사이버보안을 위한 데이터 과학 방법론
초록
본 논문은 사이버보안 프로젝트에 적용 가능한 데이터 과학 방법론을 소개하고, 전통적인 정적·시그니처 기반 보안 모델의 한계를 극복하기 위해 머신러닝·빅데이터·고성능 컴퓨팅을 활용한 지능형 방어 체계 구축 방안을 제시한다. 주요 데이터 과학 프레임워크들을 비교·분석하여 사이버보안 특유의 데이터 특성, 실시간성, 위험 관리 요구에 맞는 최적의 방법론을 도출한다.
상세 분석
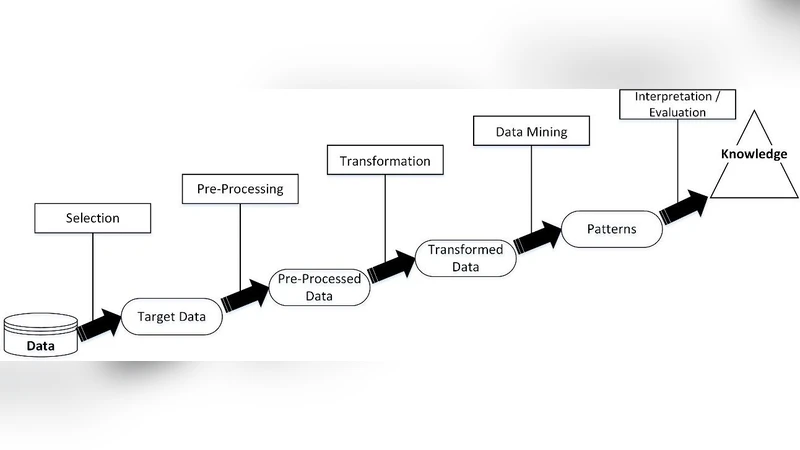
논문은 먼저 기존 사이버보안 솔루션이 정적 시그니처와 규칙 기반 탐지에 의존함으로써 제로데이 공격·다변량 위협에 취약함을 지적한다. 이를 보완하기 위해 데이터 과학이 제공하는 대규모 로그·네트워크 트래픽·행위 데이터의 수집·전처리·특성 추출·모델링·배포 전 과정을 체계화하는 방법론이 필요하다고 주장한다. 저자는 CRISP‑DM, KDD, Microsoft Team Data Science Process (TDSP), 그리고 최근 등장한 AI‑Centric MLOps 를 네 가지 대표적인 프레임워크로 선정하고, 각각의 단계(비즈니스 이해, 데이터 이해, 데이터 준비, 모델링, 평가, 배포, 운영)와 사이버보안 프로젝트에 요구되는 추가 요소(위협 인텔리전스 통합, 실시간 스트리밍 처리, 보안 정책 자동화, 규제·프라이버시 준수)를 매핑한다.
CRISP‑DM은 단계별 문서화와 반복적 피드백 루프가 강점이지만, 실시간 데이터 파이프라인 구축과 모델 지속적 재학습(MLOps) 지원이 부족하다. KDD는 데이터 전처리와 탐색적 분석에 초점을 맞추어 이상 탐지 모델 설계에 유리하지만, 프로젝트 관리와 배포 자동화가 체계적이지 않다. TDSP는 Azure 기반 클라우드 서비스와 연계된 엔드‑투‑엔드 파이프라인을 제공해 대규모 로그 처리와 자동 스케일링에 강점을 보이지만, 특정 클라우드에 종속적이라는 제약이 있다. 마지막으로 AI‑Centric MLOps는 CI/CD, 모델 모니터링, 데이터 버전 관리 등을 포함해 운영 단계에서의 보안 위협 대응과 모델 드리프트 감지를 자동화한다. 그러나 초기 설계와 인프라 구축 비용이 높고, 보안 전문가와 데이터 과학자 간의 협업 프로세스 정의가 필요하다.
각 방법론의 강·약점을 사이버보안 특성(데이터 다양성, 실시간성, 높은 오탐률 비용, 규제 요구)과 매칭시킨 결과, 저자는 하이브리드 접근을 제안한다. 예컨대, 초기 탐색 단계에서는 KDD의 데이터 탐색 기법을 활용하고, 모델링·배포 단계에서는 TDSP와 MLOps를 결합해 클라우드 기반 스트리밍 파이프라인과 자동화된 모델 관리 체계를 구축한다. 또한, 위협 인텔리전스 피드와 SIEM 시스템을 데이터 레이어에 통합해 피처 엔지니어링 단계에서 도메인 지식을 반영하도록 설계한다.
보안 관점에서 중요한 점은 모델 설명가능성(XAI)과 정책 연동이다. 논문은 모델 결과를 보안 정책 엔진에 전달해 자동 차단·격리·알림을 트리거하는 워크플로우를 설계하고, 모델 오류 시 인간 전문가가 개입할 수 있는 인터페이스를 제공한다. 마지막으로, 데이터 프라이버시와 규제 준수를 위해 데이터 거버넌스, 익명화, 접근 제어를 전 과정에 삽입하고, 감사 로그를 자동 수집해 컴플라이언스 보고에 활용한다.
전반적으로 논문은 데이터 과학 방법론을 사이버보안 프로젝트에 맞게 재구성하고, 각 단계에서 필요한 보안‑특화 도구와 프로세스를 명시함으로써 기존 정적 방어 체계의 한계를 극복하고, 지속 가능한 지능형 방어 시스템 구축 로드맵을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기