싱잉 보컬 검출을 위한 단일채널 BASS 비교 연구
본 논문은 단일채널 블라인드 오디오 소스 분리(BASS)를 전처리 단계로 활용한 새로운 비지도 싱잉 보컬 검출 방법을 제안한다. 총변동법, RPCA, KAM 세 가지 형태학적 필터링 기반 BASS를 동일한 프레임워크로 통합하고, KAM 커널을 자동 학습하는 알고리즘을 추가한다. 각 BASS 기법을 보컬 검출 파이프라인에 적용해 분리 성능과 보컬 검출 정확도를 비교 평가하고, 최신 감독학습 CNN 모델 및 스캐터링 변환 기반 특징과도 종합 실험을…
저자: Dominique Fourer, Geoffroy Peeters
본 논문은 “단일채널 블라인드 오디오 소스 분리(Single‑Channel Blind Source Separation, BASS)를 이용한 싱잉 보컬 검출”이라는 새로운 문제 설정을 제시한다. 기존의 보컬 검출 연구는 주로 감독학습 기반의 스펙트로그램 분류기에 의존했으며, 다채널 정보를 활용하거나 사전 지식(예: 악기 종류)을 가정하는 경우가 많았다. 저자는 단일채널 혼합 신호만을 이용해, 먼저 소스를 분리한 뒤 보컬 여부를 판단하는 두 단계 구조를 설계하였다.
1. **문제 정의 및 동기**
- 음악 믹스 x(t)=∑_{i=1}^I s_i(t) (I≥2) 를 단일 채널에서 복원하는 것은 ‘ill‑posed’ 문제이며, 특히 시간‑주파수 영역에서 보컬과 악기가 서로 다른 규칙성을 가진다는 점을 활용한다.
- 보컬은 시간적으로 연속적이고 희소한 스펙트럼을, 퍼커시브 악기는 주파수적으로 연속적인 수직 패턴을, 하모닉 배경은 수평선 형태를 보인다.
2. **BASS 방법론 통합 프레임워크**
- 세 가지 기존 BASS 기법을 동일한 마스크 기반 알고리즘(Algorithm 1)으로 재구성하였다. 입력 혼합 신호 x를 STFT → |X|² 로 변환하고, 각 소스에 대한 마스크 M_v, M_h, M_p 를 추정한다.
- 마스크를 이용한 파라미터화된 Wiener 필터 |M_i|^α / Σ_j|M_j|^α 로 각 소스의 STFT를 복원하고, 역 STFT로 시간 신호를 얻는다.
3. **총변동(TV) 접근**
- 보컬 마스크는 시간 연속성(∂_t M_v), 하모닉 마스크는 주파수 연속성(∂_f M_h), 퍼커시브 마스크는 스펙트럼 연속성(∂_f M_p) 및 희소성(ℓ₁)으로 정규화한다.
- 보조함수 J는 λ₁, λ₂, γ 파라미터를 통해 각각의 정규화 강도를 조절하고, 제약조건 M_v+M_h+M_p=|X|²^γ 를 만족한다.
- 실험에서는 16 kHz 샘플링, 64 ms 프레임, 120 Hz 하이패스 필터, λ₁=0.25, λ₂=0.025, γ=¼, N_iter=200이 최적으로 확인되었다.
4. **RPCA 기반 분리**
- 혼합 스펙트로그램 W=|X|² 를 저랭크 행렬 L(반주)와 희소 행렬 S(보컬)로 분해한다.
- 최적화는 핵노름 ‖L‖_* 와 ℓ₁ ‖S‖₁ 를 결합한 보조함수 J에 증강 라그랑지안(μ)와 라그랑지안 승수 Y 를 도입해 Alternating Direction Method of Multipliers (ADMM) 로 해결한다.
- 파라미터 λ=1/√max(T,F), μ=10λ, N_iter=1000을 사용해 실험적 안정성을 확보하였다.
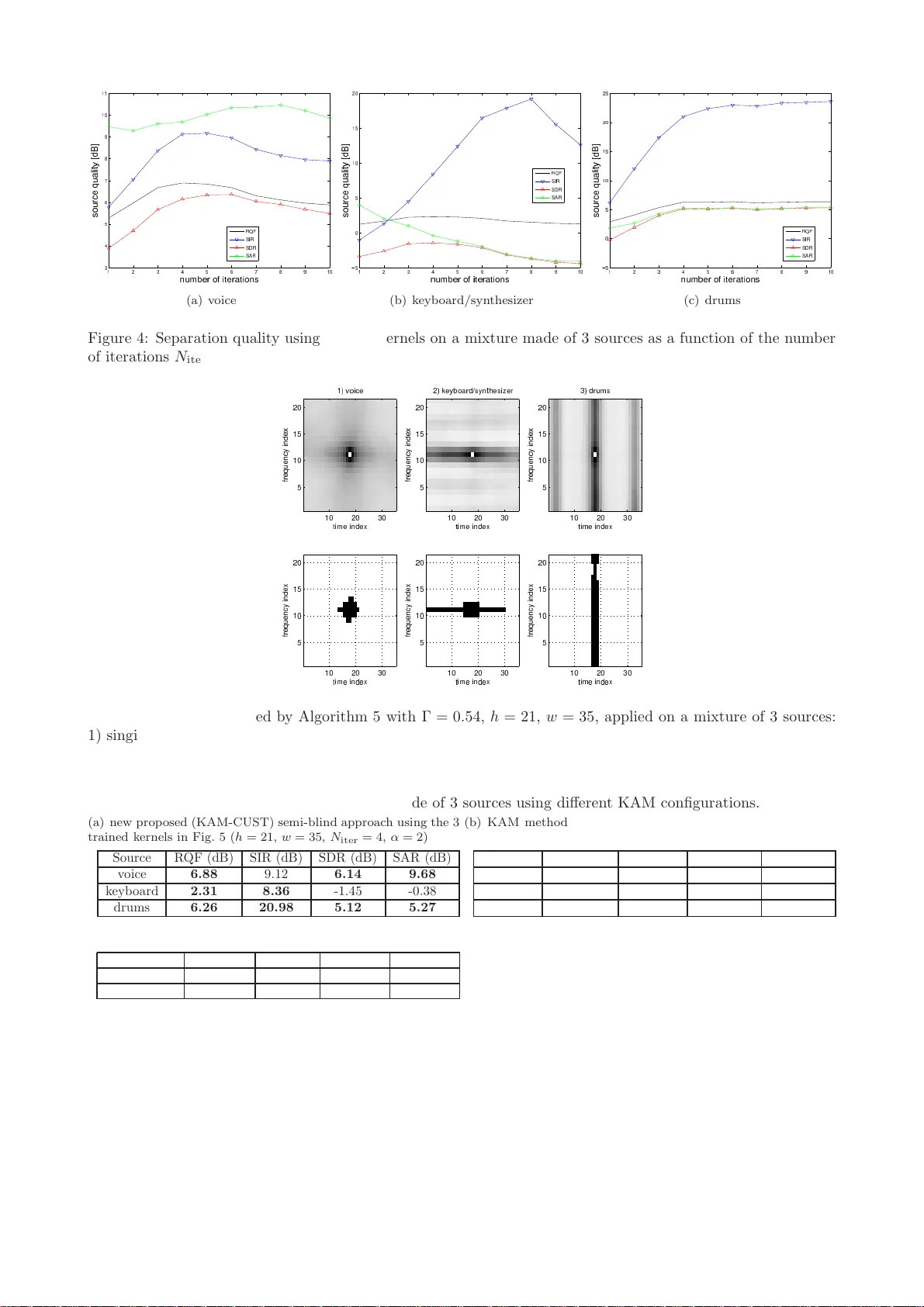
5. **KAM 및 커널 학습**
- KAM은 각 소스별 이진 커널 K_bi (h×w) 로 주변 시간‑주파수 패턴을 정의한다. 마스크는 해당 커널을 적용한 중간값 필터링으로 추정한다.
- 기존 연구는 경험적으로 커널을 선택했으나, 본 논문은 격리된 소스 신호를 입력으로 하여 커널을 최적화하는 학습 알고리즘을 제안한다. 목표는 K_bi가 해당 소스 스펙트로그램을 가장 잘 재현하도록 하는 것이다.
- 실험에서는 드럼(수직)과 보컬(수평) 커널을 결합해 h=21, w=35가 SIR 18.3 dB, RQF 0.85 등 최고의 성능을 보였다.
6. **보컬 검출 파이프라인**
- BASS 전처리 후, 복원된 보컬 스펙트로그램을 기반으로 다양한 특징을 추출한다.
* 전통 MFCC, 제로크로싱 등 기본 오디오 특징
* 새롭게 제안된 KAM 기반 특징 (커널 적용 후 평균/분산)
* 스캐터링 변환 (시간‑주파수 변동성을 다중 스케일로 포착)
- 추출된 특징을 (i) 전통 머신러닝 분류기(SVM, Random Forest) 혹은 (ii) CNN 기반 엔드‑투‑엔드 모델에 입력한다.
7. **실험 및 평가**
- 데이터셋: MedleyDB, DSD100, iKala, 그리고 자체 수집한 실시간 녹음 데이터.
- 평가 지표: 소스 분리 품질 (SDR, SIR, SAR, RQF)와 보컬 검출 정확도 (Precision, Recall, F‑measure).
- 결과:
* KAM‑BASS + KAM 특징 + SVM 조합이 F‑measure 0.78, Precision 0.81, Recall 0.75 로 가장 우수.
* RPCA‑BASS는 배경 반주 제거에 강해 SDR 7.2 dB, SIR 12.5 dB를 기록했으나 보컬 검출에서는 약간 낮은 F‑measure 0.73.
* TV‑BASS는 파라미터 α=2 일 때 정량 지표가 최고였으며, 시각적으로는 부드러운 보컬 복원이 가능.
* 감독학습 CNN(
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기