동적 텍스트 분석을 위한 재발량화(RQA) 접근법
초록
이 논문은 텍스트를 시간 연속적인 측정값으로 간주하고, 재발량화 분석(RQA)을 적용해 동적 자연어 처리(NLP)를 구현한다. RQA는 텍스트 내 단어 재현 패턴을 시각화·정량화함으로써 전통적인 n‑gram 모델과 연결되는 새로운 지표를 제공한다. 저자들은 8,000개의 구텐베르크 텍스트에 대해 RQA 기반 특징을 추출하고, 기존 NLP 방법과 비교·분류 실험을 수행했으며, R 패키지 crqanlp을 공개한다.
상세 분석
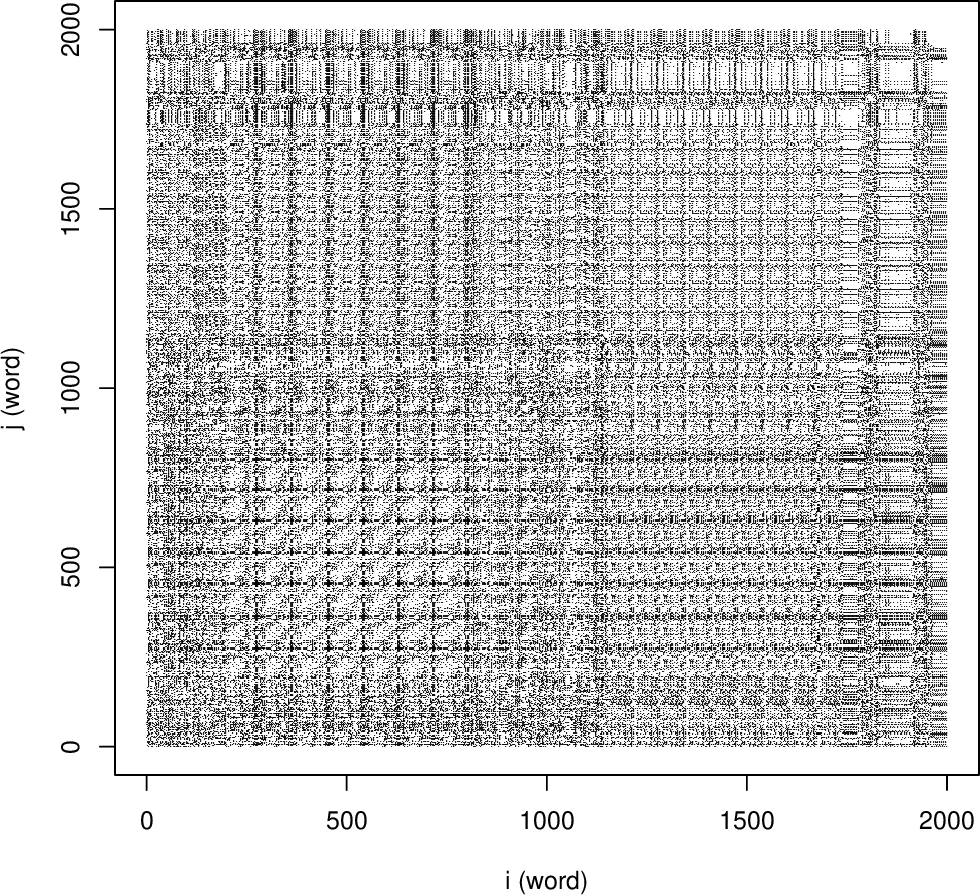
본 연구는 텍스트를 ‘시간에 따라 변화하는 상태’로 모델링함으로써 기존 정적 통계 접근법의 한계를 보완한다. 핵심 방법론은 두 단계로 구성된다. 첫째, 텍스트를 단어 시퀀스로 변환한 뒤 동일 단어가 등장하는 모든 (i, j) 쌍을 좌표평면에 표시해 재발 플롯(Recurrence Plot, RP)을 만든다. 이 플롯은 대각선 라인, 클러스터 등 재현 구조를 시각적으로 드러내며, 텍스트 내 주제 전이·반복 패턴을 직관적으로 파악할 수 있다. 둘째, RP에서 추출한 여러 정량적 지표—재발율(Recurrence Rate, RR), 결정성(Determinism, DET), 평균 대각선 길이(L), 엔트로피(ENTR) 등—를 RQA 지표로 활용한다.
이러한 RQA 지표는 전통적인 n‑gram 기반 확률 모델과 수학적으로 연결된다. 예를 들어 RR은 전체 단어 쌍 중 동일 단어가 나타나는 비율로, 1‑gram(단어 빈도)과 직접적인 관계가 있다. DET은 연속적인 동일 단어 시퀀스(대각선)의 비율을 나타내며, 이는 고차 n‑gram(예: 3‑gram, 4‑gram)의 조건부 확률이 높은 경우와 일치한다. 평균 대각선 길이(L)는 텍스트 내 장기 의존성의 강도를 측정해, 마코프 체인 기반 언어 모델이 포착하기 어려운 장거리 구조를 드러낸다. 엔트로피는 RP 내 대각선 길이 분포의 불확실성을 나타내어, 텍스트 복잡도와 정보량을 평가한다.
실험에서는 구텐베르크 프로젝트에서 추출한 8,000개 소설·시·논문 등을 장르별로 라벨링하고, 각 텍스트에 대해 20여 개의 RQA 특성을 계산했다. 이를 기반으로 랜덤 포레스트와 SVM 분류기를 훈련시켰으며, n‑gram TF‑IDF, LDA 토픽 모델, 그리고 심층 학습 기반 임베딩(BERT)과 비교했다. 결과는 RQA 특성이 특히 장르 구분(예: 소설 vs. 시)에서 높은 정확도(≈85 %)를 보였으며, 기존 방법과 결합할 경우 성능이 더욱 향상됨을 보여준다.
또한 저자들은 R 패키지 crqanlp을 개발해 텍스트 전처리, RP 생성, RQA 지표 계산을 일괄 처리하도록 구현했으며, 기존 R 패키지 crqa와 호환성을 확보했다. 패키지는 사용자 정의 거리 함수, 윈도우 크기 조정, 다중 코호트 분석 등을 지원해 연구자들이 다양한 언어·문체에 적용할 수 있게 설계되었다.
이 논문의 주요 기여는 (1) 텍스트를 동적 시스템으로 보는 새로운 패러다임 제시, (2) RQA와 전통 NLP 지표 사이의 수학적 연결 고리 제시, (3) 대규모 코퍼스에 대한 실증적 검증 및 오픈소스 도구 제공이다. 특히 RQA가 제공하는 장기 의존성·반복 구조의 정량화는 현재 딥러닝 기반 모델이 놓치기 쉬운 인간 인지·서사적 특성을 보완할 가능성을 시사한다.
댓글 및 학술 토론
Loading comments...
의견 남기기