스피치 체인에 원샷 화자 적응을 결합한 다중화자 학습 모델
초록
본 논문은 기존 스피치 체인 모델에 화자 인식 모듈을 삽입하고, DeepSpeaker 기반 원샷 화자 적응을 적용한 TTS를 제안한다. 라벨이 있는 데이터와 라벨이 없는 데이터(음성·텍스트)를 동시에 활용해 ASR과 TTS를 상호 학습시키는 반지도학습 프레임워크를 구축했으며, WSJ 데이터셋 실험에서 인식 오류율(CER)을 크게 낮추었다.
상세 분석
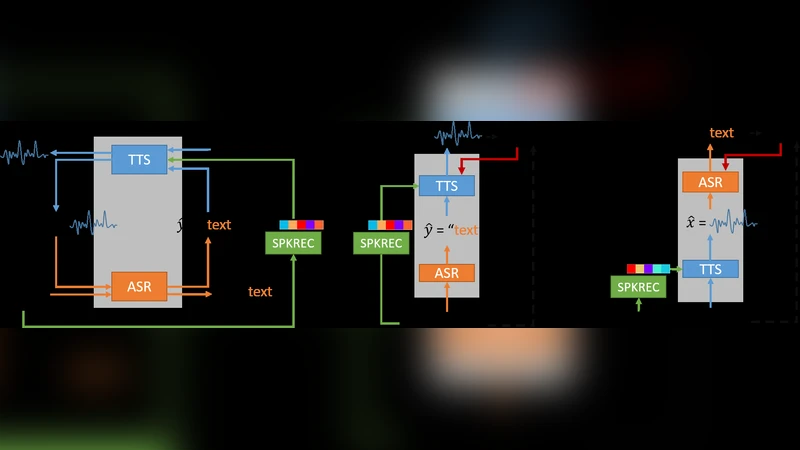
이 연구는 “스피치 체인”이라는 폐쇄 루프 구조를 확장하여 화자 정보를 효율적으로 전달한다는 점에서 의미가 크다. 기존 모델은 화자 ID를 원-핫 인코딩으로만 제공했으며, 미지의 화자에 대한 일반화가 어려웠다. 저자들은 DeepSpeaker라는 화자 임베딩 네트워크를 별도 모듈로 도입해, 입력 음성으로부터 L2 정규화된 연속 벡터 z를 추출한다. 이 벡터는 Tacotron 기반 TTS 디코더에 결합되어, 단 한 번의 샘플(원샷)만으로도 새로운 화자의 음성 특성을 재현한다. 따라서 TTS는 화자 정보가 전혀 없는 텍스트 입력에서도, 사전 학습된 화자 임베딩을 샘플링해 음성 합성을 수행한다.
ASR 측면에서는, 음성 → ASR → 텍스트 + 화자 벡터 → TTS → 재생성 음성 흐름을 통해 비지도 데이터에서도 라벨을 ‘전파’한다. 구체적으로, 비라벨 음성 데이터(DU)에서는 ASR이 텍스트를 예측하고, SPKREC가 화자 벡터를 추출한다. 이후 TTS가 예측 텍스트와 화자 벡터를 이용해 음성을 재구성하고, 재구성된 음성과 원본 음성 사이의 L2 손실을 역전파한다. 반대로 비라벨 텍스트 데이터에서는 임의의 음성 샘플을 선택해 화자 벡터를 얻고, TTS가 음성을 생성한 뒤 ASR이 이를 다시 텍스트로 복원한다. 이렇게 두 방향의 손실(L_U_ASR, L_U_TTS)을 결합해 전체 손실 L = α(L_P_ASR+L_P_TTS)+β(L_U_ASR+L_U_TTS) 로 최적화한다.
모델 구조는 다음과 같다. ASR은 3개의 Bi‑LSTM(256 hidden) 인코더와 계층적 서브샘플링을 사용해 시퀀스 길이를 1/8로 축소하고, 어텐션 기반 디코더가 문자 시퀀스를 생성한다. TTS는 Tacotron의 CBHG 인코더와 2개의 LSTM 디코더를 유지하되, 입력 문자 임베딩에 두 개의 FC 레이어와 LReLU를 적용하고, 화자 임베딩 z를 선형 변환 후 디코더 상태와 합산한다. 디코더는 멜 스펙트로그램을 출력하고, 이를 다시 CBHG를 통해 선형 스펙트로그램으로 변환한다. 손실은 멜·선형 스펙트로그램 L2 손실, 종료 프레임 바이너리 교차 엔트로피, 화자 임베딩 코사인 거리의 가중합으로 구성된다.
실험은 WSJ CSR 코퍼스를 사용했으며, SI84(83 화자, 16시간)와 SI200(200 화자, 66시간)을 각각 라벨이 있는/없는 데이터로 나누었다. 라벨이 있는 SI84만으로 감독 학습했을 때 CER는 17.01%였으나, 제안된 반지도 학습(라벨 음성+비라벨 음성+비라벨 텍스트)에서는 9.86%까지 감소했다. 이는 기존 라벨 전파 방식(14.58%)보다 크게 개선된 수치이며, TTS에서도 원샷 화자 적응을 통해 미지의 화자 음성을 자연스럽게 합성함을 청각적으로 확인했다. 전체 시스템은 PyTorch 기반으로 구현되었고, Adam 옵티마이저(ASR/TTS 5e‑4, SPKREC 1e‑3)를 사용했다.
이 논문의 핵심 기여는 (1) 화자 인식 모듈을 스피치 체인에 통합해 화자 특성을 명시적으로 전달, (2) 원샷 화자 적응을 통한 다중화자 TTS 구현, (3) 라벨이 없는 음성·텍스트 데이터를 효과적으로 활용하는 반지도 학습 프레임워크 제시이다. 이러한 접근은 실제 서비스에서 새로운 화자를 빠르게 지원하고, 라벨링 비용을 크게 절감할 수 있는 가능성을 보여준다.
댓글 및 학술 토론
Loading comments...
의견 남기기