목소리 마이크로폰 녹음 품질 향상을 위한 GMM 기반 확률적 추정 기법
초록
목소리 마이크로폰은 피부 접촉을 통해 환경 소음에 강하지만, 음성 품질이 떨어져 자연스럽지 않은 소리를 생성합니다. 본 연구는 목소리 마이크로폰과 일반 음향 마이크로폰의 동시 녹음을 분석하여, 음소 의존적 가우시안 혼합 모델(GMM) 기반의 스펙트럼 엔벨로프 및 여기 신호 매핑 기법을 제안합니다. 이를 통해 목소리 마이크로폰의 누락된 주파수 대역을 복원하고 음질을 개선하였으며, 로그 스펙트럼 왜곡(LSD) 및 PESQ 객관 평가와 A/B 비교 청취 테스트를 통해 제안 기법의 우수성을 입증했습니다.
상세 분석
본 논문은 목소리 마이크로폰(TM)의 근본적인 음질 한계를 해결하기 위한 정교한 신호 처리 기법을 제시합니다. 핵심 기여는 음성의 소스-필터 모델을 기반으로, 스펙트럼 엔벨로프와 여기 신호를 별도로 모델링하고 개선하는 ‘음소 의존적’ 매핑 전략을 도입한 점입니다.
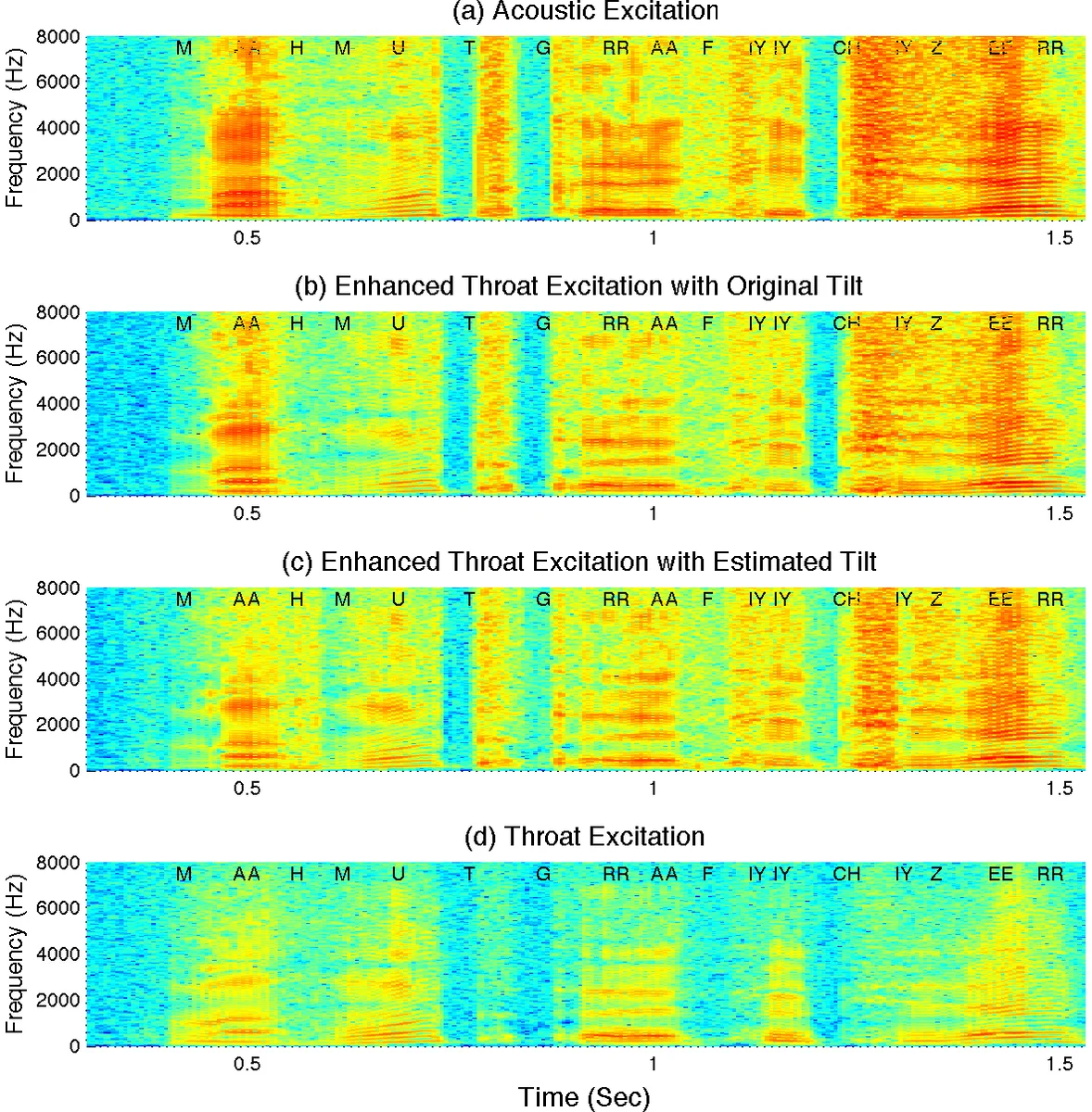
기존 연구들이 주로 필터(스펙트럼 엔벨로프) 매핑에 집중했다면, 본 연구는 음질 열화의 중요한 원인으로 여기 신호의 스펙트럼 특성 차이(스펙트럼 틸트)를 새롭게 규명하고 이를 별도의 GMM 모델로 학습하여 보정합니다. 이는 음성 생성 과정을 보다 세분화하여 접근함으로써, 단순한 스펙트럼 변환이 아닌 생리학적/음향학적 결함을 보상하는 데 초점을 맞춘 것입니다.
제안하는 시스템의 기술적 핵심은 다음과 같습니다:
- 음소 의존적 모델링: 모든 음소를 동일하게 처리하는 기존 GMM 매핑과 달리, 발음 위치(양순음, 치경음 등)에 따라 8개의 음성학적 속성 클래스로 구분하여 별도의 GMM 매핑 함수를 학습합니다. 이는 목소리 마이크로폰 신호의 왜곡 패턴이 음소별로 상이하다는 관찰에 기반하여, 보다 정확한 변환을 가능하게 합니다.
- MMSE 추정기 적용: 최소 평균 제곱 오차(MMSE) 기준으로 목표 음향 마이크로폰(AM)의 스펙트럼 엔벨로프를 추정하는 확률적 매핑을 수행합니다.
- 계층적 개선 프레임워크: 먼저 스펙트럼 엔벨로프를 매핑으로 개선한 후, 개선된 필터를 사용하여 여기 신호를 추출하고, 해당 여기 신호의 스펙트럼 틸트를 다시 GMM 기반으로 매핑하여 보정하는 2단계 방식을 채택합니다.
실험 평가는 객관적(LSD, PESQ) 및 주관적(A/B 테스트) 방법으로 철저히 진행되었으며, 제안된 ‘음소 의존적 소프트 매핑(PD-SM)’ 방식이 음소 무관 전체 GMM 매핑이나 다른 음소 의존적 하드 매핑 방식보다 모든 평가 지표에서 일관되게 우수한 성능을 보였습니다. 이는 음성 인식뿐만 아니라 실제 음질 향상을 위한 목소리 마이크로폰 신호 처리 연구의 중요한 진전을 의미합니다.
댓글 및 학술 토론
Loading comments...
의견 남기기