Transformer 기반 중국어 음성인식에서 모델링 단위 비교
본 논문은 Transformer 기반의 sequence‑to‑sequence 모델을 이용해 중국어 음성인식에서 다섯 가지 모델링 단위(CI‑phoneme, 음절, 단어, 서브워드, 문자)를 비교한다. 실험 결과, 사전이 필요 없는 문자 단위가 가장 낮은 26.64% CER를 기록하며 기존 최고 기록(28.0%)보다 4.8% 상대 개선하였다.
저자: Shiyu Zhou, Linhao Dong, Shuang Xu
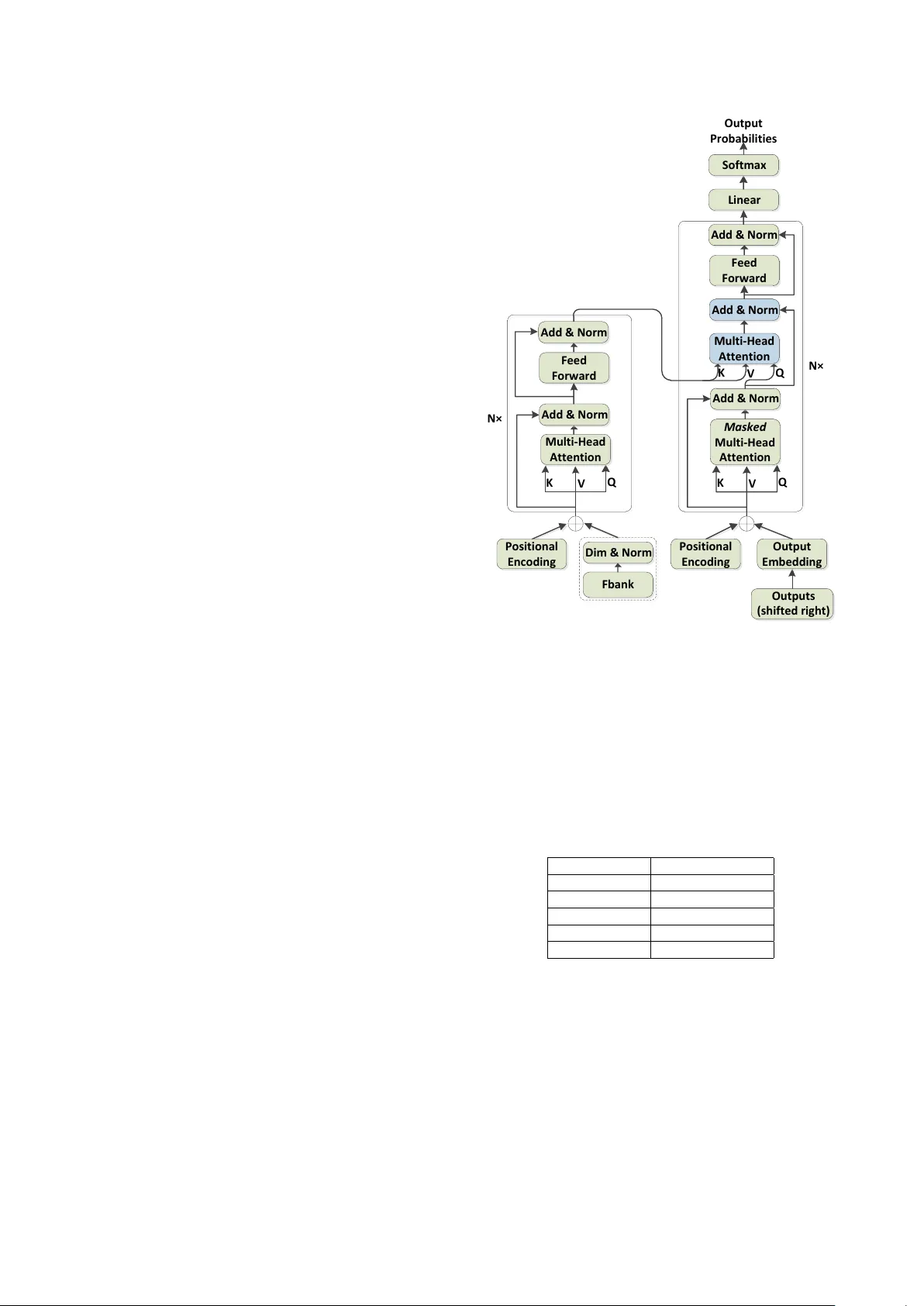
본 논문은 “A Comparison of Modeling Units in Sequence‑to‑Sequence Speech Recognition with the Transformer on Mandarin Chinese”라는 제목 아래, Mandarin Chinese 음성인식에서 모델링 단위가 인식 성능에 미치는 영향을 체계적으로 조사한다. 전통적인 ASR 시스템은 음향 모델(AM), 발음 모델(PM), 언어 모델(LM)을 별도로 학습하고, CD‑state·CD‑phoneme과 같은 복합 단위를 사용한다. 그러나 최근 sequence‑to‑sequence attention 기반 모델은 이 세 부분을 하나의 신경망으로 통합하면서, 특히 영어에서는 grapheme(문자) 단위가 phoneme(음소)보다 우수한 성능을 보인 사례가 보고되었다. 이러한 배경에서 저자들은 Mandarin Chinese에서도 동일한 현상이 나타나는지 검증하고자 한다.
연구에서는 다섯 가지 모델링 단위를 선정하였다. (1) CI‑phoneme: 122개의 출력 클래스(음소 + 특수 토큰)이며, GMM‑HMM 기반 정렬을 통해 라벨을 생성한다. (2) 음절(시니인): 1 388개의 클래스이며, CI‑phoneme 정렬을 사전으로 변환해 얻는다. (3) 단어: 훈련 텍스트에 등장하는 모든 단어를 수집해 28 444개의 클래스(특수 토큰 포함)로 구성한다. (4) 서브워드: Byte‑Pair Encoding(BPE) 방식을 적용해 5 000번 병합 후 11 039개의 토큰을 만든다. (5) 문자: 한자와 영문을 모두 포함해 3 900개의 클래스(특수 토큰 포함)로 정의한다.
모델 아키텍처는 Vaswani et al.가 제안한 Transformer를 그대로 사용한다. 인코더와 디코더는 각각 N=6개의 레이어, 헤드 수 h=8(D512‑H8) 또는 h=16(D1024‑H16)이며, 차원 d_model은 512 또는 1024이다. 입력은 80차원 log‑Mel filterbank에 3프레임을 스택하고 30 ms 간격으로 다운샘플링한 뒤, 선형 변환과 레이어 정규화를 통해 d_model에 맞춘다. 위치 인코딩을 추가해 순서 정보를 제공한다. 학습은 Adam 옵티마이저와 4 000~12 000 스텝의 warm‑up 스케줄, 라벨 스무딩(ε=0.1) 및 체크포인트 평균(마지막 20개)으로 진행한다. 데이터는 HKUST 150시간 대화식 전화 음성 코퍼스를 사용하며, 속도 변조(0.9, 1.1)를 통해 데이터 양을 확대한다.
실험 결과는 표 5에 정리된다. CI‑phoneme와 음절은 각각 대형 모델(D1024‑H16)에서 30.65%·28.77% CER를 기록했다. 사전이 필요 없는 단위 중에서는 단어가 27.42%, 서브워드가 27.26% CER로 개선되었으며, 가장 뛰어난 성능은 문자 단위가 26.64% CER를 달성한 것이다. 이는 기존 CTC‑attention + RNN‑LM 기반 모델이 기록한 28.0% CER보다 4.8% 상대적으로 낮은 수치이며, 또한 9‑layer LSTM‑HMM 기반의 deep multidimensional residual learning(30.79% CER)보다 13.4% 상대 개선된 결과다. 파라미터 수는 모델마다 차이가 있었지만, 문자 모델이 가장 효율적인 성능‑파라미터 비율을 보였다.
논문은 이러한 결과를 바탕으로 다음과 같은 시사점을 제시한다. 첫째, Mandarin Chinese에서도 복잡한 발음 사전을 사용하지 않고 문자 수준의 직접 출력만으로도 최고 수준의 인식 정확도를 달성할 수 있다. 이는 시스템 설계와 유지보수 비용을 크게 절감한다는 점에서 실용적이다. 둘째, 서브워드가 단어보다 좋은 이유는 어휘 규모를 크게 줄이면서도 OOV 문제를 완화하기 때문이다. 그러나 서브워드가 문자보다 성능이 낮은 것은 토큰 길이가 길어져 학습 난이도가 증가하기 때문으로 해석된다. 셋째, 대규모 데이터셋에서 서브워드와 문자 간 성능 차이가 어떻게 변할지 추가 연구가 필요하다. 마지막으로, Transformer 기반의 end‑to‑end ASR이 기존 hybrid LSTM‑HMM 시스템을 능가한다는 점을 재확인하였다.
결론적으로, 본 연구는 Mandarin Chinese 음성인식에서 모델링 단위 선택이 성능에 결정적인 영향을 미치며, 특히 사전이 필요 없는 문자 단위가 가장 우수하고 실용적인 선택임을 입증한다. 향후 연구에서는 더 큰 코퍼스와 다양한 언어에 대한 확장, 그리고 언어 모델과의 통합을 통해 더욱 향상된 성능을 기대할 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기