도메인 특화 표현을 위한 Mittens GloVe 확장
초록
Mittens는 기존의 대규모 사전학습 GloVe 벡터를 시작점으로 삼아, 특정 분야의 텍스트 코퍼스를 이용해 추가 학습하는 간단한 레트로핏(retrofitting) 방식이다. GloVe의 원래 목적함수에 기존 임베딩과의 유클리드 거리 제약을 가중치 µ로 추가함으로써, 도메인 특화 정보와 일반 언어 지식을 동시에 보존한다. 실험에서는 영화 리뷰(IMDB)와 임상 텍스트 두 영역에서 학습 속도와 최종 성능이 향상됨을 확인하였다.
상세 분석
Mittens 모델은 GloVe의 목적함수 J = ∑₍i,j₎ f(Xᵢⱼ)(wᵢ·eⱼ + bᵢ + \tilde bⱼ − log Xᵢⱼ)²에 기존 사전학습 벡터 rᵢ와의 차이를 최소화하는 정규화 항 µ∑ᵢ∈R‖wᵢ+eᵢ − rᵢ‖²를 더한다. 여기서 R은 사전학습 임베딩이 존재하는 단어 집합이며, µ는 두 목표 사이의 트레이드오프를 조절한다. µ=0이면 순수 GloVe와 동일하고, µ가 클수록 기존 임베딩을 더 강하게 보존한다.
핵심 기술적 기여는 두 가지이다. 첫째, GloVe를 완전 벡터화하여 행렬 연산으로 구현함으로써 CPU·GPU 모두에서 효율적인 학습이 가능하도록 했다. 실험에서는 TensorFlow 기반 벡터화 구현이 기존 C 구현에 근접한 속도를 보였으며, GPU 가속 시 특히 큰 어휘에서도 빠른 수렴을 확인했다. 둘째, 레트로핏 아이디어를 GloVe의 손실에 직접 삽입함으로써, 사전학습 임베딩을 “워밍 스타트”로 활용하면서도 새로운 도메인 데이터에 맞게 유연하게 조정할 수 있게 했다.
시뮬레이션에서는 µ를 0.001~0.1 사이로 설정했을 때, 학습된 벡터의 내적과 실제 로그 공출현 확률 사이의 피어슨 상관계수(ρ)가 0.9 이상 유지되는 동시에, 초기 임베딩과의 평균 거리도 적절히 감소함을 보였다. 이는 Mittens가 GloVe의 핵심 통계적 특성을 크게 손상시키지 않으면서도 도메인 특화 정보를 흡수한다는 증거이다.
실제 응용 실험에서는 세 가지 설정을 비교했다. (1) 외부 대규모 코퍼스로 학습된 “External GloVe”, (2) 동일 코퍼스만을 이용해 처음부터 학습한 “IMDB GloVe”, (3) External GloVe를 초기값으로 사용하고 IMDB 코퍼스로 미세조정한 “Mittens”. IMDB 감성 분류에서는 Random Forest 기반 분류기의 정확도가 각각 62.0%, 72.2%, 77.4%로, Mittens가 가장 높은 성능을 보였다. 또한, 학습된 벡터 간의 내적-공출현 상관이 GloVe(ρ≈0.37)보다 Mittens(ρ≈0.47)에서 더 높아, 도메인 데이터가 노이즈를 완화하는 효과가 있음을 확인했다.
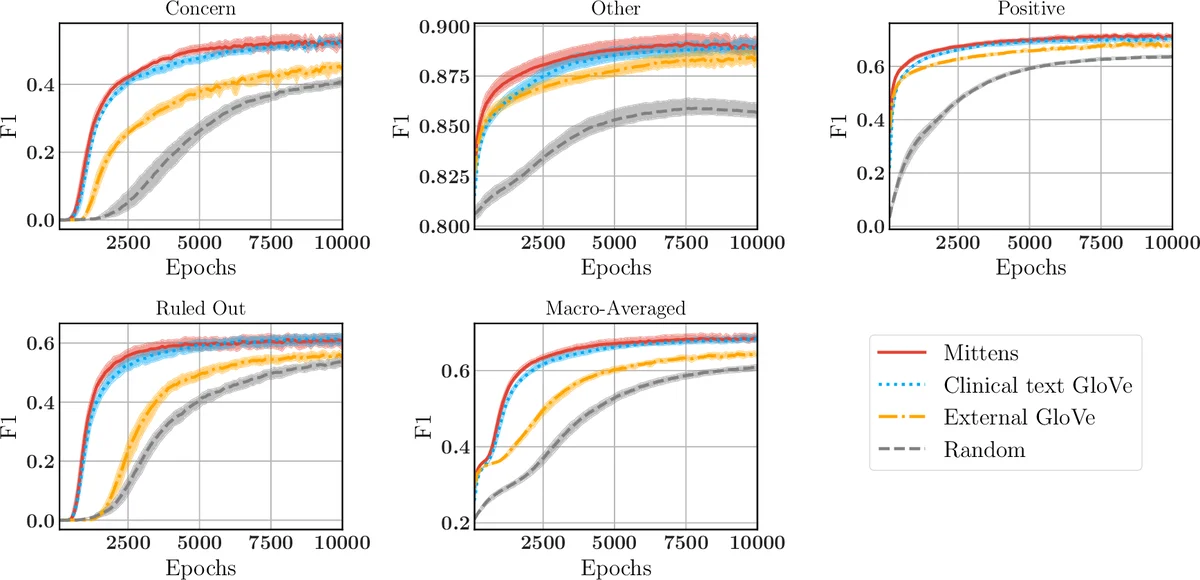
임상 텍스트 실험에서는 100K 임상 노트를 이용해 6.5K 어휘에 대해 학습하였다. 동일한 µ=0.1 설정으로 Mittens와 순수 GloVe를 비교했으며, 두 모델 모두 공출현-내적 상관이 ρ≈0.51로 비슷했지만, RNN 기반 질병 진단 라벨링에서는 Mittens가 학습 초기에 빠르게 수렴해 F1 점수가 전반적으로 우수했다. 특히, “disorder”, “procedure” 등 대형 SNOMED CT 서브그래프에서 에지 예측 정확도가 약 0.5~1% 정도 향상되었으며, 이는 대규모 의료 용어 그래프에 대한 전이 학습에서도 Mittens가 유리함을 시사한다.
전체적으로 Mittens는 (1) 기존 대규모 사전학습 임베딩을 그대로 활용하면서도 (2) 도메인 특화 코퍼스로 효율적으로 미세조정할 수 있는 간단하면서도 강력한 프레임워크이다. µ 파라미터 하나만으로 두 목표 사이의 균형을 조절할 수 있어, 데이터 양이 제한된 전문 분야에서 특히 실용적이다. 향후에는 BERT와 같은 컨텍스트 기반 모델에도 유사한 레트로핏 방식을 적용하는 연구가 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기