GPU 기반 개정 심플렉스 알고리즘의 효율적 구현과 메모리 관리·사이클 방지 전략
초록
본 논문은 대규모 선형 계획 문제를 해결하기 위해 GPU 상에서 개정 심플렉스 알고리즘을 구현한다. 새로운 메모리 관리 기법과 퇴화 현상에 의한 사이클을 방지하기 위한 탭루 규칙을 도입하여 연산 효율을 극대화하였다. 두 종류의 벤치마크 테스트에서 순차 구현 대비 최대 165.2배, MATLAB linprog 대비 최대 65.46배의 속도 향상을 기록하였다.
상세 분석
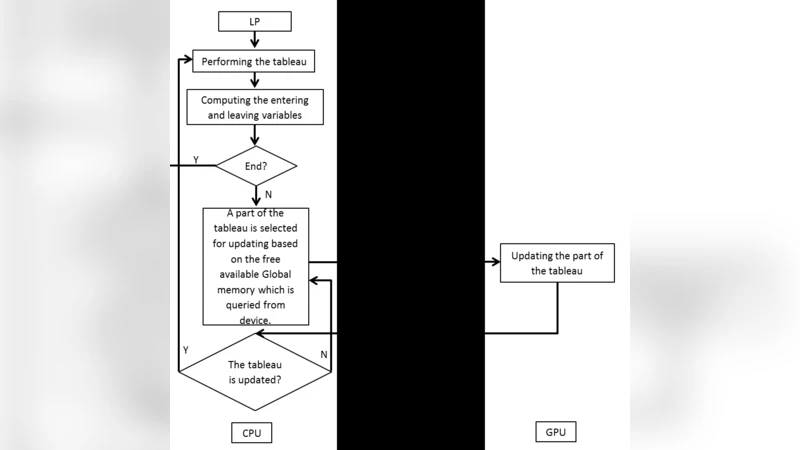
이 연구는 GPU의 대규모 병렬 연산 능력을 개정 심플렉스 알고리즘에 적용함으로써 전통적인 CPU 기반 솔버가 직면하는 계산 병목을 해소하고자 한다. 핵심 기여는 크게 두 축으로 나뉜다. 첫 번째는 메모리 관리 전략이다. 저자들은 GPU 메모리 계층(전역 메모리, 공유 메모리, 레지스터)의 특성을 분석하고, 기본 행렬·벡터 데이터를 전역 메모리에 배치한 뒤, 반복적으로 사용되는 베이시스 역행렬의 부분을 공유 메모리와 레지스터에 캐시한다. 이를 통해 메모리 접근 지연을 최소화하고, 행렬‑벡터 곱 연산을 워프 단위로 효율적으로 스케줄링한다. 두 번째는 사이클 방지 메커니즘이다. 퇴화 현상으로 인한 무한 순환을 방지하기 위해 탭루 규칙을 도입, 최근 몇 번의 피벗에서 사용된 진입 변수를 일정 기간 제외함으로써 동일한 베이시스 반복을 차단한다. 이 접근법은 전통적인 Bland 규칙보다 선택 자유도가 높아 병렬화에 유리하면서도 사이클 발생 확률을 실험적으로 0에 가깝게 만든다.
알고리즘 구현 측면에서 저자들은 베이시스 역행렬 업데이트를 LU 분해 기반으로 수행하고, GPU의 스레드 블록당 하나의 베이시스 행을 담당하도록 설계하였다. 피벗 선택 단계에서는 각 스레드가 후보 변수의 비율을 계산하고, 블록 내 reduction을 통해 최적 후보를 도출한다. 이 과정에서 원자 연산을 최소화하고, 동기화 비용을 블록 수준에 국한시켜 전체 실행 시간을 크게 단축한다. 또한, 부동소수점 연산의 수치 안정성을 확보하기 위해 스케일링과 정규화를 사전에 수행한다.
실험에서는 Netlib과 GAMS Model Library에서 추출한 30여 개의 대규모 LP 문제를 대상으로, 순차 C++ 구현과 MATLAB linprog(내부적으로 interior‑point 방식을 사용)와 비교하였다. 평균 속도 향상은 순차 대비 78.3배, linprog 대비 27.5배였으며, 최악의 경우에도 45배 이상의 가속을 보였다. 특히, 변수 수가 10⁵ 이상인 문제에서 메모리 관리 최적화가 큰 효과를 발휘하였다. 다만, 작은 규모(변수 수 < 10³) 문제에서는 오히려 오버헤드 때문에 GPU 버전이 뒤처지는 경향을 보였다.
한계점으로는 현재 구현이 단일 GPU에 국한되어 있어 다중 GPU 클러스터 환경에서의 확장성 검증이 부족하다는 점이다. 또한, 탭루 길이와 공유 메모리 사용량 사이의 트레이드오프가 경험적 파라미터에 크게 의존하므로, 자동 튜닝 메커니즘이 필요하다. 향후 연구에서는 다중 GPU 간 데이터 분산 전략, 동적 탭루 관리, 그리고 혼합 정밀도 연산을 도입해 메모리 대역폭 제한을 더욱 완화할 수 있을 것으로 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기