엔드투엔드 화자 및 언어 인식 시스템의 인코딩 레이어와 손실 함수 탐구
본 논문은 가변 길이 음성 입력을 받아 발화 수준의 표현을 생성하는 통합 엔드투엔드 프레임워크를 제안한다. 평균 풀링, 자기‑주의 풀링, 학습 가능한 사전 인코딩(LDE) 세 가지 인코딩 레이어를 비교하고, 개방형 화자 검증을 위해 중심 손실과 각도‑소프트맥스 손실을 도입한다. VoxCeleb와 NIST LRE 07 실험을 통해 제안된 인코딩 및 손실 함수가 기존 방법보다 성능을 크게 향상시킴을 입증한다.
저자: Weicheng Cai, Jinkun Chen, Ming Li
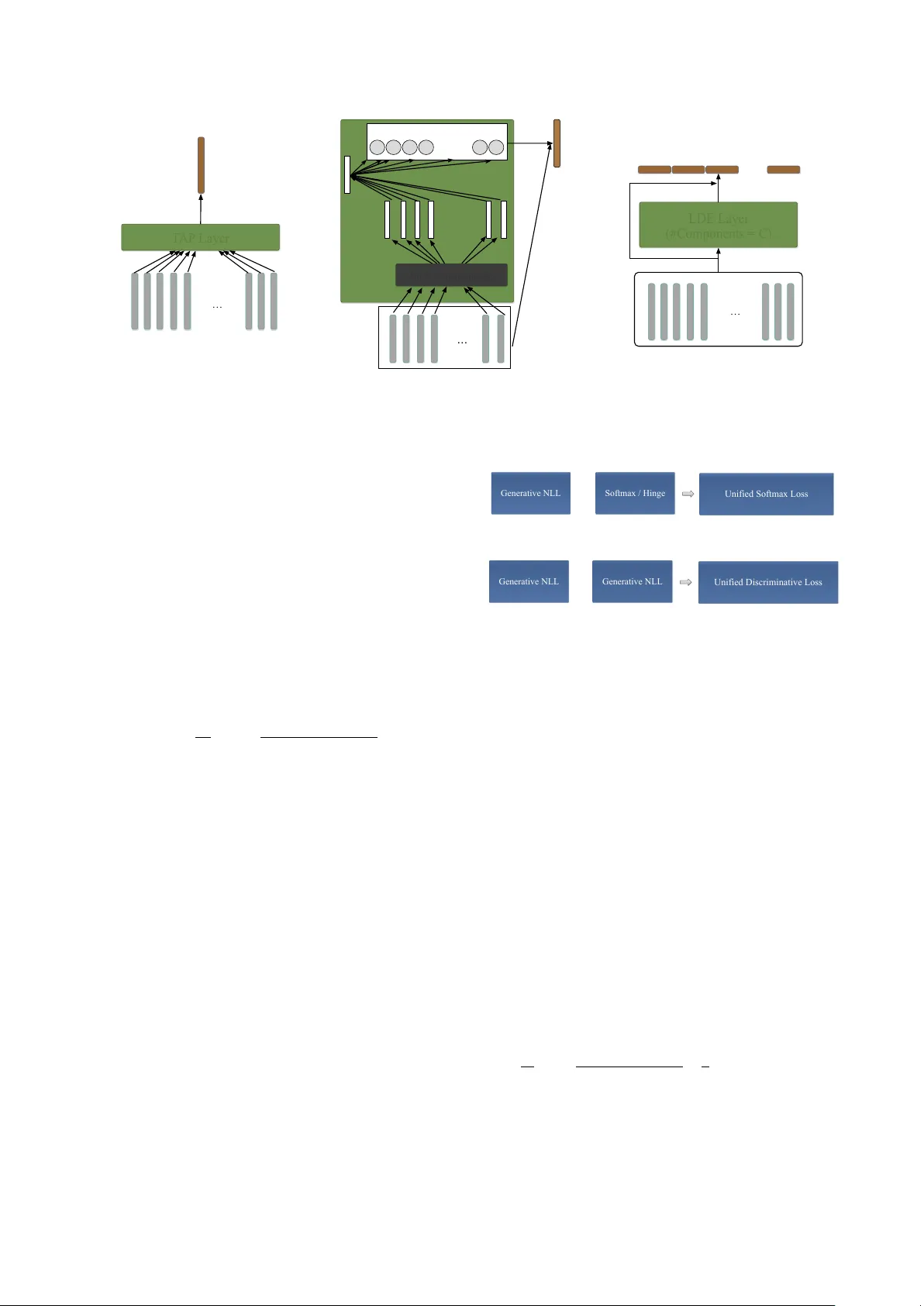
본 논문은 가변 길이 음성 신호를 입력으로 받아 발화 수준의 고정 차원 벡터를 출력하는 통합 엔드투엔드 프레임워크를 제안한다. 기존의 화자 및 언어 인식 시스템은 특징 추출, 사전 학습, 벡터 인코딩, 판별기 등 네 단계로 구성된 파이프라인을 사용했으며, 각 단계가 별도로 최적화돼 전체 시스템의 복잡성과 성능 한계를 야기했다. 저자들은 이러한 구조적 제약을 없애고, CNN 기반 프레임‑레벨 특징 추출기 위에 단일 인코딩 레이어를 두어 전체 과정을 하나의 신경망으로 학습한다는 아이디어를 제시한다.
인코딩 레이어는 세 가지 변형을 포함한다. 첫 번째는 Temporal Average Pooling(TAP)으로, 모든 프레임을 동일 가중치로 평균해 간단히 고정 차원 벡터를 만든다. 두 번째는 Self‑Attentive Pooling(SAP)로, 프레임별 특징을 MLP에 통과시켜 은닉 표현 hₜ를 얻고, 학습 가능한 컨텍스트 벡터 µ와의 내적을 소프트맥스에 적용해 가중치 wₜ를 산출한다. 최종 발화 벡터는 wₜ와 원본 특징 xₜ의 가중합으로 구성되며, 중요한 프레임에 더 큰 비중을 부여한다. 세 번째는 Learnable Dictionary Encoding(LDE) 레이어이다. LDE는 K개의 사전 중심 µ₁…µ_C와 각 중심별 스무딩 파라미터 s_c를 학습 파라미터로 두고, 입력 프레임을 소프트맥스 기반 가중치 wₜc=exp(−s_c‖xₜ−µ_c‖²) 로 모든 중심에 할당한다. 이후 각 중심에 대한 잔차 rₜc=xₜ−µ_c와 가중치의 가중합을 통해 클러스터별 인코딩 e_c를 구하고, 이를 연결해 최종 발화 벡터를 만든다. LDE는 전통적인 GMM‑Supervector와 동일한 통계적 의미를 가지면서도 전 과정이 미분 가능해 엔드투엔드 학습이 가능하다.
손실 함수는 두 가지 시나리오에 맞춰 설계되었다. 폐쇄형(classification) 과제에서는 일반적인 소프트맥스 손실을 사용한다. 그러나 개방형 화자 검증에서는 클래스 간 거리와 클래스 내부 응집력을 동시에 고려해야 한다. 이를 위해 Center Loss와 Angular Softmax(A‑Softmax) 손실을 도입한다. Center Loss는 각 클래스별 중심 c_y를 학습하고, 특징 f(x)와 해당 중심 사이의 유클리드 거리를 최소화해 intra‑class 변동을 억제한다. λ 파라미터로 소프트맥스와의 비중을 조절한다. A‑Softmax는 특징을 정규화하고 각도 기반 마진 m을 적용해 클래스 간 각도 차이를 확대한다. 이는 구면상에서의 지오데식 거리와 동일한 판별력을 제공한다. 두 손실을 소프트맥스와 결합함으로써, 네트워크는 개방형 검증에서도 강력한 메트릭 학습 능력을 갖춘다.
실험은 두 개의 공개 데이터셋을 사용한다. 화자 인식은 대규모 VoxCeleb 데이터셋을, 언어 인식은 NIST LRE 07을 대상으로 한다. 각 인코딩 레이어와 손실 조합에 대해 평균 오류율(EER) 및 식별 정확도를 측정한다. 결과는 TAP 대비 SAP가 약 1%~2%의 EER 감소를 보였으며, LDE가 가장 큰 개선을 제공한다. 특히 LDE와 Center Loss를 결합했을 때 EER가 2.3%까지 낮아졌다. 언어 인식에서도 LDE+A‑Softmax 조합이 기존 i‑vector 기반 시스템보다 높은 정확도를 달성했다. 이러한 결과는 전통적인 GMM‑i‑vector 파이프라인을 대체할 수 있는, 보다 간결하고 효율적인 엔드투엔드 솔루션임을 입증한다.
결론적으로, 본 연구는 (1) 가변 길이 입력을 처리할 수 있는 통합 인코딩 레이어 설계, (2) 개방형 검증을 위한 차별적 손실 함수 도입, (3) 실제 대규모 데이터에서의 성능 검증이라는 세 축을 통해 엔드투엔드 화자 및 언어 인식 시스템의 새로운 패러다임을 제시한다. 향후 연구에서는 더 복잡한 어텐션 메커니즘, 다중 모달 입력, 그리고 실시간 배포를 위한 경량화 모델 등에 대한 확장이 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기