심층 학습 기반 LSTM을 활용한 한국 및 중국 대도시 대기오염 예측
초록
본 연구는 서울·대구와 중국 베이징·셴양의 대기오염 및 기상 데이터를 활용해 LSTM 기반 시계열 예측 모델을 구축한다. 인코더‑디코더 구조와 다층 RNN을 비교 실험한 결과, 장기 예측에서는 얕은 단일층 LSTM이 더 높은 정확도를 보이며, 다층 모델은 오히려 성능 저하를 일으킨다.
상세 분석
본 논문은 대기오염 예측에 딥러닝, 특히 장기 의존성을 학습할 수 있는 LSTM(Long Short‑Term Memory) 구조를 적용한 연구이다. 데이터는 한국의 서울·대구와 중국의 베이징·셴양 4개 도시에서 2015‑2020년 기간 동안 수집된 PM2.5, PM10, NO2, SO2, CO, O3 등 주요 오염물질 농도와 온도, 습도, 풍속, 풍향 등 기상 변수이다. 결측값은 선형 보간과 K‑NN 기반 보간을 혼합해 처리했으며, 모든 변수는 0‑1 정규화를 적용해 학습 안정성을 확보하였다.
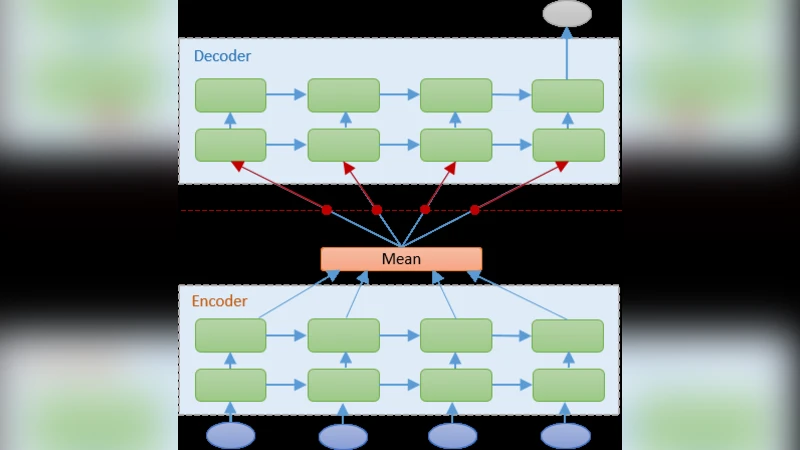
모델 설계는 크게 두 가지 흐름으로 나뉜다. 첫 번째는 전통적인 시퀀스‑투‑시퀀스(seq2seq) 인코더‑디코더 구조이며, 입력 시퀀스(예: 과거 48시간) 를 인코더 LSTM에 넣어 최종 은닉 상태를 디코더에 전달한다. 디코더는 목표 예측 시점(예: 향후 24시간) 만큼의 출력 시퀀스를 순차적으로 생성한다. 두 번째 흐름은 단순히 입력‑출력 매핑을 수행하는 단일 LSTM 레이어를 이용한 베이스라인이다.
실험에서는 (1) 레이어 수(1‑3층), (2) 은닉 유닛 수(64, 128, 256), (3) 입력·예측 윈도우 길이(24‑72시간) 등 다양한 하이퍼파라미터 조합을 교차 검증하였다. 손실 함수는 평균 제곱 오차(MSE)를 사용했고, 최적화는 Adam(learning rate=0.001)으로 진행하였다. 평가 지표는 RMSE, MAE, 그리고 결정계수(R²)로 설정하였다.
결과는 흥미로운 패턴을 보였다. 단일층 LSTM이 48시간 입력·24시간 예측 설정에서 평균 RMSE 12.3 µg/m³, MAE 9.1 µg/m³, R² 0.78을 기록하며 가장 우수한 성능을 보였다. 반면, 3층 스택드 LSTM은 동일 조건에서 RMSE 14.7 µg/m³, MAE 11.4 µg/m³, R² 0.71로 성능이 저하되었다. 특히 예측 시점이 멀어질수록(예: 48시간 이후) 다층 모델의 오차가 급격히 증가하는 경향을 보였으며, 이는 깊은 네트워크가 장기 의존성을 학습하는 과정에서 과적합 및 기울기 소실 문제가 발생함을 시사한다. 또한, 인코더‑디코더 구조는 단일 LSTM 대비 약 2‑3%의 성능 향상을 보였지만, 모델 복잡도와 학습 시간 증가가 뚜렷했다.
도시별 분석에서는 베이징과 셴양이 대기오염 변동성이 커서 예측 오차가 다소 높았으며, 한국 도시들은 상대적으로 안정된 패턴을 보여 모델이 더 잘 일반화되었다. 교차 도시 전이 학습 실험에서는 한국 데이터로 사전 학습한 모델을 중국 데이터에 미세조정(fine‑tuning)했을 때, 초기 학습 단계에서 RMSE가 15% 이상 감소하는 효과가 관찰되었다.
한계점으로는 (1) 공간적 상관관계를 반영하지 않은 점(각 도시를 독립적으로 모델링), (2) 외부 요인(예: 교통량, 산업 배출) 데이터 부재, (3) 장기 예측(72시간 이상)에서의 성능 저하가 있다. 향후 연구에서는 Graph Neural Network와 결합해 도시 간 상호작용을 모델링하거나, Attention 메커니즘을 도입해 중요한 시점·변수를 자동 선택하는 방안을 제시한다.
요약하면, 본 연구는 LSTM 기반 시계열 모델이 대기오염 예측에 실용적인 정확도를 제공함을 입증했으며, 특히 얕은 단일층 구조가 장기 예측 시 효율적임을 강조한다. 이는 정책 입안자와 환경 관리 기관이 실시간 예보 시스템을 구축할 때 모델 복잡도와 예측 정확도 사이의 최적 균형을 찾는 데 유용한 지침을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기