA)와, 최근 Deep Clustering(DPCL) 및 Deep Attractor Network(DANet)와 같은 end‑to‑end 학습 기반 접근법이 소개된다. 그러나 이러한 재귀 모델은 파라미터가 많고, 장시간 시퀀스나 실제 환경에서의 일반화에 한계가 있다.
제안된 모델은 13개의 dilated convolution 레이어로 구성되며, 두 개의 스택으로 나뉘어 각 레이어의 dilation factor가 2배씩 증가한다. 이를 통해 수용 영역이 기하급수적으로 확장되어 긴 시간 의존성을 손실 없이 포착한다. 각 레이어는 3×3 필터와 batch normalization, residual connection을 적용해 학습 안정성을 확보한다. 고정 레이턴시(≈127 타임포인트, 약 1 초)를 갖도록 설계했으며, 이는 실시간 스트리밍 처리에 적합하도록 만든다.
입력은 8 kHz로 다운샘플링된 음성 파형을 STFT(32 ms 윈도우, 8 ms 홉)로 변환한 로그‑멜 스펙트로그램이다. 이 스펙트로그램 X는 네트워크를 통해 K‑차원(20) 임베딩 V로 매핑되고, L2 정규화를 거쳐 단위 구면에 위치한다. 학습 단계에서는 이상적인 이진 마스크(IBM)를 사용해 각 타임‑주파수 bin을 스피커 라벨에 할당하고, 이를 기반으로 attractor 포인트 A_c를 계산한다. 테스트 시에는 K‑means 클러스터링으로 attractor를 추정하고, 임베딩과 attractor 간 내적을 통해 마스크 M을 구한다. 마스크는 max 함수를 사용해 소프트맥스보다 더 명확한 구분을 만든다. 최종적으로 마스크와 원본 스펙트로그램을 곱해 복원된 스펙트로그램을 얻고, 위상은 혼합 신호의 위상을 그대로 사용해 역 STFT을 수행한다. 손실 함수는 복원된 스펙트로그램과 정답 스펙트로그램 사이의 MSE이며, 이는 SDR(신호 대 왜곡 비율) 향상과 직접 연결된다.
데이터셋은 세 가지로 구성된다. 첫 번째는 WSJ0 훈련 스피커를 사용해 만든 기존의 2‑스피커 혼합 데이터이며, 테스트는 동일한 설정의 WSJ0 테스트 셋을 사용한다. 두 번째는 LibriSpeech의 40명 미사용 스피커를 이용한 테스트 셋이다. 세 번째이자 가장 중요한 것은 RealTalkLibri(RTL) 데이터셋이다. 이는 LibriSpeech 테스트 클린 파트를 기반으로, 두 스피커의 음성을 각각 다른 거리·각도로 실제 방에서 녹음한 9시간 분량의 데이터이며, 각 스피커의 단독 녹음과 혼합 녹음을 모두 제공한다. 따라서 실제 환경에서의 파라미터 변동, 반향, 잡음 등을 포함한 현실적인 조건을 평가할 수 있다.
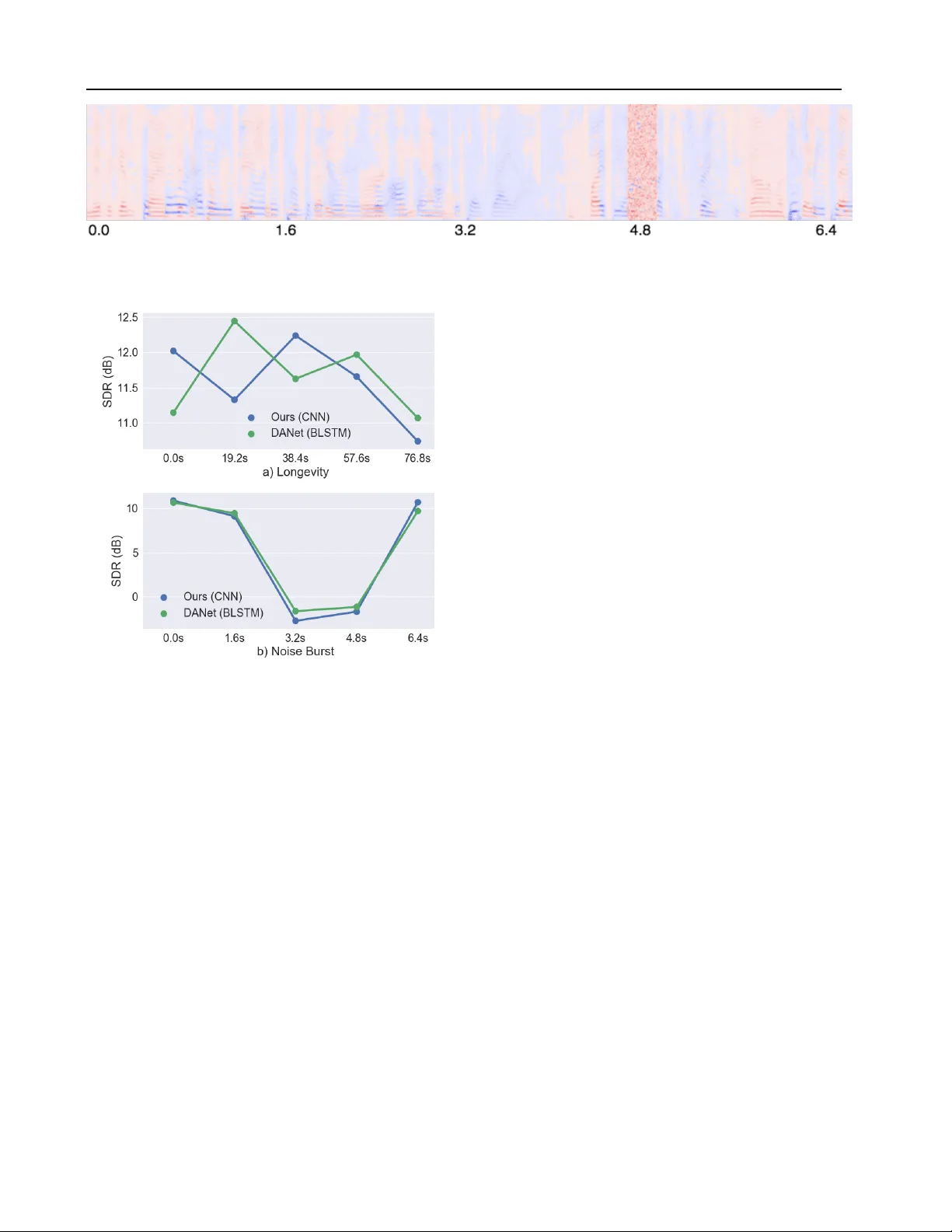
실험 결과는 다음과 같다. WSJ0 테스트에서 제안된 dilated CNN은 파라미터 0.6 M(≈10배 적음)으로 DANet(≈6 M)보다 0.3 dB 높은 SDR(≈10.8 dB vs 10.5 dB)을 기록했다. 긴 시퀀스(>10 s)와 간헐적 백색 잡음이 삽입된 경우에도 CNN은 성능 저하가 BLSTM보다 현저히 적었으며, 특히 잡음 비율이 30%일 때 CNN은 1.2 dB, BLSTM은 3.5 dB 정도의 차이를 보였다. RealTalkLibri에서는 환경 변화에 대한 민감도가 크게 드러났는데, BLSTM 기반 모델은 평균 SDR이 6.2 dB까지 떨어지는 반면, CNN은 7.0 dB 수준을 유지했다. 이는 CNN이 주파수‑시간 구조적 패턴을 보다 일반화 가능하게 학습함을 의미한다. 또한, 고정 레이턴시 설계 덕분에 실시간 처리 시 평균 지연이 120 ms 이하로 유지되어 실시간 통신·보조 청각 기기에 적용 가능함을 확인했다.
코드와 데이터는 모두 공개되어 있어 재현성이 높으며, 향후 데이터 증강 없이도 아키텍처 선택만으로 일반화 성능을 크게 향상시킬 수 있음을 시사한다. 논문은 음성 분리 분야에서 CNN 기반 접근법이 재귀 모델을 대체할 수 있는 실용적이고 효율적인 대안임을 입증한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기