인간 가르침과 피드백을 활용한 하이브리드 대화 학습
초록
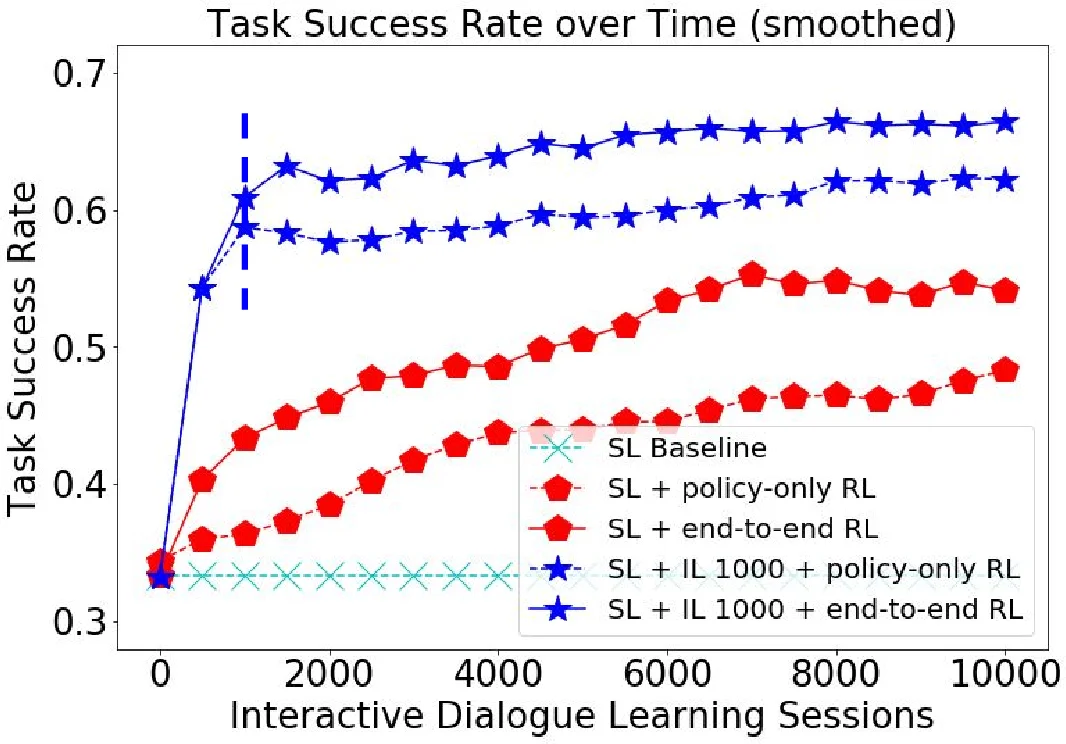
본 논문은 오프라인 사전학습과 온라인 상호작용 사이의 대화 상태 분포 불일치를 완화하기 위해, 인간 교사의 직접적인 시연(모방학습)과 간단한 이진 피드백을 결합한 하이브리드 학습 프레임워크를 제안한다. 제안된 엔드‑투‑엔드 신경망 기반 태스크 지향 대화 시스템은 발화 인코더, 연속형 대화 상태 트래커, 심볼릭 KB 쿼리, 정책 네트워크, 템플릿 기반 NLG로 구성되며, 초기에는 지도학습으로 사전학습된 뒤 인간 교정 대화를 통해 모방학습을 수행하고, 최종적으로 강화학습을 적용해 성공률을 향상시킨다. 실험 결과, 인간 교정 단계만으로도 오류 복구 능력이 크게 개선되었으며, 이후 강화학습을 추가하면 태스크 성공률이 추가 상승한다.
상세 분석
이 논문은 기존의 태스크 지향 대화 시스템이 겪는 두 가지 핵심 문제—모듈식 파이프라인의 오류 전파와 오프라인 지도학습과 온라인 강화학습 사이의 상태 분포 불일치—를 동시에 해결하려는 시도로 평가된다. 제안된 모델은 발화 인코더로 양방향 LSTM을 사용해 사용자 발화를 연속형 벡터로 변환하고, 이전 시스템 행동과 결합해 대화‑레벨 LSTM에 입력함으로써 대화 상태 sₖ를 지속적으로 업데이트한다. 이 상태는 슬롯별 확률 분포 P(lₘₖ) 를 출력하는 MLP에 전달돼 목표 슬롯 값을 추정한다. 추정된 슬롯 값은 심볼릭 API 템플릿에 삽입해 KB에 질의하고, 반환된 결과 요약(Eₖ)을 정책 네트워크에 추가 입력한다. 정책 네트워크는 sₖ, 슬롯 로그 확률 vₖ, 그리고 Eₖ를 결합해 다음 시스템 행동 aₖ의 확률 분포를 출력한다. 행동은 템플릿 기반 NLG에 의해 자연어 응답으로 변환된다.
학습 단계는 크게 세 단계로 나뉜다. 첫째, 대규모 대화 코퍼스를 이용해 대화 상태 추적과 정책 예측을 동시에 최적화하는 지도학습(ML‑MLE) 단계이다. 손실 함수는 슬롯 추정과 행동 예측의 교차 엔트로피를 가중합한 형태이며, 이는 모델을 초기화하고 기본적인 태스크 수행 능력을 부여한다. 둘째, 인간 교사의 직접 시연을 통한 모방학습 단계이다. 에이전트가 실제 사용자와 대화하면서 오류를 범하면, 사용자는 해당 턴의 올바른 슬롯 값과 행동을 직접 제공한다. 이러한 교정 샘플은 기존 데이터셋에 누적되어 D←D∪Dπ 형태로 확장되고, 모델은 다시 지도학습으로 전체 데이터를 재학습한다. 이 과정은 DAgger(데이터 집합 집계)와 유사하지만, 인간 교정 비용을 최소화하기 위해 모든 턴이 아니라 오류가 발생한 턴에만 교정을 요구한다. 셋째, 모방학습이 충분히 진행된 후에는 간단한 이진 피드백(성공/실패)만을 수집해 정책을 강화학습으로 미세조정한다. 보상은 대화 성공 여부와 길이 페널티를 포함하며, 정책 그라디언트는 REINFORCE 기반으로 추정된다.
핵심 통찰은 ‘인간 교정’ 단계가 상태 분포 전이 문제를 효과적으로 완화한다는 점이다. 사전학습 단계에서 학습되지 않은 드문 상태에 진입했을 때, 강화학습만으로는 탐색 비용이 크게 증가하지만, 인간이 직접 올바른 행동을 제시하면 모델은 해당 상태에 대한 올바른 행동을 빠르게 학습한다. 또한, 인간 교정이 정책 네트워크뿐 아니라 슬롯 트래킹에도 직접적인 레이블을 제공하므로, 오류 전파를 근본적으로 차단한다. 실험에서는 교정 횟수를 제한했음에도 불구하고 초기 성공률이 크게 상승했으며, 이후 강화학습을 적용했을 때 최종 성공률이 추가로 5~10% 정도 향상된 것으로 보고된다.
이 접근법은 데이터 효율성 측면에서도 의미가 크다. 완전한 강화학습 기반 온라인 학습은 수천 번의 대화가 필요하지만, 인간 교정은 몇 백 번의 대화만으로도 충분히 상태 커버리지를 확장한다. 또한, 정책 네트워크와 슬롯 트래커를 하나의 엔드‑투‑엔드 파이프라인으로 통합함으로써 모듈 간 비동기 최적화 문제를 회피하고, 전체 시스템을 한 번에 미분 가능하게 만든 점도 주목할 만하다. 다만, 템플릿 기반 NLG에 의존하는 점은 자연스러운 언어 변형 능력을 제한하고, 실제 서비스 환경에서는 사용자 피드백을 실시간으로 수집·처리하는 인프라가 필요하다는 한계가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기