복잡망을 이용한 언어 다양성 예측
초록
본 연구는 사회적 상호작용을 기반으로 한 복잡망 모델을 확장하여 인구 규모에 따른 언어 다양성의 스케일링 법칙을 탐구한다. 지역 재배선과 높은 클러스터링을 포함한 네트워크 토폴로지가 언어 도메인 수와 인구 규모 사이의 양의 상관관계를 재현함을 실증 데이터(에스노라벨, WALS)와 시뮬레이션을 통해 입증한다.
상세 분석
이 논문은 언어 변화와 확산을 ‘에이전트-링크’ 복합 시스템으로 모델링한다. 각 에이전트는 F개의 언어적 특성(트레이트)으로 표현되며, 각 특성은 q개의 가능한 값 중 하나를 가진다. 초기에는 모든 노드가 무작위로 할당된 트레이트를 갖고, 평균 차수 ⟨k⟩을 갖는 무작위 그래프에서 시작한다. 매 시간 단계마다 활성 노드 i와 이웃 j를 선택하고, 두 노드 사이의 동일 특성 수 m을 계산한다. m=F이면 상호작용이 없으며, m=0이면 두 언어가 전혀 겹치지 않으므로 연결을 끊고, 2-스텝 이웃(이웃의 이웃) 중 하나와 새 연결을 만든다. 이 재배선 과정은 ‘지역 재배선’이라고 부르며, 두 가지 버전(균등 확률, 선호적 연결 P(i)∝(k_i+1)^2)을 실험한다. m>0인 경우에는 확률 m/F로 긍정적 상호작용이 발생하여 활성 노드가 j의 미공유 특성 하나를 복제한다. 이러한 규칙은 언어적 동질성 증가와 네트워크 구조 변화를 동시에 유도한다.
시뮬레이션 결과는 세 가지 뚜렷한 상전이를 보인다. 첫 번째 단계에서는 q가 작아 거의 모든 에이전트가 동일 언어를 사용하고, 네트워크는 연결된 상태를 유지한다. 두 번째 단계에서는 네트워크가 다수의 작은 컴포넌트로 분리되며, 각 컴포넌트는 고유한 언어를 갖는다(사회적 분극). 세 번째 단계에서는 일부 재결합이 일어나면서 서로 다른 언어를 사용하는 노드 간에도 연결이 존재한다. 저자는 특히 두 번째 단계가 실제 언어 다양성 현상을 설명하는 데 적합하다고 주장한다.
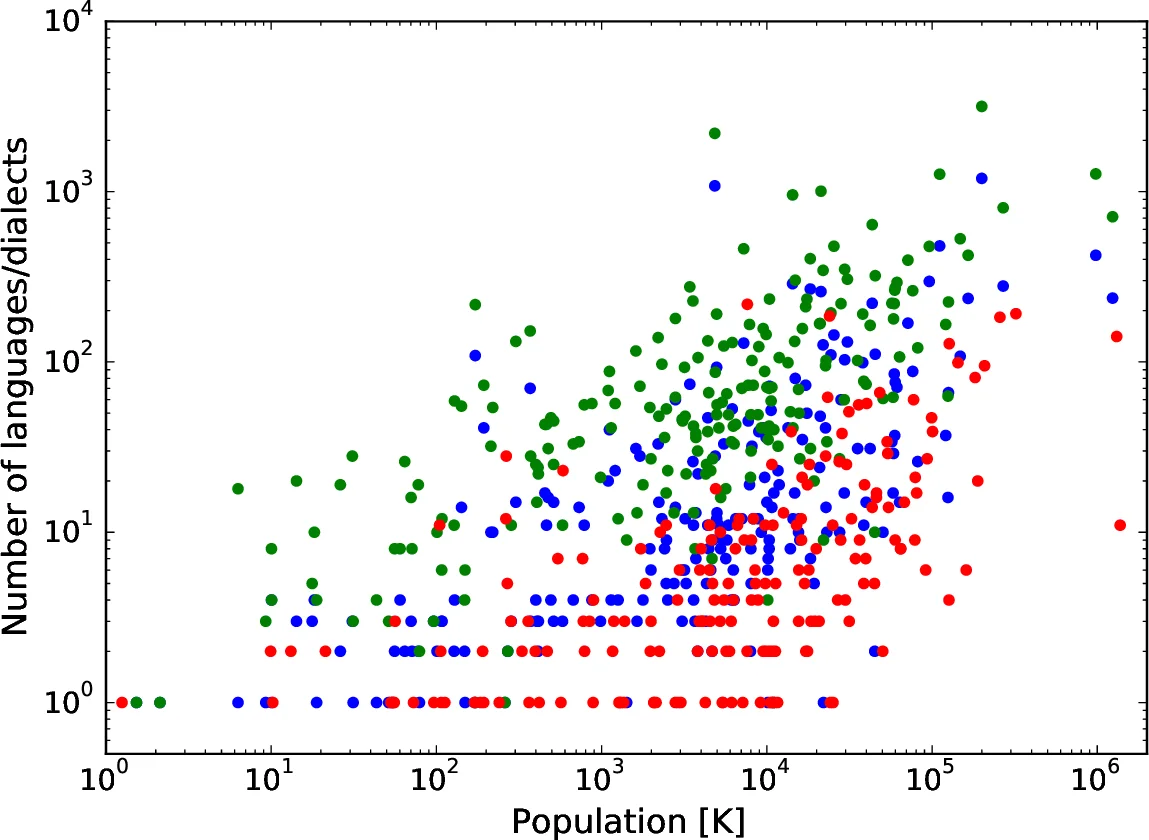
핵심적인 발견은 ‘고클러스터링’과 ‘네트워크 분해’가 실증 데이터와 일치한다는 점이다. 지역 재배선은 클러스터링 계수를 자연스럽게 상승시켜, 실제 사회망이 보이는 높은 삼각형 비율을 재현한다. 또한, 네트워크 규모 N이 증가할수록 도메인(언어) 수가 증가하는 양의 스케일링이 관찰되었다. 이는 솔로몬 제도 연구(언어 수가 섬 규모와 비례)와 일치한다. 반면, 기존의 정적 격자 모델이나 단순 적응형 모델은 언어 수와 인구 규모 사이에 부정적인 혹은 무관한 관계를 보였으며, 이 논문은 이를 해결한다.
실증 검증을 위해 두 개의 공개 데이터베이스(Ethnologue, WALS)와 UN 인구 데이터를 활용했다. 국가별 언어 수와 인구 규모를 직접 비교한 결과, 전반적으로 언어 수가 인구 규모와 양의 상관관계를 보였지만, 중국·인도·인도네시아·파푸아뉴기니와 같이 극단적인 사례를 제외하면 보다 명확한 증가 추세가 드러났다. 또한, 인구 규모를 구간별로 평균화한 집계에서도 동일한 패턴이 확인되었다.
한계점으로는 트레이트와 값의 선택이 실제 언어의 복잡성을 충분히 포착하지 못한다는 점, 그리고 문화·정책·역사적 요인 등 비사회적 변수들을 모델에 포함시키지 않았다는 점을 언급한다. 그럼에도 불구하고, 네트워크 토폴로지와 재배선 메커니즘이 언어 다양성의 거시적 패턴을 설명하는 데 핵심적이라는 결론은 강력히 뒷받침된다.
댓글 및 학술 토론
Loading comments...
의견 남기기