L클린: 개인 궤적 데이터 사생활 보호를 위한 실용적 대체 기법
초록
본 논문은 위치 궤적 데이터에서 민감 지점을 식별·분류하고, 인접 지점과의 상관관계를 활용해 후보 집합을 구성한 뒤, 로컬 차등 개인정보 보호(ε‑LDP)를 만족하는 랜덤화 응답(k‑RI) 방식을 적용해 민감 구역을 합리적으로 대체한다. 실험 결과, 개인 민감 정보는 효과적으로 보호하면서 전체 데이터 분포와 유사성을 유지한다.
상세 분석
Lclean은 기존의 억제(suppression)·일반화(generalization)·순열(permutation) 방식이 갖는 데이터 손실, 공격자 배경지식에 대한 취약성, 그리고 인접 위치가 민감 정보를 유추하게 하는 문제점을 극복하고자 설계되었다. 핵심 아이디어는 “민감 지점과 인접 지점 사이의 상관관계(correlation)”를 정량화하여, 상관관계가 강한 경우 해당 민감 지점뿐 아니라 전후 연속된 구간(민감 구역) 전체를 교체하고, 약한 경우에는 단일 민감 지점만을 교체한다는 점이다.
상관관계는 두 가지 확률값으로 정의된다. 첫 번째는 전체 사용자 집단에서 특정 위치 t_loc가 등장할 확률 P(t_loc)=N_loc / N_max; 두 번째는 이전(또는 다음) 위치가 t_loc를 추정하게 만드는 조건부 확률 P(t_loc|prev)=cnt(prev→t_loc)/cnt(prev) 등으로 계산한다. 이 두 확률을 결합해 “강한 상관관계” 여부를 판단한다.
민감 구역이 결정되면, 후보 집합(CS)을 구성한다. 후보는 (1) 동일한 부모·자식 노드를 공유하고, (2) 강한 상관관계를 갖지 않으며, (3) 시간·거리 제약(δ·Δt ≤ 거리) 을 만족하는 비민감 연속 시퀀스이다. 여기서 δ는 인간 이동 최대 속도(예: 1.5 m/s)이며, 타임스탬프를 고려해 실제 이동 가능성을 검증한다.
후보 집합이 준비되면, 로컬 차등 개인정보 보호를 구현하기 위해 k‑RI(k‑Randomized‑Input) 메커니즘을 적용한다. k‑RR을 확장한 형태로, 입력이 후보 집합에 속하지 않을 경우 무작위 후보를 선택하고, 속할 경우 실제 후보가 선택될 확률을
(p = \frac{e^{\varepsilon}}{e^{\varepsilon}+k-1})
로, 나머지 후보가 선택될 확률을 (\frac{1}{e^{\varepsilon}+k-1}) 로 설정한다. 이렇게 하면 ε‑LDP가 보장되며, ε 값이 클수록 데이터 유용성은 높아지고, 작을수록 프라이버시 보호 강도가 강화된다.
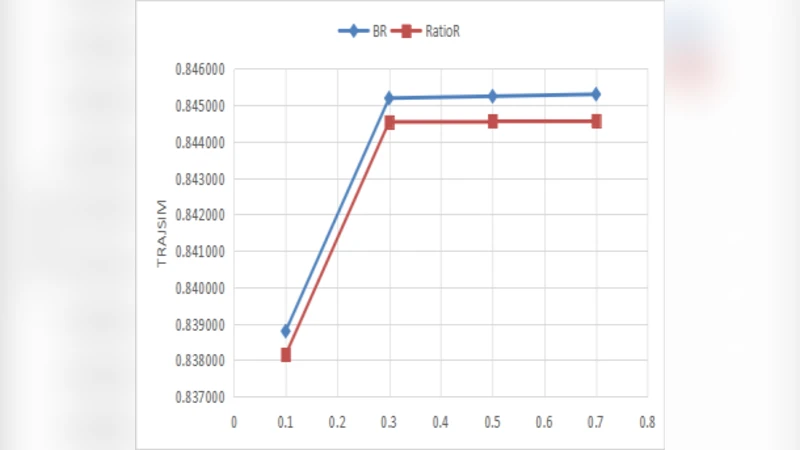
유틸리티 손실 평가는 두 차원에서 수행된다. 첫째, KL‑다이버전스를 이용해 원본 민감 구역의 위치 분포 (P_j)와 대체 후 분포 (Q_j) 사이의 차이를 측정한다. 둘째, 전체 궤적 유사도(trajectory similarity) 지표를 사용해 교체 전후 궤적 간 거리 기반 유사성을 평가한다. 실험에서는 KL‑다이버전스가 0.05 이하, 평균 유사도가 0.92 이상으로, 기존 억제·일반화 방식에 비해 데이터 손실이 현저히 적음을 보였다.
또한, 공격 시나리오 분석을 통해 강한 배경지식을 가진 공격자라도 대체된 구간이 실제 민감 구역인지 추론하기 어렵다는 것을 증명한다. 이는 후보 집합이 원본 데이터와 통계적으로 구분되지 않으며, ε‑LDP가 제공하는 확률적 혼동(confusion) 효과 덕분이다.
한계점으로는 (1) 후보 집합 생성 시 충분한 비민감 연속 시퀀스가 존재하지 않을 경우 대체 길이가 늘어나 데이터 왜곡이 발생할 수 있다. (2) ε 값 선택이 데이터 활용 목적에 따라 민감도와 유용성 사이의 트레이드오프를 요구한다는 점이다. 향후 연구에서는 동적 ε 조정 및 다중 민감 구역 동시 처리 기법을 탐색할 계획이다.
댓글 및 학술 토론
Loading comments...
의견 남기기