감정 인식을 위한 오디오 GAN 기반 표현 학습 모델
본 논문은 OMG Emotion Challenge를 위해 오디오 전용 감정 인식 모델을 제안한다. IEMOCAP 데이터로 BEGAN(자동인코더 기반 GAN)을 비지도 학습하여 음성 표현을 학습하고, 이를 1초 길이의 스펙트로그램에 적용한다. 이후 CNN과 tanh 활성화 Dense 레이어를 통해 각 조각의 arousal·valence를 예측하고, 전체 발화는 예측값의 중앙값으로 통합한다. 실험 결과 기존 베이스라인보다 높은 CCC를 달성하였다.
저자: Ingryd Pereira, Diego Santos
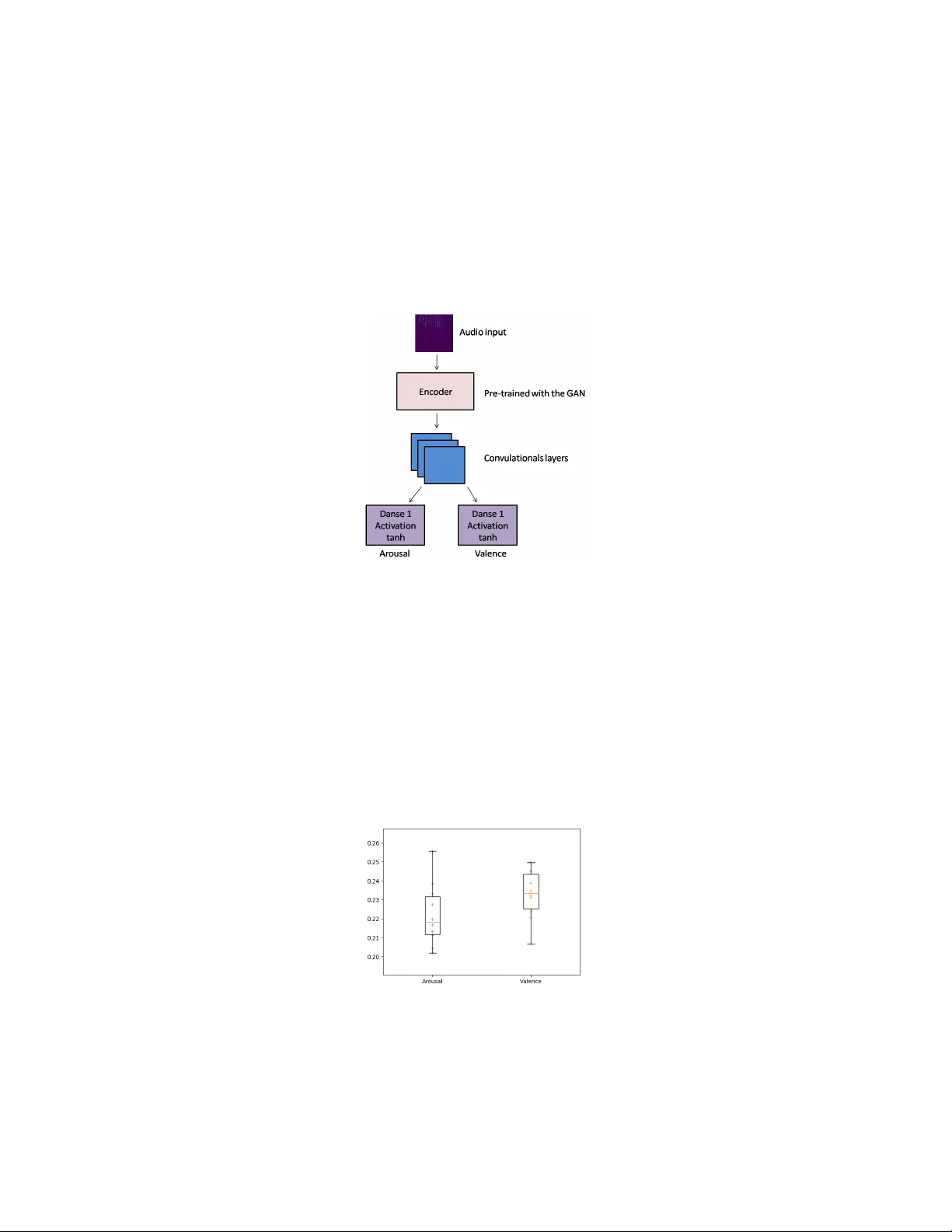
본 논문은 OMG Emotion Challenge에 제출하기 위한 오디오 전용 감정 인식 시스템을 설계하고 평가한다. 감정 표현을 음성으로부터 추출하는 작업은 전통적인 MFCC와 같은 수동 특징이 정보 손실을 초래하는 반면, 딥러닝 기반 모델은 원시 스펙트럼을 직접 학습함으로써 더 풍부한 표현을 얻을 수 있다. 그러나 딥러닝 모델은 대량의 라벨링된 감정 데이터가 필요하고, 실제 감정 데이터는 제한적이다. 이를 해결하고자 저자들은 반지도학습 전략을 채택한다.
구체적으로, IEMOCAP 데이터베이스를 이용해 BEGAN(Boundary Equilibrium GAN)을 비지도 학습한다. BEGAN의 판별자는 자동인코더 구조이며, 인코더는 입력 스펙트로그램을 저차원 잠재벡터로 압축한다. 이 인코더는 이후 OMG 데이터셋에서 오디오 표현을 추출하는 데 재사용된다.
전처리 단계에서는 모든 비디오 파일을 WAV 형식으로 변환하고, 샘플링 레이트를 16 kHz로 통일한다. 각 오디오 트랙은 1초 길이의 청크로 나누어 겹치지 않게 분할한다. 각 청크는 1024 포인트 FFT와 512 포인트 윈도우를 적용해 스펙트로그램으로 변환한다. 변환된 스펙트로그램은 사전 학습된 인코더에 입력되어 잠재 표현을 얻고, 이 표현은 연속적인 2‑D CNN 레이어와 tanh 활성화 함수를 가진 Dense 레이어를 거쳐 arousal와 valence를 -1에서 1 사이의 실수값으로 회귀한다.
예측 단계에서는 1초 청크마다 arousal와 valence를 추정하고, 전체 발화에 대한 최종 감정 점수는 각 청크 예측값의 중앙값을 사용한다. 중앙값 집계는 이상치와 순간적인 변동에 대한 강인성을 제공한다.
학습은 100 epoch, 배치 크기 16, γ=0.7의 하이퍼파라미터로 진행되었다. 실험 결과는 10번의 독립 실행에서 arousal와 valence에 대한 Concordance Correlation Coefficient(CCC)가 각각 0.15와 0.21을 초과하는 기존 베이스라인(Barros et al.)보다 우수함을 보여준다. 특히, 박스플롯을 통해 모델의 안정성과 성능 향상을 시각적으로 확인하였다.
이 시스템의 주요 장점은 (1) 대규모 비라벨 오디오 데이터(IEMOCAP)를 활용해 일반화된 음성 표현을 학습함으로써 라벨 부족 문제를 완화한다, (2) 학습된 인코더를 다른 감정 데이터셋이나 음성 관련 태스크에 재사용 가능하게 만든다, (3) 1초 청크 기반 예측과 중앙값 집계가 시간적 변동성을 효과적으로 억제한다는 점이다. 반면, 오디오만을 사용했기 때문에 시각·텍스트와의 멀티모달 융합 가능성을 놓쳤으며, BEGAN 훈련이 불안정할 수 있다는 한계도 존재한다. 향후 연구에서는 멀티모달 통합, 청크 오버랩 전략의 최적화, 최신 GAN 변형 적용 등을 통해 성능을 더욱 향상시킬 수 있을 것으로 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기