대규모 HPC 작업을 위한 동적 작업 묶음 및 백필링
초록
본 논문은 슈퍼컴퓨터에서 작은 규모의 Lattice QCD 작업을 대형 파티션에 맞게 묶어 효율을 높이는 방법을 제시한다. METAQ와 mpi_jm이라는 두 가지 백필링 프레임워크를 소개하고, 각각의 설계 원리와 한계를 분석한다.
상세 분석
고성능 컴퓨팅(HPC) 환경에서는 자원 활용률을 높이기 위해 일정 규모 이상의 작업에 인센티브를 제공한다. 그러나 Lattice QCD와 같이 개별 작업이 수백 노드 이하에서 최적화된 경우, 수천 노드 규모의 파티션에 그대로 투입하면 CPU·GPU가 대부분 유휴 상태가 되거나 통신 오버헤드가 급증한다. 저자들은 이러한 비효율을 해소하기 위해 “작업 묶음(task bundling)”과 “백필링(backfilling)” 전략을 도입한다.
첫 번째 시도인 METAQ는 Bash 스크립트 기반으로, 사용자가 #METAQ 메타데이터를 포함한 작업 파일을 지정된 디렉터리에 두면, 배치 스케줄러가 할당받은 노드에서 가능한 작업을 순차적으로 실행한다. 이 방식은 기존 워크플로우를 크게 변경하지 않으면서도, 작업별 요구 자원(노드 수, 예상 실행 시간)을 명시하도록 함으로써 단순 나이브 번들링보다 낭비를 줄인다. 그러나 METAQ는 사용자 신뢰에 의존해 자원 요구를 강제하지 못하고, 작업을 다른 규모로 재구성하거나 GPU와 CPU를 독립적으로 할당하는 유연성이 부족하다. 또한 백필링 로직이 서비스 노드에서 실행돼 대규모 작업 시 서비스 노드 과부하와 시스템 다운 위험이 있다.
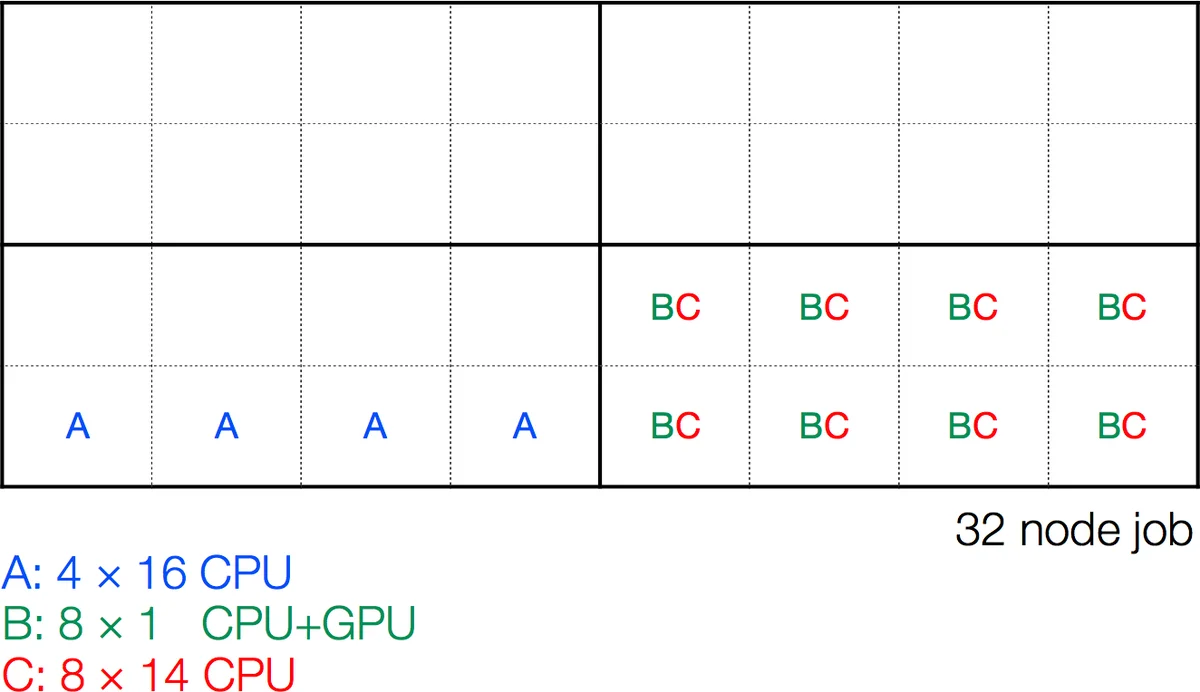
이를 보완하기 위해 제안된 mpi_jm은 MPI 기반 데몬을 각 노드에 배치하고, 할당된 노드를 “블록” 단위로 분할한다. 블록은 네트워크 토폴로지를 고려해 물리적으로 인접한 노드들로 구성되며, 각 블록은 자체 커뮤니케이터를 통해 작업 스케줄러와 통신한다. 작업은 YAML 파일로 정의되며, Python 인터페이스를 통해 동적으로 생성·제어된다. mpi_jm은 작업 실행 시 MPI_Comm_spawn을 이용해 새로운 프로세스를 생성하고, 두 단계의 핸드쉐이크를 통해 오류가 발생해도 전체 작업이 중단되지 않도록 설계되었다. 이 구조는 GPU·CPU 바인딩, 메모리 대역폭 경쟁 완화 등 세밀한 자원 할당을 가능하게 하며, 서비스 노드에 부하를 주지 않고 컴퓨트 노드 자체에서 스케줄링을 수행한다.
두 시스템 모두 작업의 예상 실행 시간을 입력으로 받아 최적 순서를 계산하지만, mpi_jm은 블록 기반 자원 파편화 문제를 최소화하고, 네트워크 성능을 고려한 배치를 제공한다. 또한 Python 기반 인터페이스는 그래프 데이터베이스 연동, 자동 데이터 분석 파이프라인 등 확장성을 크게 높인다. 이러한 설계는 향후 엑사스케일 시대에 작은 문제 인스턴스가 대규모 노드에 걸쳐 실행되는 상황에서도 자원 낭비 없이 효율적인 과학 계산을 지원한다.
댓글 및 학술 토론
Loading comments...
의견 남기기