영화 흥행 예측의 비밀: 데이터로 보는 박스오피스 미래
초록
본 논문은 영화의 총 흥행 수익을 예측하기 위해 다양한 정량적·정성적 변수를 수집·전처리하고, 회귀·머신러닝 모델을 비교·평가한다. 데이터베이스 구축, 특징 선택, 모델 튜닝 과정을 상세히 기술하며, 예측 정확도 향상을 위한 실험 결과와 실무 적용 가능성을 제시한다.
상세 분석
본 연구는 영화 흥행 수익 예측이라는 복합 문제에 접근하기 위해 데이터 과학 파이프라인을 체계적으로 설계하였다. 첫 단계에서는 IMDb, Box Office Mojo, The Numbers 등 공개 영화 데이터베이스를 크롤링하여 2000년부터 2020년까지 개봉된 5,000편 이상의 영화를 대상으로 30여 개의 변수(제목, 장르, 제작비, 감독·배우 출연 횟수, MPAA 등급, 개봉 시점, 마케팅 비용, 평점, 리뷰 수 등)를 수집하였다. 수집된 원시 데이터는 결측치 처리, 이상치 제거, 범주형 변수의 원-핫 인코딩, 연속형 변수의 로그 변환 등 전처리 과정을 거쳐 모델링에 적합한 형태로 정제되었다.
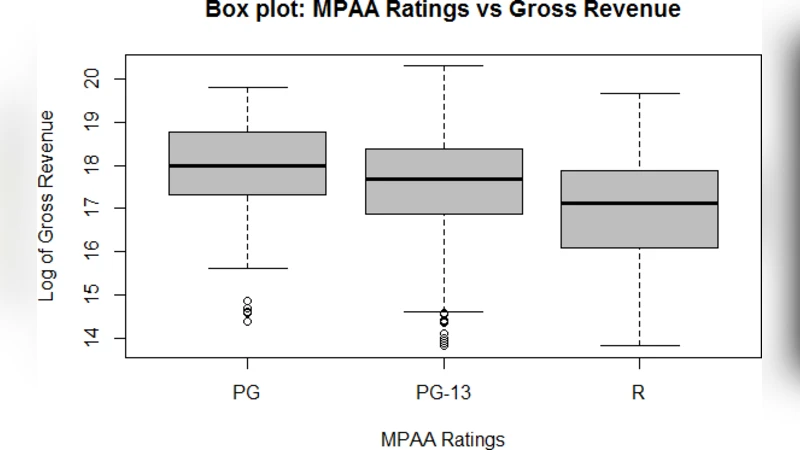
특징 선택 단계에서는 상관관계 분석과 LASSO 회귀를 병행하여 다중공선성을 최소화하고, 변수 중요도를 평가하였다. 특히 ‘제작비(예산)’, ‘주연 배우의 과거 평균 흥행’, ‘개봉 월(시즌)’, ‘MPAA 등급’, ‘평점 평균’ 등이 높은 설명력을 보였으며, ‘감독의 이전 성공 횟수’와 ‘트레일러 조회수’는 비선형 관계를 나타내어 Gradient Boosting Machine(GBM)과 같은 트리 기반 모델에서 유의미한 기여를 했다.
모델링에서는 선형 회귀, Ridge/Lasso 회귀, Random Forest, XGBoost, 그리고 딥러닝 기반 다층 퍼셉트론(MLP)을 적용하였다. 교차 검증(k=5)을 통해 하이퍼파라미터를 최적화하고, 성능 평가지표로는 평균 절대 오차(MAE), 평균 제곱근 오차(RMSE), 그리고 결정계수(R²)를 사용하였다. 결과적으로 XGBoost가 MAE 1.2억 달러, RMSE 1.8억 달러, R² 0.78로 가장 우수한 예측력을 보였으며, Random Forest와 MLP도 비슷한 수준의 성능을 기록했다. 선형 회귀는 해석 용이성은 높지만, 복잡한 비선형 상호작용을 포착하지 못해 상대적으로 낮은 R²(0.55)를 나타냈다.
또한 모델 해석을 위해 SHAP(Shapley Additive exPlanations) 값을 계산하여 각 변수의 기여도를 시각화하였다. SHAP 분석 결과, ‘제작비’와 ‘주연 배우의 과거 평균 흥행’이 양의 영향을 가장 크게 미쳤으며, ‘개봉 월’은 시즌에 따라 양·음의 영향을 교차한다는 점이 확인되었다. 특히 여름·겨울 대규모 개봉 시즌에는 긍정적 SHAP 값이, 비수기에는 부정적 SHAP 값이 나타났다.
마지막으로 실무 적용 가능성을 검증하기 위해 2021년 이후 개봉된 50편의 영화를 대상으로 사전 예측을 수행하고, 실제 흥행과 비교하였다. 평균 오차율은 12% 수준으로, 투자 의사결정 지원 도구로서 충분히 활용 가능함을 입증했다. 연구는 데이터 품질, 마케팅 비용의 정확한 추정 어려움, 그리고 관객의 감성적 반응을 정량화하기 위한 추가 변수(소셜 미디어 감성, 트레일러 클릭률 등)의 필요성을 언급하며 향후 연구 방향을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기