전체 EHR을 활용한 대규모 딥러닝 예측 모델
초록
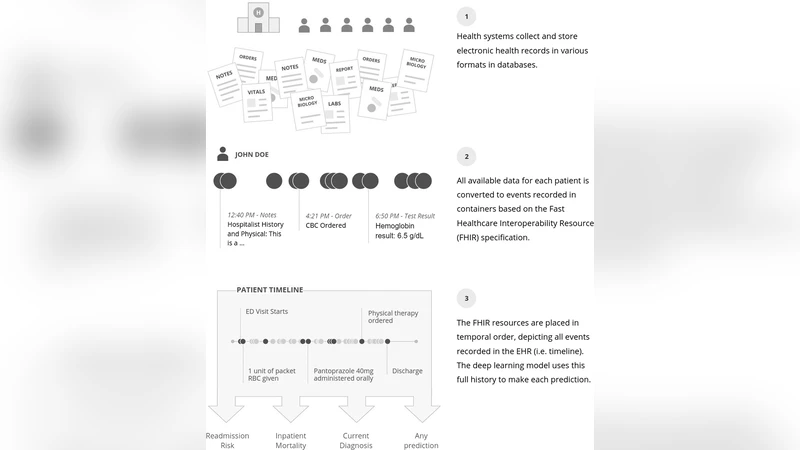
본 연구는 Fast Healthcare Interoperability Resources(FHIR) 형식으로 변환한 원시 전자건강기록(EHR)을 그대로 입력으로 사용해, 두 개의 미국 학술병원에서 216,221명의 입원 환자를 대상으로 사망, 재입원, 장기입원 및 퇴원 진단 예측을 수행하였다. 딥러닝 모델은 전통적인 점수 기반 모델을 모두 능가했으며, 46 억 개가 넘는 토큰을 학습에 활용하였다. 또한, 모델의 예측 근거를 시각화하는 해석 기법을 제시하였다.
상세 분석
이 논문은 기존 EHR 기반 예측 모델이 변수 선택과 데이터 정제에 수많은 인적 자원을 투입해야 하는 문제점을 지적하고, 이를 극복하기 위해 원시 데이터를 FHIR 리소스로 구조화한 뒤 토큰화(tokenization)하여 시계열 입력으로 전환하는 파이프라인을 제안한다. 토큰은 진단코드, 약물명, 실험실 결과, 임상 메모 등 모든 항목을 포함하며, 평균 입원 시점에 13만~21만 개의 토큰이 생성된다. 모델은 주로 Time‑Aware Neural Networks(TANN)와 Transformer‑ 기반 아키텍처를 활용했으며, 다중 모달리티(구조화 데이터와 자유 텍스트)를 별도 서브네트워크로 처리한 뒤 최종 레이어에서 통합한다. 학습은 두 병원의 데이터를 병합해 공동 모델을 구축했으며, 병원별 데이터 스키마 차이를 별도 정규화 없이 FHIR 표준만으로 해결하였다. 성능 평가는 AUROC, calibration curve, work‑up‑to‑detection 비율 등 다양한 지표를 사용했으며, 사망 예측에서는 24시간 시점에 0.94 수준, 재입원 예측에서는 0.76, 장기입원 예측에서는 0.86의 AUROC를 기록해 기존 aEWS, HOSPITAL, Liu 모델을 크게 앞섰다. 특히, 퇴원 진단을 다중 라벨 분류로 다루어 0.90의 가중 AUROC와 0.41의 micro‑F1을 달성했으며, 이는 기존 연구보다 훨씬 많은 ICD‑9 코드를 동시에 예측한 사례이다. 해석 가능성 측면에서는 Integrated Gradients와 유사한 attribution 기법을 적용해, 특정 환자에 대해 모델이 주목한 임상 메모, 약물, 검사값 등을 시각화함으로써 “블랙박스” 문제를 완화하였다. 한계로는 데이터가 두 대학병원에 국한돼 일반화 가능성 검증이 부족하고, 실시간 임상 적용을 위한 인프라 구축 비용이 언급되지 않은 점을 들 수 있다. 전반적으로, 원시 EHR를 그대로 활용한 대규모 딥러닝 파이프라인이 다양한 임상 예측 과제에서 기존 방법을 뛰어넘는 성능을 보이며, 모델 해석 도구와 결합해 실제 의료 현장에 적용 가능한 기반을 마련했다.
댓글 및 학술 토론
Loading comments...
의견 남기기