GitHub 대규모 오픈소스 생태계에서 공개 개발 프로젝트 자동 탐지
초록
본 연구는 GitHub에 존재하는 10 만 개 이상의 프로젝트 중 ‘공개 개발 프로젝트’를 자동으로 식별하기 위한 방법을 제시한다. GHTorrent 데이터를 활용해 6 715개의 프로젝트를 직접 라벨링하고, 프로젝트 설명·URL·기본 메트릭(스타, 워처 등)에서 추출한 30여 개의 키워드와 메타 정보를 입력 변수로 J48 의사결정트리를 학습한다. 단순 모델은 0.827 precision·0.947 recall을, 복합 모델은 0.926 precision·0.959 recall을 달성했으며, 수작업 대비 63 % 이상의 작업량 절감 효과를 보였다.
상세 분석
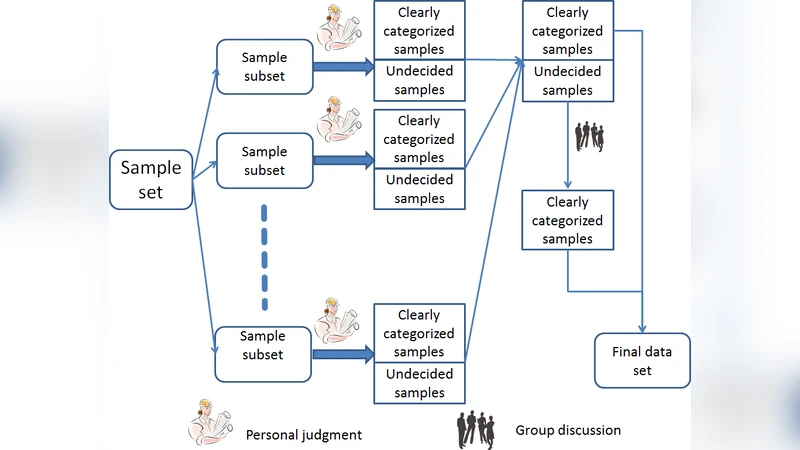
이 논문은 대규모 오픈소스 데이터셋을 활용한 연구에서 가장 빈번히 발생하는 ‘샘플 선택 편향’ 문제를 해결하고자 한다. 기존 연구들은 스타 수·포크 수·프로그래밍 언어 등 단일 기준에 의존해 프로젝트를 필터링했지만, 이러한 방법은 개발 목적이 아닌 블로그, 개인 저장소 등 비개발 프로젝트를 배제하지 못한다. 저자들은 ‘공개(public)’와 ‘개발(development)’이라는 두 축을 명확히 정의하고, 이를 기준으로 6 715개의 프로젝트를 전문가 집단이 라벨링해 표준 데이터셋을 구축하였다. 라벨링 과정에서 ‘설명·README에 개인용임을 명시하지 않은 경우’를 공개 프로젝트로, ‘코드·라이브러리·플러그인·프레임워크 등 소프트웨어 제작에 사용되는 파일이 존재하는 경우’를 개발 프로젝트로 구분하였다.
특징 추출 단계에서는 ‘mirror’, ‘fork’, ‘test’, ‘tool’, ‘plugin’ 등 30여 개의 키워드를 Boolean 형태로 변환하고, 스타·워처·커밋터 수 등 정량적 메트릭을 추가했다. 이러한 다차원 특성을 이용해 J48 의사결정트리를 학습시켰으며, 두 가지 모델을 제시한다. 첫 번째 ‘단순 모델’은 복잡한 규칙을 최소화해 빠른 자동 분류가 가능하도록 설계됐으며, 0.827의 정밀도와 0.947의 재현율을 기록한다. 두 번째 ‘복합 모델’은 추가적인 가지치기와 규칙 조정을 통해 오분류를 최소화했으며, 0.926 정밀도·0.959 재현율을 달성함과 동시에 수작업 검증 대비 63.2 % 적은 인적 자원을 요구한다.
실험에서는 기존 샘플 선택 방법인 ‘저성능 프로젝트 제거’와 ‘상위 프로젝트 선택’과 비교했으며, 제안 모델이 두 기준 모두보다 높은 정밀도·재현율을 보였다. 또한, 1,000개의 파일을 대상으로 파일 내용 기반 검증을 수행해 키워드 매칭만으로는 잡히지 않는 사례(예: ‘test’라는 단어가 포함되지만 ‘tool’과 결합된 경우)를 의사결정트리가 효과적으로 구분함을 확인했다.
위협 요인으로는 라벨링 과정에서의 주관적 판단, 영어 외 프로젝트 배제, 그리고 GHTorrent 데이터의 최신성 문제를 제시한다. 저자들은 향후 다국어 지원 및 지속적 데이터 업데이트를 통해 모델의 일반화를 확대할 계획이라고 밝혔다. 전체적으로 이 연구는 대규모 OSS 연구에서 샘플 선택 단계의 자동화를 가능하게 함으로써, 연구 재현성 및 효율성을 크게 향상시킬 수 있음을 입증한다.
댓글 및 학술 토론
Loading comments...
의견 남기기