희소 디리클레 사전과 다항식 비선형 혼합 모델을 이용한 베이지안 하이퍼스펙트럼 언믹싱
초록
본 논문은 대규모 스펙트럼 라이브러리를 전제로, 희소 디리클레 사전으로 풍부도 벡터의 희소성을 모델링하고, 2차 다항식 포스트-비선형 혼합 모델(PPNMM)과 결합한 베이지안 언믹싱 프레임워크를 제안한다. 엔드멤버 추출 단계 없이 메타데이터만으로 MCMC 기반 추정이 가능하며, 기존 균일 사전 대비 추정 오차가 50% 이상 감소함을 시뮬레이션으로 입증한다.
상세 분석
이 연구는 하이퍼스펙트럼 이미지(HI) 언믹싱에서 두 가지 핵심 난제를 동시에 해결한다. 첫째, 실제 현장에서는 정확한 엔드멤버 스펙트럼을 사전에 알기 어려운 반면, 방대한 스펙트럼 라이브러리는 쉽게 확보된다. 저자는 이러한 상황을 ‘반감독(semi‑supervised)’이라고 정의하고, 엔드멤버 추출 알고리즘(EEA)을 배제한다. 둘째, 비선형 혼합 현상을 포착하기 위해 기존의 선형 혼합 모델(LMM)을 넘어, 2차 다항식 형태의 포스트‑비선형 혼합 모델(PPNMM)을 채택한다. PPNMM은 선형 혼합에 비선형 항을 곱해주어, 양자화된 비선형 효과를 간단히 근사한다.
베이지안 프레임워크는 계층적 구조를 갖는다. 관측 모델은 가우시안 잡음이 추가된 PPNMM 식(2)로 정의되며, 파라미터는 풍부도 벡터 a, 비선형 계수 b, 잡음 분산 σ², 그리고 비선형 변환 파라미터 c(=b) 등이다. 풍부도에 대한 사전은 ‘희소 대칭 디리클레 분포’를 사용한다. 농도 파라미터 α가 1보다 작을 때(α<1) 디리클레 분포는 단순히 단순체(simplex) 상에서 균일하게 퍼지는 것이 아니라, 대부분의 성분을 0에 가깝게 만들며 소수의 성분만 크게 만든다. 이는 대규모 라이브러리에서 실제 사용되는 엔드멤버가 소수라는 가정을 정량화한다. α는 사전 지식에 따라 조정 가능하며, 본 논문에서는 α<1인 희소 설정을 채택했다.
그 외 파라미터에 대해서는 제프리 사전(σ²)과 정규 사전(b)·역감마 사전(c) 등을 부여해 완전한 사후 분포를 구성한다. 이 사후는 폐쇄형 해를 갖지 않으므로, 메트로폴리스‑위드인‑깁스(Metropolis‑Within‑Gibbs) 샘플러를 설계해 각 조건부 분포에서 샘플링한다. 구체적으로는 a를 디리클레 형태의 조건부에서, b를 정규 형태의 조건부에서, σ²와 c를 각각 역감마와 정규 조건부에서 순차적으로 업데이트한다. 10,000번의 MCMC 반복과 1,000번의 버닝을 거쳐 수렴된 사후 평균을 추정량으로 사용한다.
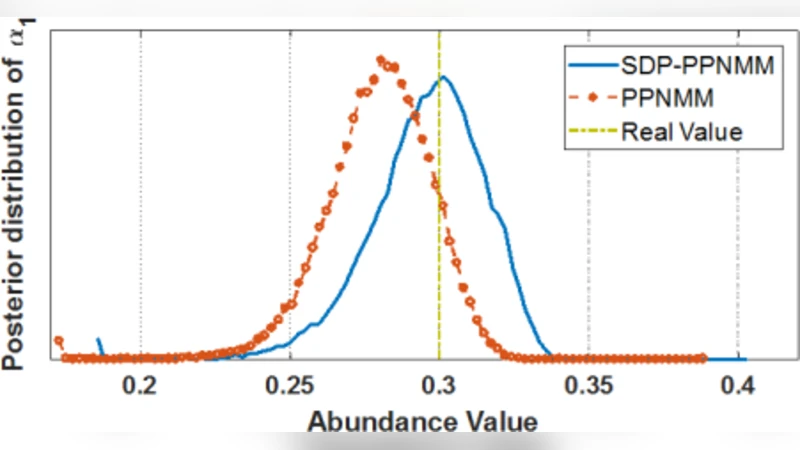
실험은 USGS 스펙트럼 라이브러리에서 무작위로 6개의 엔드멤버를 선택하고, 그 중 2개만 실제 혼합에 사용해 희소성을 인위적으로 만들었다. 제안 방법(SDP‑PPNMM)과 기존 균일 디리클레 사전 기반 PPNMM을 20번 반복 실험했으며, 평균 제곱 오차(MSE)와 재구성 오차(RE)를 비교했다. 결과는 MSE 0.0238(×10⁻²) vs 0.05, RE 5.17% vs 5.30%로, 특히 MSE에서 50% 이상 개선되었다. 또한, 0에 가까운 풍부도 성분에 대해 사후 분포가 더 뾰족하게 집중되는 것을 확인해, 불필요한 엔드멤버를 효과적으로 배제함을 시각적으로도 입증했다.
이 논문의 주요 기여는 (1) 엔드멤버 사전 지식이 없더라도 대규모 라이브러리와 희소 디리클레 사전만으로 정확한 언믹싱이 가능함을 보인 점, (2) 비선형 혼합을 단순 2차 다항식으로 모델링하면서도 베이지안 추정 체계와 결합해 실용적인 성능을 달성한 점, (3) MCMC 기반 추정이 복잡한 사후를 효과적으로 탐색한다는 점을 실험적으로 검증한 점이다. 향후 연구에서는 α를 자동으로 학습하거나, 더 높은 차수의 비선형 함수를 도입해 복잡한 현장 데이터에 적용하는 방향이 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기