BinarEye: 언제든 켜지는 초저전력 바이너리 CNN 프로세서
초록
BinarEye는 28 nm CMOS 공정으로 구현된 디지털 바이너리 CNN 가속기로, 온‑칩 259 kB 가중치 SRAM과 2 × 32 kB 활성화 SRAM을 통해 모델과 피처 맵을 완전 저장한다. 로컬 플립플롭 기반 뉴런 배열은 가중치를 한 번만 로드해 재사용함으로써 데이터 이동을 최소화하고, 230 TOPS/W(1 bit) 피크 효율을 달성한다. 가중치 재구성, 네트워크 깊이·폭 프로그래밍이라는 3단계 유연성을 제공해 에너지와 정확도 사이를 자유롭게 조정한다. CIFAR‑10(86 % 정확도)에서는 14.4 µJ/프레임, 얼굴 검출(94 % 정확도)에서는 0.92 µJ/프레임, 최대 1.7 kFPS의 실시간 처리능력을 보인다. 기존 최첨단 솔루션 대비 3‑70배 높은 에너지 효율을 기록한다.
상세 분석
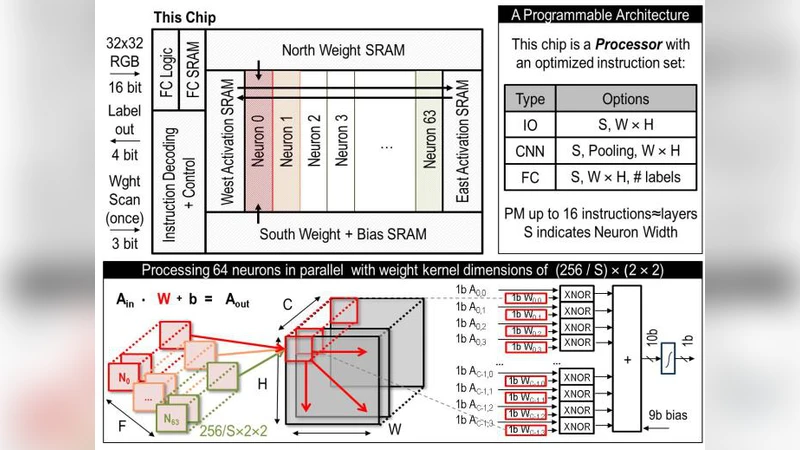
BinarEye는 바이너리 신경망(BNN) 특성을 극대화한 설계 철학을 갖는다. 가중치와 활성화가 +1/‑1 로 양자화되면 곱셈 연산이 XNOR 연산으로 대체되고, 팝카운트와 임계값 비교만으로 출력이 결정된다. 이를 기반으로 설계자는 64개의 뉴런을 1비트 플립플롭에 저장하는 ‘뉴런 배열’을 구현했으며, 이 배열은 메모리‑컴퓨팅 구조와 동일한 물리적 위치에 존재한다. 가중치는 북·남쪽 SRAM에서 한 번 로드해 로컬 플립플롭에 저장되면, 전체 컨볼루션 동안 재사용되므로 메모리 대역폭 요구가 극도로 낮아진다. 특히 2×2 커널을 고정하고 입력 피처를 2비트씩만 읽어 들여도 충분히 연산을 수행할 수 있어, 데이터 이동 에너지를 최소화한다.
유연성 측면에서 BinarEye는 세 가지 레벨을 제공한다. 첫째, 온‑칩 SRAM에 저장된 가중치를 언제든 재프로그래밍할 수 있어 다양한 애플리케이션에 맞게 모델을 교체한다. 둘째, 16개의 명령어를 저장하는 프로그램 메모리를 통해 네트워크 깊이(레이어 수)를 자유롭게 구성한다. 셋째, ‘배치 크기 S’를 조절해 네트워크 폭(F, C)을 256/S 로 축소하거나 확대한다. S=1이면 256채널 전체를 한 번에 처리해 높은 정확도를 얻지만 4단계의 LD‑CONV 사이클이 필요하고, S=4이면 64채널만 사용해 LD‑CONV 사이클을 한 번으로 줄여 에너지와 처리량을 16배(=S²) 향상시킨다. 이러한 트레이드오프는 실제 실험에서 CIFAR‑10, 얼굴 검출, 소유자 인식 등에서 다양한 정확도‑전력 포인트를 제공한다.
칩은 28 nm CMOS에서 1.5‑48 MHz, 0.66‑0.9 V 구동되며, 피크 코어 효율 230 TOPS/W, 전체 I/O 포함 효율 145 TOPS/W를 달성한다. 전력 소모는 최소 1.6‑2.2 mW이며, 1 mm² 이하 면적에 2 mm² 다이 전체를 구현한다. 비교 실험에서는 YodaNN, BRein Memory, Envision, IBM TrueNorth 등 기존 저전력 CNN 가속기 대비 에너지당 추론 비용이 3‑70배 낮으며, 동일 정확도 수준에서 처리량도 크게 앞선다.
결과적으로 BinarEye는 ‘메모리‑컴퓨팅 + 온‑칩 전체 모델 저장 + 다중 레벨 유연성’이라는 세 축을 결합해, 배터리 구동 웨어러블 디바이스에서 항상‑켜진 비전 감지(얼굴, 소유자, 객체 인식)를 실현할 수 있는 실용적인 솔루션을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기