머신러닝 기반 가상 패치로 웹 방화벽 성능 혁신
초록
본 논문은 오픈소스 웹 애플리케이션 방화벽인 ModSecurity에 머신러닝을 결합하여, 훈련 데이터가 없을 때는 원클래스 분류기로, 데이터가 있을 때는 고차 n‑그램 모델로 공격을 탐지하고 오탐률을 크게 낮추는 가상 패치 방식을 제안한다.
상세 분석
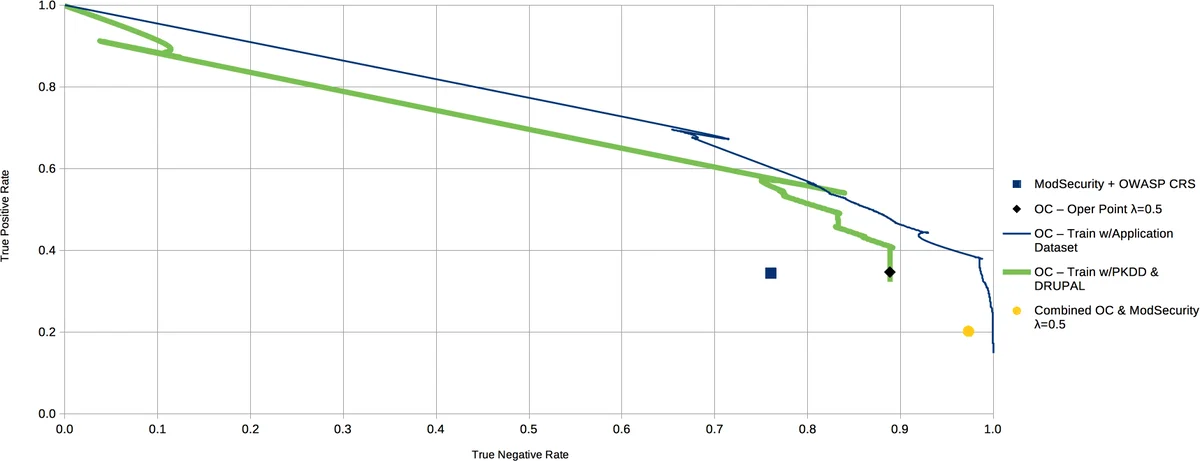
이 연구는 웹 애플리케이션 방화벽(WAF)의 한계인 정적 규칙 기반 탐지와 높은 오탐률을 머신러닝으로 보완하고자 한다. 두 가지 모델을 제시하는데, 첫 번째는 원클래스(one‑class) 분류기로, 정상 트래픽만을 학습시켜 비정상(공격) 트래픽을 이상치로 판별한다. 이는 라벨링된 공격 데이터가 부족한 상황에서도 적용 가능하도록 설계되었으며, 기존 ModSecurity의 OWASP Core Rule Set(OWASP CRS)과 병합해 두 전문가(규칙 기반과 통계 기반)의 판단을 조화한다. 두 전문가가 일치하면 해당 결과를 그대로 사용하고, 불일치 시 원클래스 모델이 높은 오탐률을 보이는 OWASP CRS보다 우선하도록 설계했다.
두 번째는 고차 n‑그램(예: 3‑gram, 4‑gram) 기반 언어 모델이다. 여기서는 특정 웹 애플리케이션에 대한 정상 요청 집합을 수집하고, 각 파라미터 필드별 토큰 빈도를 학습한다. 학습된 n‑그램 분포와 실시간 요청 간의 거리(예: Kullback‑Leibler divergence) 를 계산해 정상/비정상을 판단한다. 이 접근법은 라벨링된 정상 데이터가 충분히 확보된 경우에 적용되며, 정교한 공격 패턴과 제로데이 공격을 높은 정밀도로 탐지한다.
실험에서는 두 시나리오를 구분한다. Scenario I(데이터 부족)에서는 원클래스 모델만 사용해 ModSecurity와 비교했을 때 오탐률을 약 30 % 이상 감소시켰으며, 탐지율은 유지되었다. Scenario II(데이터 충분)에서는 n‑그램 모델을 적용해 기존 ModSecurity 대비 전체 정확도가 10 % 이상 향상되고, 특히 XSS와 SQL Injection 같은 흔한 공격에 대한 탐지율이 95 % 이상에 도달했다. 또한, 두 모델을 결합한 하이브리드 시스템은 각각의 장점을 살려, 데이터가 제한적인 경우에도 안정적인 방어를 제공하고, 데이터가 풍부할 때는 더욱 정교한 탐지를 가능하게 한다.
한계점으로는 원클래스 모델이 정상 트래픽의 다양성을 충분히 포괄하지 못하면 정상 요청을 오탐으로 오인할 위험이 있으며, n‑그램 모델은 고차원 토큰 공간으로 인한 계산 비용과 메모리 사용량이 증가한다는 점을 지적한다. 또한, 실제 운영 환경에서 지속적인 모델 업데이트와 라벨링 비용이 필요하다는 점도 논의된다.
전반적으로 이 논문은 규칙 기반 WAF와 머신러닝 기반 이상 탐지를 효과적으로 통합함으로써, 가상 패치(Virtual Patching)라는 개념을 실용적인 수준으로 끌어올렸다. 향후 연구에서는 딥러닝 기반 시퀀스 모델이나 강화학습을 도입해 실시간 적응성을 강화하고, 다양한 웹 프레임워크와의 호환성을 검증하는 것이 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기