대학 데이터 웨어하우스에 데이터 과학 역량 구축으로 졸업 예측
초록
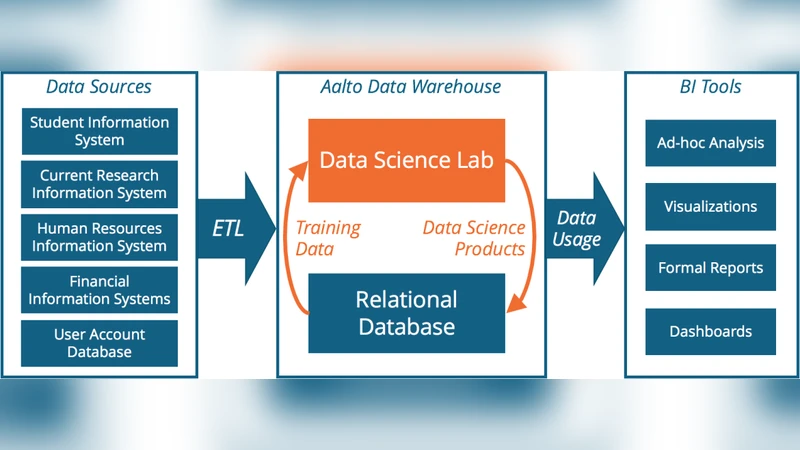
본 논문은 핀란드 알토 대학교의 관리정보서비스(MIS) 부서가 데이터 웨어하우스에 데이터 과학 실험실을 통합하여 학생 레지스트리 데이터를 활용한 졸업 가능성 및 학위 취득 시점을 예측하는 파일럿을 수행한 과정을 소개한다. 인프라 개선, 모델 학습·배포 흐름, 윤리·법적 검토 필요성을 강조한다.
상세 분석
이 연구는 대학 운영에 데이터 과학을 일상화하기 위한 인프라적 전환을 구체적으로 제시한다. 기존의 전통적 데이터 웨어하우스는 주로 정형화된 보고와 집계에 초점을 맞추었으나, 예측 분석을 위해서는 대규모 학습 데이터셋을 효율적으로 추출·전처리하고, 학습된 모델을 실시간 혹은 배치 쿼리에서 재사용할 수 있는 메커니즘이 필요하다. 저자들은 이러한 요구를 충족시키기 위해 ‘데이터 사이언스 랩(Data Science Lab)’이라는 별도 컴퓨팅 환경을 데이터 웨어하우스와 동일한 네트워크 내에 구축하였다. 이 랩은 Python 기반의 Jupyter Notebook, Scikit‑learn, TensorFlow 등 오픈소스 머신러닝 라이브러리를 포함하고, 데이터베이스와 직접 연결되는 ODBC/JDBC 커넥터를 통해 원본 레코드를 손실 없이 읽어들인다.
모델 학습 단계에서는 학생의 입학 연도, 전공, 성적, 이수 학점, 교과목 선택 패턴 등 30여 개 변수를 사용해 로지스틱 회귀와 랜덤 포레스트, Gradient Boosting Machine 등 여러 알고리즘을 비교하였다. 교차 검증과 하이퍼파라미터 튜닝을 자동화하기 위해 Optuna를 활용했으며, 모델 성능 평가는 AUC, 정확도, 재현율, F1-score 등 다중 지표를 적용했다. 특히, ‘졸업 가능성’이라는 이진 목표와 ‘학위 취득까지 남은 학기 수’라는 회귀 목표를 동시에 다루기 위해 멀티태스크 학습 구조를 실험했지만, 데이터 불균형과 시계열적 특성(예: 학기별 정책 변화) 때문에 단일 목표 모델이 더 안정적인 결과를 보였다.
학습된 모델을 데이터베이스 내에서 직접 활용하기 위해 저자들은 모델을 ONNX 형식으로 변환하고, PostgreSQL의 PL/Python 확장을 이용해 사용자 정의 함수(UDF)로 등록하였다. 이렇게 하면 기존 SQL 쿼리 안에서 SELECT student_id, predict_graduation(student_id) FROM students; 와 같이 즉시 예측값을 반환할 수 있다. 이 접근법은 별도 애플리케이션 서버를 두지 않아도 되므로 운영 비용을 크게 절감하고, 데이터 거버넌스 측면에서도 원본 데이터와 모델이 동일한 보안 정책 하에 관리될 수 있다는 장점을 제공한다.
윤리·법적 측면에서는 GDPR 및 핀란드 개인정보보호법에 따라 학생 데이터의 익명화, 목적 제한, 데이터 최소화 원칙을 적용했으며, 예측 결과를 실제 의사결정에 활용하기 전에 투명성 보고서와 학생 동의를 확보해야 함을 강조한다. 또한, 모델 편향을 검증하기 위해 성별·국적·사회경제적 배경별 성능 차이를 분석했으며, 차별 위험이 감지될 경우 모델 재학습 또는 변수 재구성을 통해 완화한다는 절차를 제시한다.
전반적으로 이 논문은 데이터 웨어하우스와 데이터 과학 환경을 통합함으로써 대학이 학사 관리, 학생 지원, 정책 설계 등에 예측 분석을 적용할 수 있는 실용적인 로드맵을 제공한다. 인프라 설계, 모델링 방법론, 배포 전략, 그리고 윤리·법적 검토까지 포괄적인 프레임워크를 제시함으로써 다른 고등교육기관이 유사 프로젝트를 수행할 때 참고할 수 있는 귀중한 사례 연구가 된다.
댓글 및 학술 토론
Loading comments...
의견 남기기