딥 바이아핀 어텐션으로 강화한 공동 언급 탐지·클러스터링 기반 신경 코어퍼런스 해결
초록
본 논문은 엔드‑투‑엔드 코어퍼런스 모델에 두 가지 개선을 도입한다. 첫째, 전통적인 피드포워드 방식 대신 바이아핀 어텐션을 사용해 후보 언급 간의 선후 관계 점수를 계산한다. 둘째, 언급 탐지 손실과 클러스터링 로그우도 손실을 동시에 최적화함으로써 언급 검출 정확도와 클러스터링 성능을 동시에 향상시킨다. CoNLL‑2012 영어 테스트에서 단일 모델 67.8 %·5‑모델 앙상블 69.2 %의 최신 F1 점수를 기록한다.
상세 분석
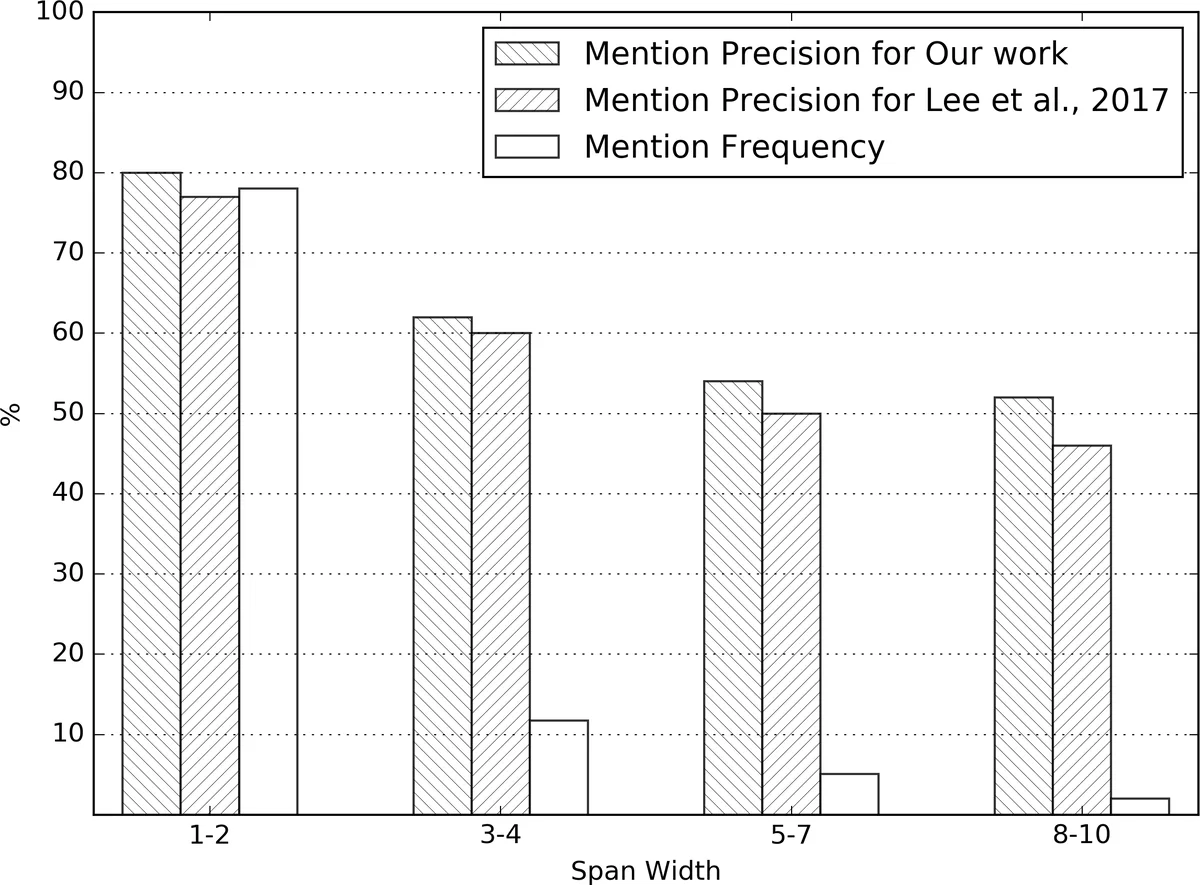
이 연구는 기존 Lee et al. (2017) 모델이 제시한 “모든 스팬을 후보로 고려하고, 전방향 스팬에 대한 선후 관계를 학습한다”는 기본 구조를 유지하면서, 두 가지 핵심적인 설계 변화를 통해 성능을 끌어올렸다. 첫 번째 변화는 antecedent scoring 단계에서 단순한 피드포워드 네트워크 대신 Deep Biaffine Attention을 적용한 점이다. 바이아핀 구조는 두 스팬의 표현을 각각 선형 변환한 뒤, 외적(outer product) 형태의 상호작용을 통해 호환성을 직접 모델링한다. 이는 기존 방식이 놓치기 쉬운 복합적인 관계 정보를 포착하게 해 주며, 특히 “현재 스팬이 antecedent를 가질 확률”을 별도의 bias term(v|bi)으로 명시함으로써 전반적인 점수 분포를 보다 정교하게 만든다. 두 번째 변화는 학습 목표에 있다. 기존 모델은 gold antecedent에 대한 marginal likelihood만을 최대화했으며, 언급 탐지는 간접적인 distant supervision에 의존했다. 저자들은 명시적인 언급 탐지 손실 Ldetect를 도입해 sigmoid(m(i))와 실제 언급 여부(y_i)를 직접 비교함으로써, 언급 검출 정확도를 별도로 향상시켰다. 최종 손실은 λdetect 로 가중된 Ldetect와 전체 스팬에 대한 Lcluster의 가중합으로 정의되며, 이는 언급 검출과 클러스터링 사이의 상호 보완 효과를 촉진한다. 실험에서는 λdetect=0.1이 최적임을 확인했으며, 스팬 프루닝 비율 λ=0.4와 최대 스팬 길이 10, 최대 antecedent 250개라는 설정을 유지하면서도 연산 효율성을 크게 해치지 않았다. Ablation 실험 결과, 바이아핀 어텐션을 제거하거나 언급 탐지 손실을 제외하면 각각 약 0.3~0.4 %의 F1 감소가 발생했으며, 두 요소를 동시에 사용할 때 가장 큰 성능 향상이 관찰되었다. 특히 precision이 크게 개선된 점은 언급 탐지 손실이 false positive를 효과적으로 억제했음을 시사한다. 추가 분석에서는 모델이 훈련 데이터에 존재하지 않는 새로운 언급도 탐지할 수 있음을 보여, 언급 탐지 손실이 일반화 능력을 강화한다는 점을 강조한다. 전체적으로 이 논문은 기존 엔드‑투‑엔드 코어퍼런스 파이프라인에 비교적 간단한 구조적·학습적 변형을 가함으로써, 복잡한 규칙 기반 전처리 없이도 최신 성능을 달성할 수 있음을 입증한다.
댓글 및 학술 토론
Loading comments...
의견 남기기