인텔 옵테인으로 보는 HPC I/O 성능 혁신
초록
본 논문은 인텔 옵테인(3D XPoint) SSD를 블록 디바이스로 활용했을 때, 전통적인 HDD와 비교하여 HPC 환경의 I/O 성능이 어떻게 변하는지를 다각도로 평가한다. 기본 대역폭, 체크포인트 워크로드, POSIX와 MPI‑IO(개별·집합) 성능 차이, 그리고 PVFS2 병렬 파일 시스템에서의 동작을 실험을 통해 분석한다. 결과는 옵테인이 랜덤·시퀀셜 모두에서 HDD보다 수십 배 빠르지만, 네트워크 병목과 MPI 집합 I/O의 데이터 셔플 비용 때문에 기대한 만큼의 전체 애플리케이션 가속은 제한적임을 보여준다.
상세 분석
이 연구는 인텔 옵테인 SSD를 저장소 기반(NVM) 모델의 대표 사례로 삼아, 기존 HPC I/O 스택이 새로운 비휘발성 메모리 기술에 얼마나 적합한지를 실험적으로 검증한다. 먼저 Intel Open Storage Toolkit을 이용해 단일 노드에서 순차·랜덤 읽·쓰기 대역폭을 측정했는데, 옵테인은 평균 2 170 MB/s(읽기)·2 170 MB/s(쓰기) 수준을 보이며 HDD(≈200 MB/s) 대비 10배 이상 우수했다. 특히 랜덤 I/O에서 성능 차이가 크게 나타나, 옵테인의 낮은 레이턴시와 높은 IOPS가 그대로 드러났다.
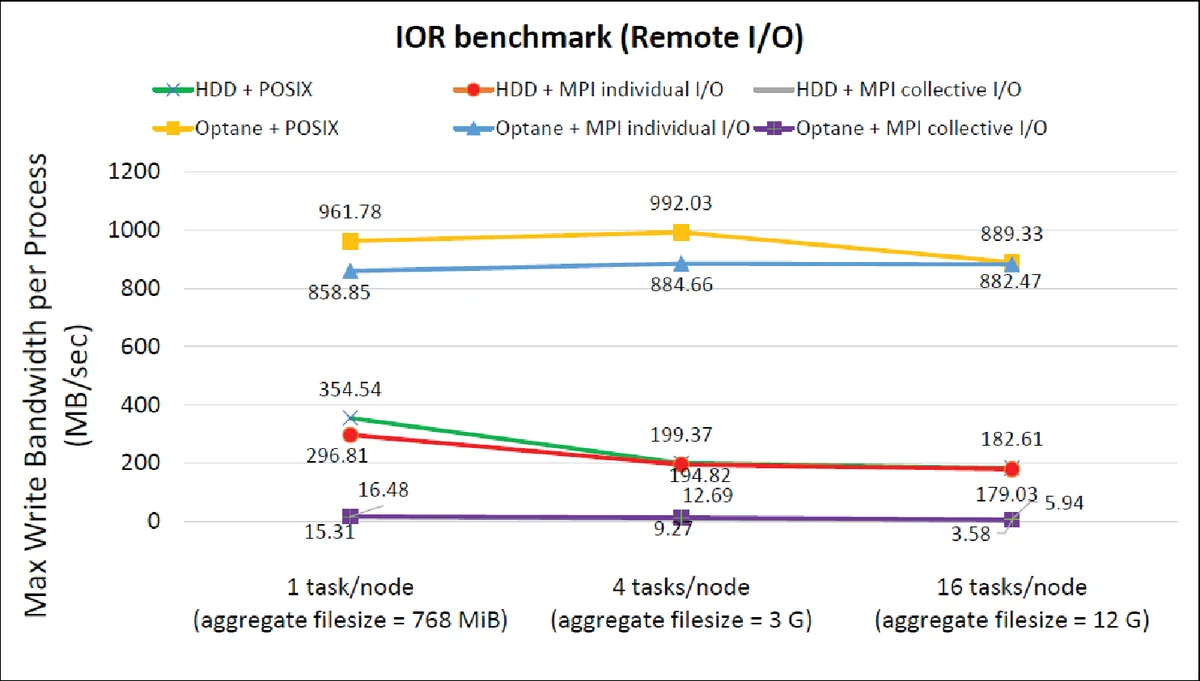
다음으로 HACC‑IO 체크포인트 워크로드를 NFS 환경에서 실행했을 때는, 네트워크 레이턴시가 전체 지연을 지배하게 되어 옵테인과 HDD 간의 성능 격차가 기본 대역폭 대비 560 % 정도로 축소되었다. 이는 스토리지 가속이 네트워크 대역폭·지연에 의해 제한될 수 있음을 시사한다. 또한 MPI 태스크 수가 4개 이상으로 늘어날 경우, 태스크당 대역폭이 소폭 감소하는 스케일링 한계도 관찰되었다.
POSIX I/O와 MPI 개별 I/O를 비교한 결과, 옵테인에서는 MPI I/O가 도입하는 오버헤드가 상대적으로 더 두드러졌다. 태스크 수가 적을 때는 MPI 개별 I/O가 POSIX보다 10 %~20 % 정도 낮은 성능을 보였지만, 태스크 수가 16개로 늘면 두 방식 간 차이가 거의 사라졌다. 이는 MPI I/O가 제공하는 데이터 재배열·검증 기능이 고성능 스토리지에서는 이득보다 비용이 더 크게 작용한다는 점을 강조한다.
MPI 집합 I/O와 개별 I/O를 NFS 환경에서 비교했을 때는, 데이터 셔플 단계에서 발생하는 네트워크 비용이 집합 I/O의 잠재적 이득을 상쇄해, 오히려 개별 I/O가 일관되게 우수한 결과를 보였다. 이는 기존 HPC 클러스터에서 네트워크가 병목인 경우, 집합 I/O 최적화가 무의미할 수 있음을 보여준다.
PVFS2 환경에서는 블록 크기, 클라이언트 수, I/O 노드 수에 따른 성능 변화를 상세히 조사했다. 블록 크기가 120 KB에서 2 MB로 증가할 때 옵테인에서 일시적인 성능 저하가 관찰됐으며, 이는 다중 I/O 노드 간 데이터 정렬 문제로 추정된다. 클라이언트 수를 늘리면 옵테인의 쓰기 대역폭이 지속적으로 상승해 좋은 확장성을 보였지만, HDD는 포화에 가까워 변동이 적었다. I/O 노드 수를 증가시켰을 때는 옵테인의 대역폭 상승폭이 15 %에 불과한 반면, HDD는 2.6배까지 크게 향상돼, 옵테인에서는 스토리지 자체보다 네트워크·파일시스템 레이어가 성능 한계가 됨을 확인했다. 흥미롭게도 PVFS2에서는 집합 I/O가 개별 I/O보다 우수한 결과를 보였는데, 이는 PVFS2가 내부적으로 네트워크 최적화를 수행해 데이터 셔플 오버헤드를 감소시켰기 때문이다.
전체적으로 본 논문은 옵테인이 제공하는 높은 대역폭·낮은 레이턴시가 실제 HPC 워크로드에서 완전히 활용되기 위해서는 네트워크·파일시스템 스택의 재설계가 필요함을 강조한다. 기존의 MPI 집합 I/O와 같은 최적화 기법은 스토리지 성능이 크게 향상된 상황에서는 오히려 비용이 될 수 있으며, 파일시스템 레이어가 네트워크 병목을 최소화하도록 설계돼야 한다는 중요한 시사점을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기