가변 정밀도 활용 CNN 가속기 Loom
초록
Loom은 가중치와 활성값의 비트 정밀도를 동적으로 조절해 연산량을 감소시키는 비직렬 CNN 가속기이다. 컨볼루션 레이어에서는 가중치·활성값 정밀도의 곱에 비례해 실행 시간이 단축되고, 완전 연결 레이어에서는 가중치 정밀도에 비례해 가속된다. 128 × 16‑bit MAC와 동등한 대역폭을 유지하면서 평균 4.38배 성능·3.54배 에너지 효율 향상을 달성한다.
상세 분석
Loom(LM)은 모바일 SoC와 같이 메모리 대역폭과 면적이 제한된 환경을 목표로 설계된 CNN 추론 가속기이다. 핵심 아이디어는 가중치와 활성값을 비트‑시리얼(bit‑serial) 방식으로 처리함으로써 실제 사용되는 비트 수만큼만 메모리에서 읽어들이고, 연산 유닛은 1‑bit 곱셈을 대규모 병렬로 수행한다는 점이다. 컨볼루션 레이어에서는 동일한 가중치 비트를 여러 윈도우에 재사용하고, 활성값 비트는 Pₐ 사이클에 걸쳐 순차적으로 곱해진다. 따라서 전체 연산 사이클은 Pₐ × P𝑤 로 감소한다. 완전 연결 레이어는 가중치 재사용이 거의 없지만, 가중치 비트당 16 사이클 동안 16개의 활성값 비트를 곱해 가중치 비트당 16배의 활용률을 확보한다. 이 구조는 고정 16‑bit MAC와 비교했을 때, 가중치·활성값 정밀도가 16비트 이하인 경우 각각 256/(Pₐ·P𝑤)와 16/P𝑤 배의 속도 향상을 제공한다.
정밀도 프로파일링은 각 레이어별 최적 비트를 사전에 분석해 적용한다. 활성값은 런타임에 Lascorz 등(2017)의 동적 트리밍 기법을 이용해 서브‑레이어 혹은 입력 채널 단위까지 세밀하게 조정한다. 가중치 역시 필터 단위, 심지어 비트 수준까지 가변 정밀도를 지원해 메모리 압축 효과를 극대화한다.
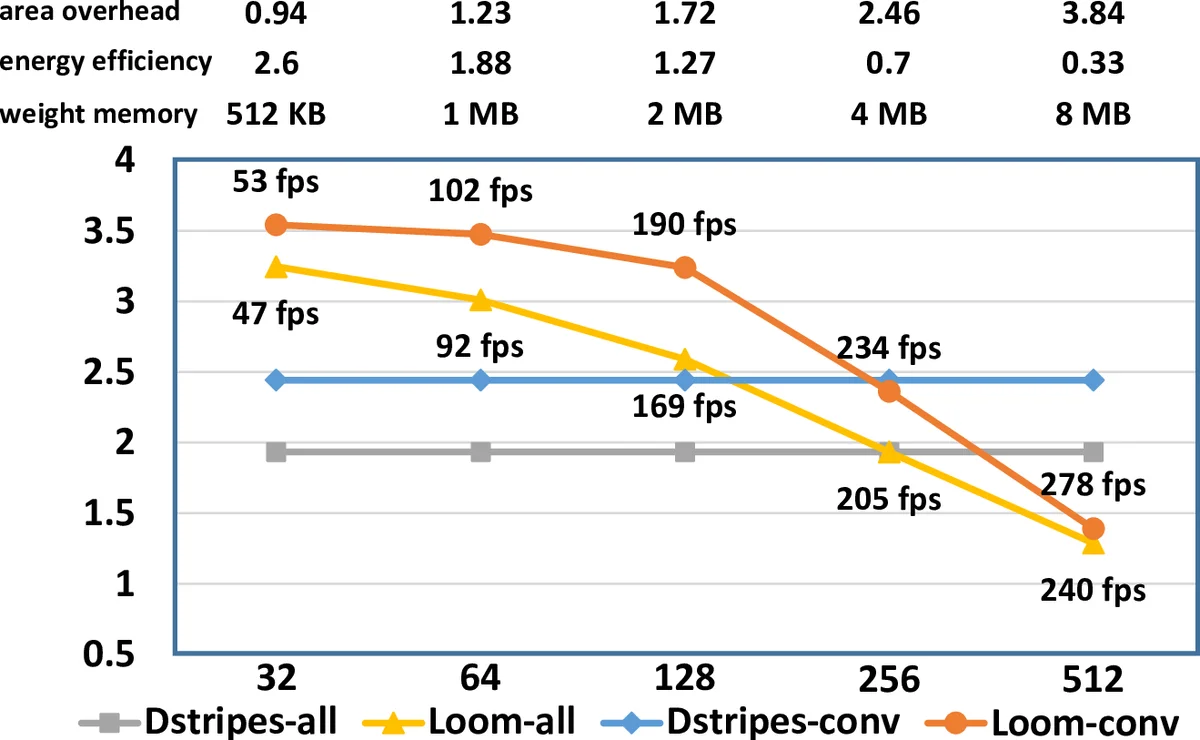
하드웨어 구현에서는 2 K × 16 SIP(Serial Inner‑Product) 배열을 사용한다. 각 SIP는 16개의 1‑bit 가중치 레지스터와 16개의 1‑bit 활성값 입력을 받아 AND 연산 후 16‑입력 가산기로 부분 합산한다. SIP 행은 16‑bit 가중치 버스를, 열은 256‑bit 활성값 버스를 공유해 대역폭을 최소화한다. 비트‑시리얼 처리 덕분에 가중치와 활성값을 비트‑인터리브 방식으로 저장·전송할 수 있어 메모리 풋프린트가 16‑bit 고정형 대비 최대 16배 감소한다.
실험에서는 AlexNet, NiN, GoogLeNet, VGG‑19 등 7개 이미지 분류 모델을 대상으로 평가하였다. 동일한 피크 연산량(128 × 16‑bit MAC)에서 평균 컨볼루션 레이어는 3.25배, 완전 연결 레이어는 1.74배, 전체 레이어는 3.19배의 성능 향상을 보였으며, 에너지 효율은 각각 2.63배, 1.41배, 2.59배였다. 정확도 손실 없이 4.38배 가속을 달성했으며, 1% 정확도 감소를 허용하면 3.57배 성능·2.87배 에너지 효율을 추가로 얻을 수 있다. 2‑bit·4‑bit 변형을 조사한 결과, 2‑bit/사이클 설계가 가장 높은 에너지 효율을 제공한다.
요약하면, Loom은 비트‑시리얼 병렬성을 활용해 정밀도 가변성을 하드웨어 수준에서 자연스럽게 지원함으로써, 메모리 대역폭·면적 제한이 있는 모바일 환경에서도 고정‑정밀도 가속기 대비 현저한 성능·에너지 이점을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기