글로벌 스타일 토큰을 활용한 무감독 음성 스타일 제어와 전이
본 논문은 Tacotron 기반 TTS 시스템에 “글로벌 스타일 토큰(GST)”이라는 임베딩 뱅크를 도입한다. 레이블 없이 음성 데이터를 학습시켜 다양한 억양·속도·감정을 자동으로 추출하고, 토큰을 직접 선택하거나 스케일링함으로써 합성 음성의 스타일을 정밀하게 제어하거나 다른 음성의 스타일을 전이할 수 있다. 또한 잡음이 섞인 대규모 비정제 데이터에서도 토큰이 잡음과 화자 특성을 분리해 학습함으로써 견고한 합성 품질을 확보한다.
저자: Yuxuan Wang, Daisy Stanton, Yu Zhang
본 논문은 최신 엔드‑투‑엔드 TTS 모델인 Tacotron에 “글로벌 스타일 토큰(GST)”이라는 새로운 모듈을 도입하여, 음성의 억양·속도·감정 등 복합적인 스타일 정보를 라벨 없이 학습하고 제어하는 방법을 제시한다.
1. **배경 및 동기**
기존 TTS 시스템은 텍스트‑스펙트로그램 매핑에 집중해 평균적인 프로소디를 생성하는 경향이 있다. 인간의 말은 억양, 강세, 감정 등 다양한 스타일 요소가 복합적으로 작용하는데, 이를 명시적으로 모델링하려면 방대한 라벨링 작업이 필요하거나, 스타일이 제한된 사전 정의된 클래스에만 국한된다. 따라서 라벨 없이도 스타일을 자동으로 추출하고, 이를 자유롭게 조작할 수 있는 메커니즘이 요구된다.
2. **모델 구조**
- **참조 인코더**: 로그‑멜 스펙트로그램을 6개의 2‑D 컨볼루션(3×3, stride 2)과 배치 정규화·ReLU를 거쳐 차원을 축소하고, 128‑유닛 단방향 GRU로 시퀀스를 요약한다. 최종 GRU 상태가 “참조 임베딩”이다.
- **스타일 토큰 레이어**: N개의 학습 가능한 토큰(논문에서는 10개, 차원 256)과 참조 임베딩 사이에 콘텐츠‑베이스 어텐션을 적용한다. 어텐션 가중치는 소프트맥스로 정규화되어 각 토큰의 기여도를 나타낸다.
- **스타일 임베딩**: 어텐션 가중치와 토큰을 가중합해 얻은 벡터를 텍스트 인코더의 모든 타임스텝에 더한다. 이렇게 하면 텍스트와 스타일이 완전히 분리된 형태로 결합된다.
- **Tacotron 디코더**: 기존과 동일하게 멜 스펙트로그램을 예측하고, 이후 Griffin‑Lim 혹은 WaveNet 등으로 파형을 복원한다.
3. **학습 방식**
전체 네트워크는 텍스트‑음성 쌍을 입력받아 재구성 손실(L1/L2)만으로 최적화한다. 스타일 토큰은 별도 손실이나 라벨 없이, 디코더의 재구성 오류를 최소화하는 과정에서 자동으로 의미 있는 클러스터를 형성한다.
4. **추론 및 제어 방법**
- **스타일 전이**: 임의의 음성 파일을 참조 인코더에 넣어 얻은 스타일 임베딩을 사용하면, 해당 음성의 억양·감정을 그대로 복제한 합성을 수행한다. 텍스트와 음성 내용이 일치하지 않아도 된다.
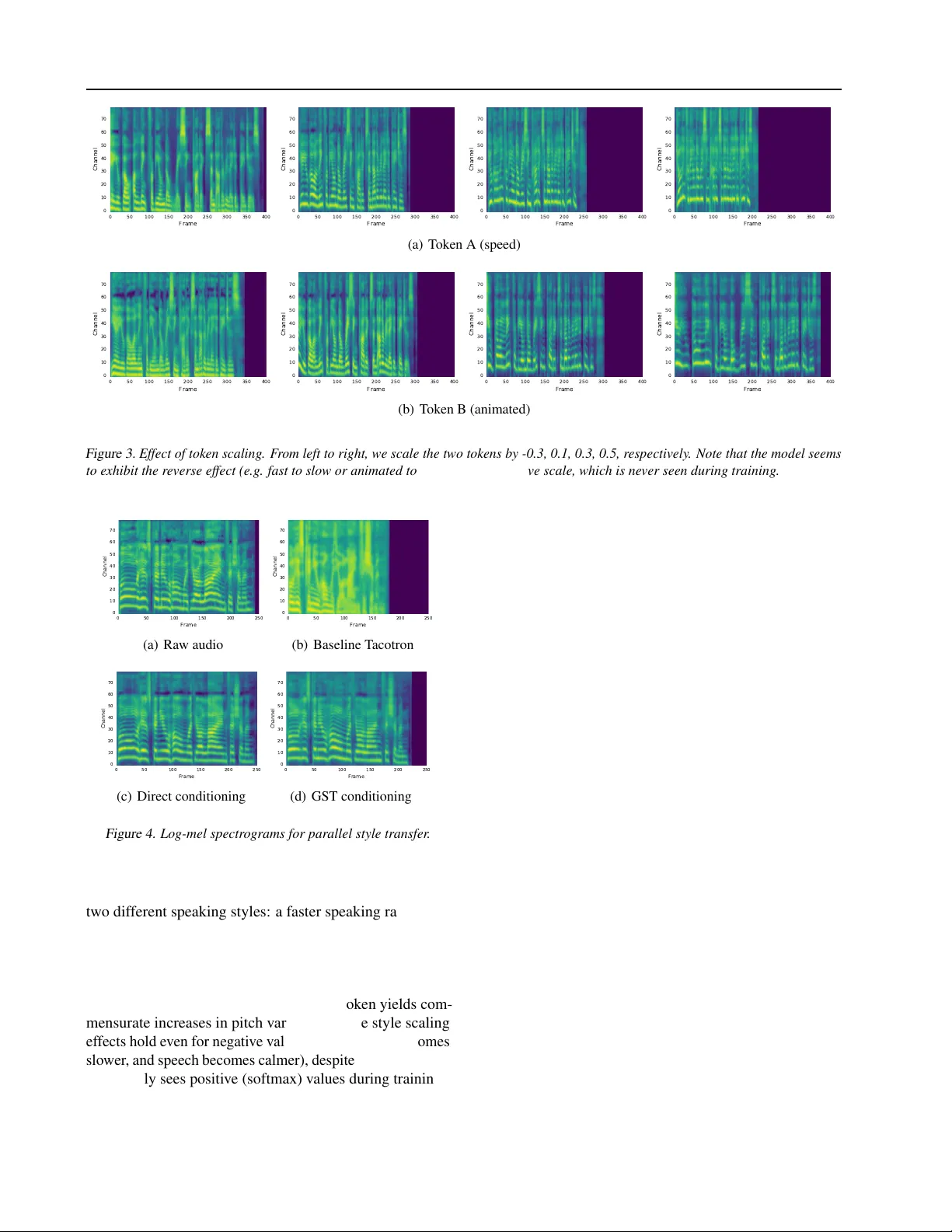
- **토큰 직접 제어**: 참조 인코더를 생략하고 특정 토큰(또는 토큰들의 가중합)을 직접 선택·스케일링함으로써 원하는 스타일을 명시적으로 지정한다. 스케일링 값이 클수록 스타일 효과가 강화되지만, 과도한 값은 발음 불명료성을 초래한다.
5. **실험 및 결과**
- **데이터**: 147시간 분량의 미국 영어 오디오북(Blizzard 2013 스피커) 사용.
- **품질 평가**: GST를 적용한 모델이 기본 Tacotron 대비 MOS 4.0을 기록, 기존 3.82보다 향상.
- **스타일 선택**: 토큰 A, B, C를 각각 적용해 두 문장의 F0·C0 변화를 시각화했을 때, 동일 토큰이 서로 다른 텍스트에서도 일관된 피치·에너지 패턴을 보였다. 이는 토큰이 특정 스타일 속성을 캡처함을 의미한다.
- **스케일링**: 토큰 임베딩에 -0.3~0.5 사이의 스케일을 적용해 속도·감정 변화를 조절했으며, 음성 길이와 억양이 선형적으로 변하는 것을 확인했다.
- **멀티헤드 어텐션**: 헤드 수를 늘리면 토큰 수를 늘리는 것보다 스타일 전이 품질이 크게 개선되었다.
- **노이즈 데이터**: 잡음이 섞인 비정제 데이터에서도 GST가 잡음 전용 토큰과 화자 전용 토큰을 구분해 학습함으로써, 노이즈에 강인한 합성 결과를 얻었다.
6. **해석 및 관계 연구**
- GST는 VQ‑VAE와 유사하게 입력을 소프트 클러스터(토큰)로 양자화한다. 다만, 어텐션 기반 가중합을 사용해 연속적인 스타일 혼합이 가능하다.
- 메모리‑증강 네트워크 관점에서 토큰 뱅크는 외부 메모리 역할을 하며, 참조 신호가 쓰기, 추론 시가 읽기 역할을 수행한다.
- 기존 AutoBI, i‑vector 기반 클러스터링 등은 라벨 혹은 복잡한 피처 엔지니어링이 필요했지만, GST는 순수하게 엔드‑투‑엔드 학습만으로 동일한 목표를 달성한다.
7. **한계 및 향후 과제**
- 토큰 간 상관관계가 높아 독립적인 스타일 요소를 완전히 분리하기 어렵다.
- 스케일링에 따른 발음 안정성 문제가 존재한다.
- 토큰 수·차원, 어텐션 형태 등에 대한 최적화가 필요하며, VQ‑like 이산화와의 결합, 메모리‑증강 기법 적용 등이 향후 연구 방향이다.
8. **결론**
GST는 라벨이 없는 대규모 음성 데이터에서도 스타일 공간을 자동으로 구축하고, 토큰 선택·스케일링을 통해 직관적인 스타일 제어와 전이를 가능하게 한다. 이는 TTS가 단순 텍스트‑음성 변환을 넘어, 인간과 유사한 감정·억양 표현을 구현하는 데 중요한 전진을 의미한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기