계층형 지연 감소 DRAM으로 저비용 고성능 메모리 구현
초록
TL‑DRAM은 긴 비트라인을 두 개의 짧은 구간으로 나누어 근접 구간은 짧은 비트라인과 동일한 저지연을 제공하고, 원래의 비용 구조는 유지한다. 하드웨어·소프트웨어 수준에서 근접 구간을 캐시로 활용하면 단일·멀티코어 시스템에서 평균 12 % 이상의 성능 향상과 25 % 이상의 전력 절감 효과를 얻을 수 있다.
상세 분석
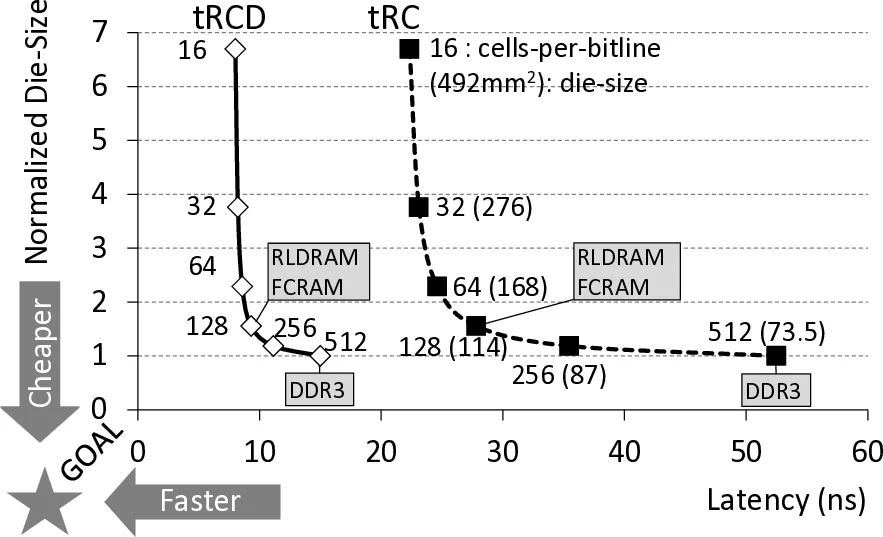
본 논문은 DRAM 설계에서 비용과 지연 사이의 근본적인 트레이드오프를 재조명한다. 기존 상업용 DRAM은 수백 개의 셀을 하나의 센스 앰프에 연결하는 긴 비트라인을 사용함으로써 면적 효율성을 극대화하지만, 비트라인의 기생 정전용량이 커져 셀‑센스 앰프 간 전압 변동이 느려지고, 프리차징·리프레시 과정에서도 큰 전력과 시간이 소모된다. 반면, RLDRAM·FCRAM과 같은 저지연 DRAM은 비트라인 길이를 크게 줄여 정전용량을 감소시키지만, 동일한 용량을 제공하려면 센스 앰프 수가 급증해 면적·비용이 크게 늘어난다.
TL‑DRAM은 ‘분리 트랜지스터(isolation transistor)’를 비트라인 중간에 삽입해 비트라인을 Near(근접) 구간과 Far(원거리) 구간으로 물리적으로 분할한다. Near 구간은 센스 앰프에 직접 연결돼 짧은 비트라인과 동일한 정전용량을 갖게 되며, 액세스 시 tRCD·tRC가 크게 감소한다. Far 구간은 트랜지스터를 통해 연결되므로, 트랜지스터가 저항 역할을 하여 전압 상승 속도가 늦어져 tRC가 증가하지만, 전체 용량을 유지하면서 면적 증가율은 3 %에 불과하다.
시뮬레이션 결과는 Near 구간 길이가 짧을수록 지연 감소폭이 커짐을 보여준다. 예를 들어 128셀(≈25 % 비트라인) 길이의 Near 구간은 tRC가 23 ns로 기존 512셀(≈100 % 비트라인) 대비 50 % 이상 빠르다. 반면 Far 구간은 트랜지스터 저항으로 인해 tRC가 65 ns까지 늘어나지만, 전체 시스템에서 Far 구간 접근 비율이 낮으면 전체 평균 지연에 미치는 영향은 제한적이다.
운용 측면에서 저자들은 두 가지 캐시 관리 방식을 제안한다. 첫 번째는 메모리 컨트롤러가 Near 구간을 하드웨어‑관리 캐시로 활용해, 자주 사용되는 행을 자동으로 복제·교체하는 정책이다. 여기서 핵심은 ‘Inter‑Segment Data Transfer’ 메커니즘으로, 동일 비트라인을 버스처럼 이용해 DRAM 내부에서 행 간 데이터를 4 ns 추가 지연만으로 이동시켜 외부 채널을 차단하지 않는다. 두 번째는 운영체제 수준에서 Near 구간을 별도 메모리 영역으로 노출해 페이지 레벨 매핑을 통해 빈번히 접근되는 페이지를 직접 할당하는 방식이다. 두 접근 모두 Near 구간 접근 시 전력 소모가 약 50 % 감소하고, Far 구간 접근 시 약 1.5배 전력이 증가하지만 전체 워크로드에서 Near 구간 히트 비율이 90 % 이상이므로 평균 전력 절감 효과가 크게 나타난다.
성능 평가에서는 Ramulator 기반 시뮬레이터와 인하우스 프로세서 모델을 사용해 1·2·4코어 시스템에서 IPC 향상이 각각 12.8 %, 12.3 %, 11.0 %이며, 전력 절감은 23.6 %~28.6 %에 달한다는 결과를 제시한다. 이는 DRAM 지연이 CPU 스톨의 주요 원인인 현대 시스템에서, 비용을 크게 늘리지 않고도 메모리 서브시스템의 병목을 효과적으로 완화할 수 있음을 증명한다.
또한 TL‑DRAM은 이후 RowClone, LISA, DARP 등 다양한 DRAM 내부 데이터 이동·복제 기술의 기반이 되었으며, 메모리 계층 설계와 시스템‑소프트웨어 협조 최적화 연구에 새로운 설계 공간을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기