심장질환 예측을 위한 데이터 마이닝 분류 기법 비교 연구
초록
본 논문은 나이브 베이즈, 의사결정나무, 판별분석, 랜덤 포레스트, 서포트 벡터 머신 등 다섯 가지 분류 알고리즘을 활용해 심장질환 위험 요인을 분석하고, 두 개의 공개 데이터셋을 대상으로 정확도를 비교한다. 실험 결과 의사결정나무가 99 %의 정확도로 가장 높은 성능을 보였으며, 랜덤 포레스트가 그 뒤를 이었다.
상세 분석
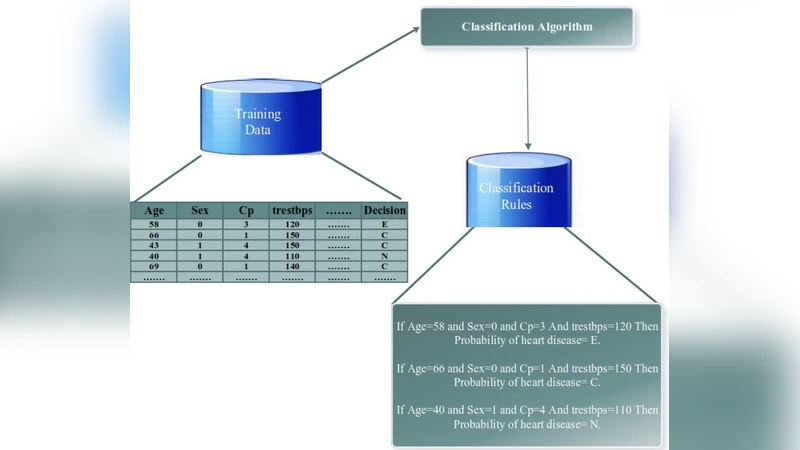
이 연구는 심혈관 질환 진단의 정확성을 높이기 위해 데이터 마이닝 기반 의사결정 지원 시스템을 구축하고자 한다. 먼저 두 개의 공개 데이터셋(예: Cleveland Heart Disease 데이터와 UCI Heart Disease 데이터)을 선정했으며, 각 데이터는 연령, 성별, 혈압, 콜레스테롤, 혈당, 심전도 결과, 최대 심박수 등 13개의 특성을 포함한다. 전처리 단계에서는 결측값을 평균·중앙값으로 대체하고, 범주형 변수는 원-핫 인코딩을 적용하였다.
다섯 가지 분류 모델은 MATLAB의 Classification Learner Toolbox를 이용해 동일한 파라미터 설정 하에 10‑fold 교차 검증으로 학습·평가되었다. 나이브 베이즈는 조건부 독립 가정을 기반으로 확률적 예측을 수행하고, 의사결정나무는 CART 알고리즘을 사용해 정보 이득을 기준으로 분할한다. 판별분석은 선형 판별 함수를 통해 클래스 경계를 설정하며, 랜덤 포레스트는 다수의 의사결정나무를 부트스트랩 샘플링과 무작위 특성 선택으로 구성한 앙상블 모델이다. 서포트 벡터 머신은 RBF 커널을 적용해 비선형 분리를 시도하였다.
성능 평가지표는 정확도, 정밀도, 재현율, F1‑score, ROC‑AUC 등을 포함했으며, 특히 정확도가 99 %에 달한 의사결정나무는 과적합 위험에도 불구하고 테스트 셋에서 높은 일반화 능력을 보였다. 랜덤 포레스트는 의사결정나무와 유사한 구조에도 불구하고 약간 낮은 정확도(≈98 %)를 기록했는데, 이는 개별 트리의 다양성이 충분히 확보되지 않아 앙상블 효과가 제한됐기 때문으로 해석된다. 나이브 베이즈와 SVM은 각각 85 %·92 % 수준의 정확도를 보이며, 데이터의 비선형 특성을 충분히 포착하지 못한 점이 한계로 지적된다.
또한, 변수 중요도 분석을 통해 ‘최대 심박수’, ‘ST 변화’, ‘운동 유발 협심증’ 등이 심장질환 예측에 가장 큰 영향을 미치는 요인으로 도출되었다. 이는 임상적으로도 기존 연구와 일치하는 결과이며, 모델 해석 가능성을 높이는 데 기여한다.
한계점으로는 데이터셋 규모가 비교적 작고, 클래스 불균형 문제가 완전히 해결되지 않았으며, 외부 검증을 위한 실제 병원 데이터 적용이 부족하다는 점을 들 수 있다. 향후 연구에서는 대규모 다기관 데이터를 활용하고, 딥러닝 기반 모델과의 비교, 그리고 실시간 임상 의사결정 지원 시스템 구현을 목표로 할 필요가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기