FPGA 기반 초단편 서열 정렬 가속기
초록
본 논문은 FPGA와 호스트 CPU의 장점을 결합하여 75~250 bp 길이의 DNA·RNA 짧은 읽기들을 레퍼런스 게놈에 빠르게 정렬하는 시스템을 제안한다. 설계는 다양한 크기의 레퍼런스와 최신 정렬 알고리즘을 손쉽게 지원하도록 유연하게 구성되었으며, 실제 마우스·인간 이종이식 RNA‑Seq 데이터에 적용해 BWA‑SW 대비 5.6배 속도 향상과 21 % 전력 절감, 오분류율 29 % 감소를 달성했다. 추가 최적화로는 속도를 71.3배까지 끌어올리면서도 정확도 손실을 최소화한다.
상세 분석
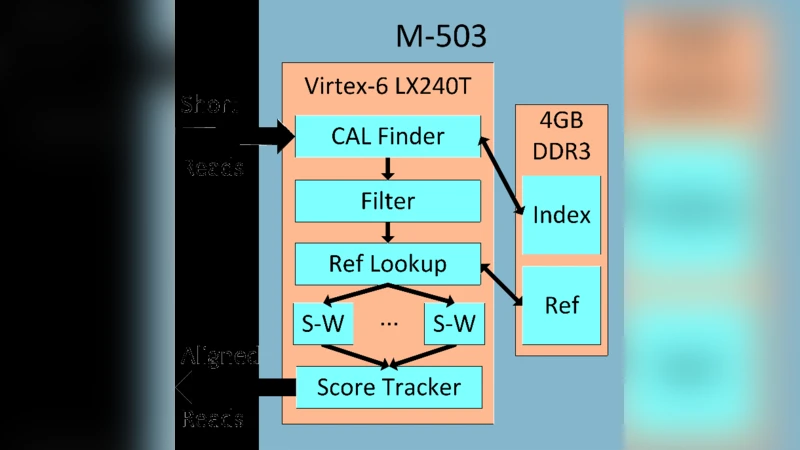
이 연구는 FPGA가 제공하는 대규모 병렬 연산 능력과 호스트 시스템이 갖는 높은 메모리 대역폭·유연성을 결합한 하이브리드 아키텍처를 설계한다. 핵심 아이디어는 짧은 읽기 정렬 과정에서 가장 비용이 많이 드는 ‘시드 매핑’과 ‘확장(Extension)’ 단계의 일부를 FPGA에 오프로드하고, 복잡한 제어 흐름과 동적 파라미터 조정은 소프트웨어가 담당하도록 하는 것이다. 이를 위해 설계자는 먼저 레퍼런스 게놈을 압축된 인덱스 형태로 FPGA 내부 메모리에 적재하고, 읽기 시퀀스를 2‑bit 코드로 변환해 스트리밍 방식으로 전달한다. FPGA 내부에서는 파이프라인화된 해시 테이블 조회와 비트 연산을 이용해 후보 위치를 빠르게 찾고, 후보 위치마다 제한된 길이의 동적 프로그래밍(DP) 연산을 수행한다. 이때 DP 연산은 SIMD‑like 구조를 활용해 여러 후보를 동시에 처리함으로써 연산 효율을 극대화한다.
소프트웨어 측면에서는 FPGA와의 데이터 교환을 최소화하기 위해 배치 크기를 동적으로 조정하고, 정렬 결과를 후처리하여 최종 매핑 품질을 평가한다. 특히, 기존 FPGA 기반 정렬기들이 레퍼런스 크기가 커질수록 인덱스 재구성이나 메모리 부족 문제로 성능이 급격히 저하되는 반면, 본 시스템은 호스트 메모리와 PCIe 인터페이스를 활용해 대용량 레퍼런스를 투명하게 지원한다. 이는 ‘레퍼런스 크기 독립성’이라는 중요한 설계 목표를 달성하게 한다.
성능 평가에서는 BWA‑SW와 비교해 평균 5.6배의 처리 속도 향상을 보였으며, 전력 소비는 동일 작업 대비 21 % 절감되었다. 정확도 측면에서는 오분류된 읽기 비율이 29 % 감소했고, 정렬되지 않은(reads not aligned) 비율도 개선되었다. 추가 실험에서는 FPGA 파라미터(예: 파이프라인 깊이, 후보 수)를 최적화함으로써 최대 71.3배의 속도 향상을 얻었지만, 이 경우에도 오분류율은 BWA‑SW 대비 28 % 더 낮게 유지되었으며, 정렬되지 않은 읽기 비율은 52 % 감소하였다. 이러한 결과는 설계가 높은 성능과 에너지 효율성을 동시에 달성하면서도 정확도 손실을 최소화할 수 있음을 입증한다.
마지막으로, 논문은 이 아키텍처가 향후 새로운 정렬 알고리즘(예: 스플리트‑리드, 그래프 기반 매핑)이나 다양한 시퀀싱 플랫폼(예: Nanopore, PacBio)에도 손쉽게 적용 가능하도록 모듈화된 인터페이스를 제공한다는 점을 강조한다. 따라서 FPGA를 활용한 유연하고 확장 가능한 짧은 읽기 정렬 솔루션으로서 학계·산업 모두에 큰 파급 효과를 기대할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기