대규모 단백질 패밀리 고품질 정렬을 위한 QuickProbs 2
초록
QuickProbs 2는 확률적 모델에 기반한 새로운 MSA 알고리즘으로, 열‑지향 정제와 선택적 일관성 기법을 도입해 수백 개에서 수천 개에 이르는 대규모 단백질 군에서도 높은 정렬 정확도와 빠른 실행 시간을 제공한다. 기존의 정제·일관성 기법이 대규모 데이터에서 효과가 떨어지는 문제를 해결하고, GPU·CPU 병렬화를 활용해 Clustal Ω와 동등한 속도를 유지한다.
상세 분석
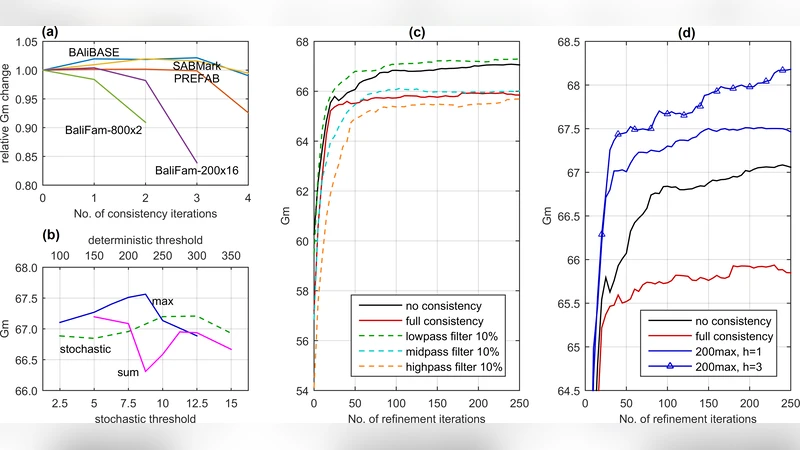
본 논문은 다중 서열 정렬(MSA) 분야에서 가장 큰 난제 중 하나인 ‘시퀀스 수 폭증’에 대응하기 위해 QuickProbs 2라는 새로운 파이프라인을 제시한다. 핵심은 두 가지 혁신적 기법, 즉 **열‑지향 정제(column‑oriented refinement)**와 **선택적 일관성(selective consistency)**이다. 기존의 정제 방식은 무작위 혹은 트리‑가이드 방식으로, 대규모 데이터에서는 거의 갭‑전용 열이 생성되지 않아 정렬을 재구성할 여지가 적었다. QuickProbs 2는 갭이 하나라도 존재하는 열을 무작위로 선택해 그 열을 기준으로 정렬을 두 프로파일로 분할한다. 이렇게 하면 최소 하나의 프로파일이 반드시 짧아지므로, 재정렬 시 새로운 매칭이 발생할 확률이 크게 증가한다. 또한 정렬 길이가 감소하지 않으면 수용하지 않는 ‘정렬 길이 비증가’ 기준을 도입해 수렴 속도를 높였다.
일관성 단계는 모든 쌍의 후방 확률 행렬을 다른 서열을 통해 완화(relax)하는데, 전통적인 일관성은 O(k³n³) 복잡도로 수백 개 이상의 서열에서는 오히려 잡음이 신호를 압도한다는 것이 실험적으로 확인되었다. 이를 해결하기 위해 선택적 일관성을 설계하였다. 서열 x와 y 사이의 행렬 S_xy를 다른 서열 z를 통해 완화할지 여부를 거리 함수 f(d_xz, d_yz)와 임계값 T에 따라 결정한다. 거리 측정은 (1) 정렬 단계 I에서 얻은 점수 기반 거리, (2) 가이드 트리에서의 최소 서브트리 노드 수(트리‑가이드 거리) 두 가지를 사용한다. 저자들은 트리‑가이드 거리를 기반으로 한 임계값 필터링이 가장 좋은 성능을 보인다고 보고한다. 선택적 일관성은 실제로 수행되는 완화 횟수를 크게 줄여 O(k³n³) 연산을 실질적으로 O(β·k³n³) 수준으로 감소시키며, 동시에 행렬 신호 강도를 보정하기 위해 h_xy 계수를 도입해 작은 집합과 큰 집합 간의 스케일 차이를 보정한다.
알고리즘 구현 측면에서는 GPU 가속을 위한 OpenCL 기반 설계가 핵심이다. 후방 확률 행렬을 희소 형태(희소 계수 β<1)로 저장하고, 행렬 연산을 GPU에서 병렬 처리함으로써 기존 MSAProbs 대비 10배 이상 빠른 속도를 달성한다. 또한 메모리 사용량을 조절하기 위해 사용자가 희소 계수를 직접 지정할 수 있게 하여, 수십만 서열까지도 메모리 제한 내에서 실행 가능하도록 설계하였다.
평가에서는 BALiBASE, PREFAB, OXBench, SABmark, HomFam, BaliFam 등 6개의 벤치마크를 활용하였다. 작은 집합(≤50개)에서는 기존 일관성 기반 툴(MSAProbs, ProbCons 등)보다 우수한 SP·TC 점수를 기록했으며, 1001000개 규모에서는 Clustal Ω를 능가하는 정확도를 보였다. 특히 1000개 이상인 BaliFam에서는 일관성 없이도 높은 정확도를 유지했으며, 선택적 일관성을 적용했을 때 약 23%의 추가 향상이 관찰되었다. 실행 시간 측면에서는 GPU 환경에서 Clustal Ω와 비슷한 수준을 유지하면서, 전통적인 일관성 기반 툴보다 수십 배 빠른 성능을 보였다.
종합적으로 QuickProbs 2는 정제와 일관성의 효율적 재설계, GPU 기반 고속 병렬 처리, 메모리 효율성라는 세 축을 동시에 만족시켜, “few‑to‑hundreds” 뿐 아니라 “hundreds‑to‑thousands” 규모의 단백질 패밀리 정렬에 실용적인 솔루션을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기