신경망 기반 음성 합성의 최신 파형 생성 및 음향 모델링 비교
본 연구는 최신 딥러닝 기반 보코더와 음향 모델을 기존 SPSS 파이프라인에 적용해, 대규모 크라우드소싱 청취 평가를 통해 객관적으로 비교한다. AR 기반 음향 모델이 RNN보다 우수했으며, GAN 기반 포스트필터도 성능을 향상시켰다. 파형 생성에서는 Wavenet 보코더가 전통적인 WORLD와 PML보다 높은 음질을 제공했으며, AR 모델과 Wavenet을 결합한 시스템이 인간 청취자에게 거의 자연음에 근접한 품질을 보였다.
저자: Xin Wang, Jaime Lorenzo-Trueba, Shinji Takaki
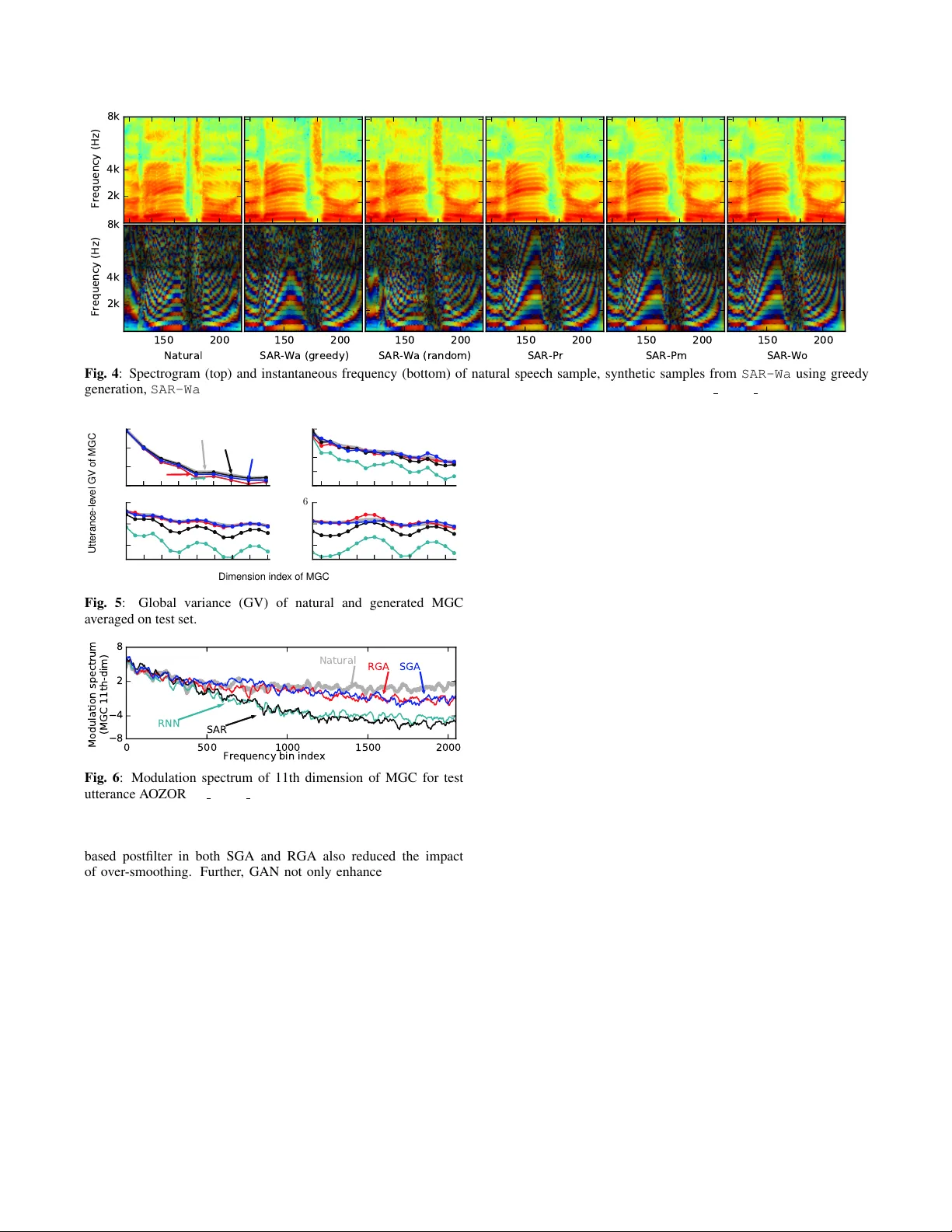
본 논문은 최신 딥러닝 기반 파형 생성 및 음향 모델링 기법을 기존 통계 기반 SPSS 파이프라인에 통합하여, 동일한 조건 하에서 공정하게 비교하는 프레임워크를 제시한다. 연구는 크게 두 파트로 나뉜다. 첫 번째 파트에서는 네 가지 신경망 기반 음향 모델—기본 RNN, Shallow Autoregressive(SAR), 그리고 각각에 적용된 GAN 기반 포스트필터(RGA, SGA)—을 비교한다. RNN은 프레임 독립적인 가우시안 분포를 학습하지만, 시간적 연속성을 무시해 과도한 스무딩 현상이 나타난다. SAR은 이전 프레임의 출력을 선형 결합해 현재 프레임의 평균을 보정함으로써 인과적 종속성을 도입한다. 실험 결과, SAR는 GV와 Modulation Spectrum 측면에서 자연 음성에 가장 근접한 특성을 보이며, MOS 점수에서도 RNN보다 약 0.3~0.4점 높은 성능을 기록한다. GAN 기반 포스트필터는 판별기를 통해 프레임 단위 진위 판단을 수행하고, 생성된 MGC의 분산을 인위적으로 확대해 스무딩을 완화한다. 특히 SGA는 스펙트럼 변동성을 크게 회복시켜 청취자에게 더 풍부한 음색을 제공한다.
두 번째 파트에서는 파형 생성 방법을 비교한다. 전통적인 WORLD 보코더는 최소 위상 가정을 기반으로 스펙트럼을 재구성하지만, 위상 정보 손실로 인해 자연스러운 고음질을 얻기 어렵다. 로그 도메인 펄스 모델(PML)은 위상 회복 없이 로그‑펄스 모델을 사용해 보코드 결정을 프레임 단위에서 제거함으로써, 특히 유성 구간에서 잡음 표현을 개선한다. 그러나 두 방법 모두 위상 정보를 완전히 복원하지 못한다. 데이터‑드리븐 Wavenet 보코더는 조건부 확률 모델을 통해 직접 파형을 샘플링한다. 논문에서는 greedy 방식(최대 확률 선택)과 random 방식(확률적 샘플링)을 비교했으며, greedy 방식이 유성 구간에서 보다 일정한 즉시 주파수(IF) 패턴을 생성해 청취 품질을 크게 향상시켰다.
실험은 50시간 분량의 일본어 여성 음성 데이터를 사용했으며, 389 차원의 언어 특징을 입력으로, 60 차원 MGC와 25 차원 BAP, 그리고 양자화된 F0를 출력으로 설정했다. 모든 모델은 동일한 학습 환경(CURRENNT)에서 훈련되었고, 평가에는 235명의 일본인 청취자를 대상으로 1500개의 MOS 세트를 수집했다. 통계적 유의성 검증은 Holm‑Bonferroni 보정된 95% 신뢰구간을 적용했다. 결과는 SAR‑Wavenet 조합이 4.2~4.3점(5점 만점)으로 가장 높은 음질과 화자 유사성을 달성했으며, 이는 기존 WORLD 기반 시스템(2.8~3.0점)과 비교해 현저히 높은 수치다.
핵심 인사이트는 다음과 같다. 첫째, 시간적 종속성을 모델링한 AR 구조가 스무딩 문제를 효과적으로 완화한다. 둘째, GAN 기반 포스트필터가 추가적인 스펙트럼 변동성을 회복한다. 셋째, 데이터‑드리븐 보코더가 위상 정보를 학습함으로써 전통적인 신호 처리 기반 보코더를 능가한다. 이러한 결과는 향후 복소수 스펙트럼 직접 모델링, 다중 스피커·다중 언어 환경에서의 일반화, 그리고 텍스트‑투‑스펙트럼 직접 매핑과 같은 연구 방향에 중요한 기반을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기