엔드투엔드 프로소디 전이로 표현력 풍부한 TTS 구현
초록
본 논문은 Tacotron 기반 TTS에 레퍼런스 인코더를 추가해 고정 길이의 프로소디 임베딩을 학습한다. 이 임베딩을 텍스트와 화자 정보를 결합해 디코더에 조건으로 제공함으로써, 서로 다른 화자·텍스트 간에도 레퍼런스 음성의 억양·리듬·강세를 정밀하게 복제한다. 단일 화자와 44인 화자 다중 모델에서 정량·정성 평가를 통해 전이 품질을 입증한다.
상세 분석
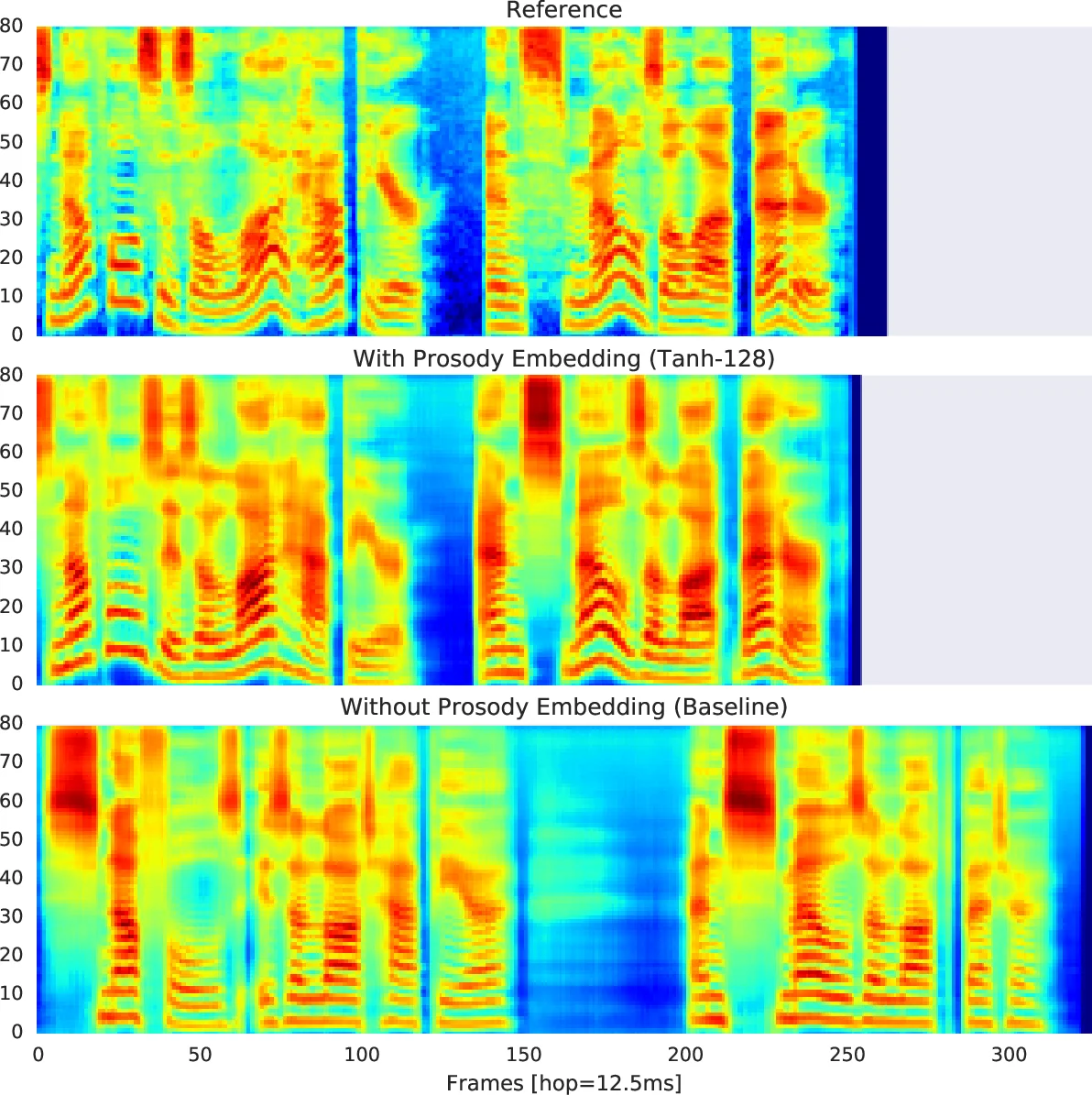
이 연구는 Tacotron(Seq2Seq 기반 멜 스펙트로그램 예측 모델)에 ‘레퍼런스 인코더’를 삽입해 프로소디를 명시적으로 제어하는 방식을 제안한다. 레퍼런스 인코더는 입력 음성의 멜 스펙트로그램을 6층 2D Conv‑BatchNorm‑ReLU 구조로 압축하고, 이후 128‑dimensional GRU를 통해 시퀀스 전체를 요약한다. 최종 128‑dimensional 벡터를 tanh 활성화와 함께 dₚ=128 차원의 고정 길이 프로소디 임베딩으로 변환한다. 이 임베딩은 화자 임베딩 및 텍스트 인코더 출력과 함께 시점마다 broadcast‑concatenation 되어 디코더의 attention 입력에 포함된다.
학습 시 레퍼런스 신호는 목표 음성 자체이며, 별도의 라벨이 없으므로 Tacotron의 재구성 손실만으로 인코더가 프로소디 정보를 압축하도록 강제한다. 여기서 중요한 설계는 ‘병목’ 역할을 하는 임베딩 차원을 충분히 작게 잡아, 인코더가 텍스트·화자 정보를 제외한 남은 변동(즉, 억양·리듬·강세·에너지 변동)을 학습하도록 만든 점이다.
다중 화자 모델에서는 화자 ID를 256‑dimensional 임베딩으로 표현하고, 텍스트는 phoneme 레벨로 전처리한다. 기존 Tacotron의 Bahdanau attention 대신 GMM attention을 채택해 긴 문장에서도 안정적인 정렬을 확보한다. 또한, 고정 길이 임베딩 외에 가변 길이 프로소디 임베딩도 실험했으나, 텍스트·화자 교차 시 타이밍 신호가 과도하게 포함돼 견고성이 떨어지는 것으로 판단, 본 논문에서는 고정 길이 방식을 중심으로 평가한다.
평가 지표는 멜 Cepstral Distortion(MCD), F0 RMSE, V/UV 오류율 등 전통적인 음성 품질 메트릭을 활용했으며, 주관적 MOS와 prosody similarity rating을 추가해 인간 청취자의 인지적 차이를 측정했다. 실험 결과, 레퍼런스 인코더를 사용한 모델은 동일 화자·텍스트 조건에서도 원본 억양을 90% 이상 재현했으며, 화자 교차 상황에서도 억양 패턴이 크게 손실되지 않았다. 특히 44인 화자 다중 모델에서 화자 독립적인 프로소디 전이가 가능함을 확인했다.
이 접근법은 프로소디 라벨링이 필요 없는 비지도 학습 기반이므로, 대규모 비정제 음성 데이터에 바로 적용할 수 있다. 또한, 고정 길이 임베딩이 텍스트와 함께 저장·전송이 용이해 실시간 TTS 서비스에 실용적이다. 향후 연구에서는 텍스트·대화 상황에 따라 자동으로 프로소디 임베딩을 예측하는 모델(예: 변환기 기반)과, 감정·스타일 제어를 위한 다중 임베딩 구조를 확장할 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기