데이터 이동 최소화를 위한 과학 워크플로우의 교차 계층 최적화
초록
**
본 논문은 HPC 환경에서 과학 워크플로우가 겪는 I/O 병목을 해소하기 위해, 저장소, 컴파일러, 런타임 스케줄러를 연계한 교차 계층 솔루션을 제안한다. 위치‑인식 파일 시스템 확장, 작업 및 데이터 메타데이터 힌트 제공, 그리고 데이터 이동 비용을 고려한 휴리스틱·프리액티브 스케줄링을 통해 데이터 로컬리티를 극대화한다.
**
상세 분석
**
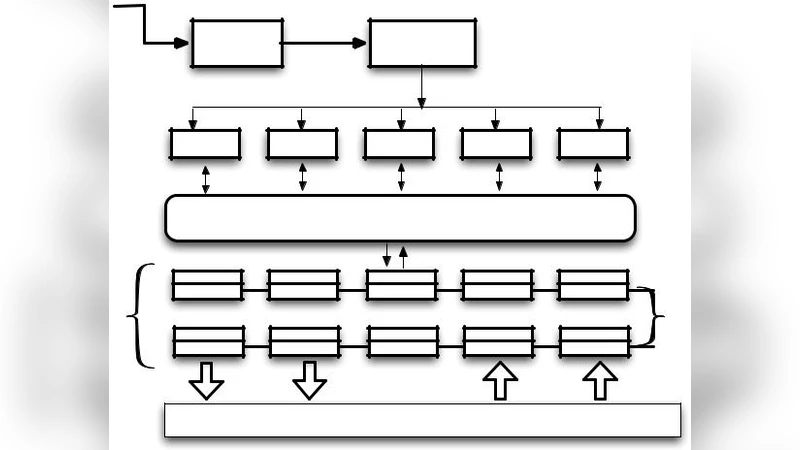
논문은 기존 과학 워크플로우 시스템이 Lustre·PVFS·Ceph 등 원격 병렬 파일 시스템에 의존하면서 발생하는 “데이터 이동 비용”을 핵심 문제로 규정한다. 특히 CPU 성능은 지속적으로 향상되는 반면, 저장소·네트워크 대역폭은 상대적으로 뒤처져 전체 실행 시간이 I/O에 의해 제한되는 현상이 심화되고 있다. 이를 해결하기 위해 저자들은 “Compute‑on‑Data‑Path” 개념을 도입하고, 데이터가 실제 연산이 일어나는 노드 근처에 존재하도록 하는 로컬리티 기반 접근법을 제시한다.
핵심 기여는 세 가지 레이어를 동시에 다루는 교차 계층 설계에 있다. 첫째, Hercules 기반의 인메모리 파일 시스템에 위치‑인식 API를 추가한다. OPEN 호출에 S_LOC 플래그를 부여해 파일 생성 위치를 명시하거나, 파일의 위치 메타데이터를 xattr 형태로 저장·조회할 수 있게 함으로써, 애플리케이션이나 런타임이 파일의 물리적 위치를 직접 제어하도록 만든다. 둘째, Swift/T 컴파일러에 @size, @task, @compute‑complexity, @input‑output‑ratio 등 새로운 어노테이션을 도입한다. 이러한 힌트는 파일 크기, 작업의 프로세스 수, 입력 데이터 크기에 비례하는 연산량 등을 정량화하여 컴파일 단계에서 DAG에 풍부한 메타데이터를 부착한다. 이는 정적 분석을 통해 작업의 최조 시작 시점을 예측하고, 데이터 흐름을 사전에 파악하는 데 활용된다. 셋째, 런타임 스케줄러는 두 단계의 휴리스틱을 적용한다. (1) 현재 준비된 작업에 대해 “최장 경로 길이”와 “데이터 이동 비용”을 결합한 점수를 계산해 우선순위를 정하고, (2) 프리액티브 스케줄링을 통해 아직 입력이 완전히 준비되지 않은 작업도 미리 할당한다. 프리액티브 단계에서 스케줄러는 파일 시스템에 파이프라인 전송을 요청해, 작업 실행 시점에 데이터가 이미 목표 노드에 존재하도록 만든다.
이러한 설계는 기존에 파일 시스템이 단순히 데이터 저장소 역할만 수행하던 한계를 넘어, 워크플로우 엔진과 파일 시스템이 상호 피드백을 주고받으며 동적으로 최적화될 수 있는 구조를 만든다. 특히 데이터 위치를 명시적으로 지정하고, 작업 메타데이터를 풍부하게 제공함으로써 스케줄러가 “데이터 이동 최소화 + 연산 부하 균형”이라는 두 목표를 동시에 고려할 수 있게 된다. 실험적 검증은 논문에 상세히 제시되지 않았지만, 제안된 프레임워크는 HPC 클러스터에서 데이터 집약적 파이프라인(예: 유전체 분석, 기후 모델링 등)의 I/O 병목을 크게 완화할 잠재력을 가진다.
**
댓글 및 학술 토론
Loading comments...
의견 남기기