선형 네트워크 기반 스피커 적응으로 적은 데이터에서도 고품질 음성 합성
초록
본 논문은 다중 레이어에 선형 네트워크(LN)를 삽입하고, 데이터가 극히 제한된 상황에서는 저‑랭크 + 대각선(LRPD) 분해를 적용해 파라미터 수를 크게 줄이는 방식으로 스피커 적응을 수행한다. 실험 결과, 200개의 적응 발화만으로도 1000발을 사용한 스피커‑전용 모델과 거의 동등한 자연스러움과 화자 유사도를 달성했으며, 특히 LRPD‑LN이 적은 데이터에서 가장 안정적인 성능을 보였다.
상세 분석
이 연구는 기존 DNN‑BLSTM 기반 통계적 파라메트릭 음성 합성(SPSS) 시스템에 선형 네트워크(LN)를 다중 레이어에 삽입하여 스피커 적응을 수행한다는 점에서 의미가 크다. LN은 입력(LIN), 은닉(LHN), 출력(LON) 형태로 구현될 수 있으며, 본 논문에서는 특히 마지막 은닉 레이어와 출력 레이어 바로 앞에 LN을 배치하고, 이와 동시에 출력 레이어 자체를 미세조정(fine‑tuning)한다. 이렇게 하면 전체 네트워크를 재학습하지 않고도 화자 특성을 효과적으로 반영할 수 있다.
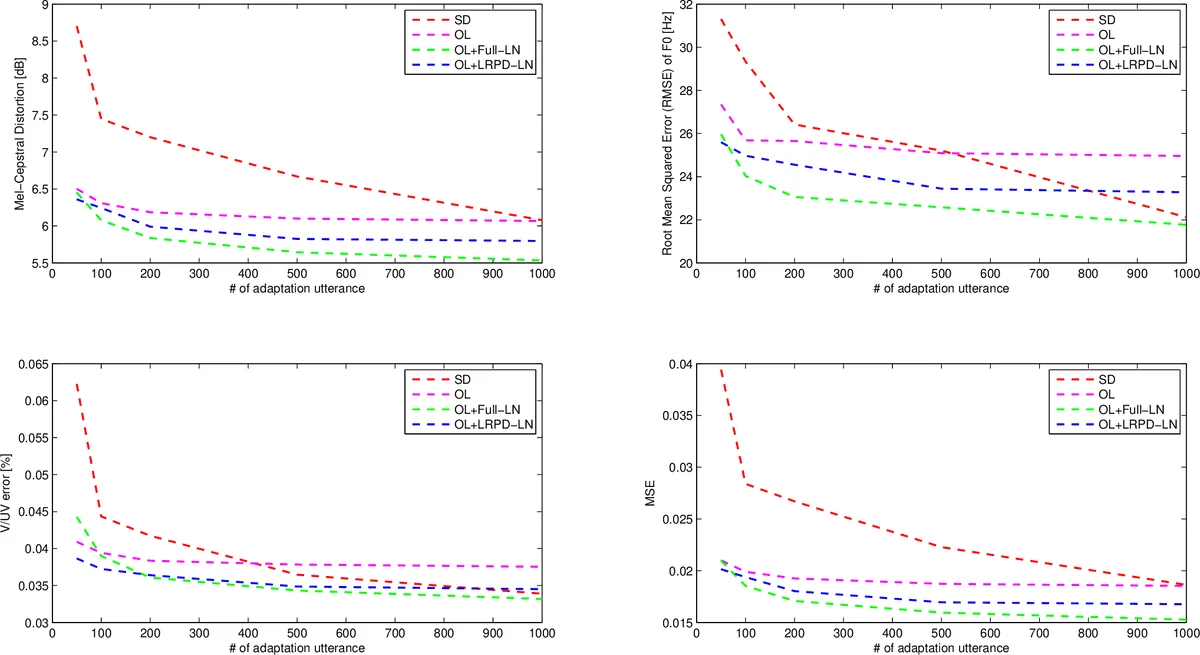
하지만 LN을 전부 풀 파라미터(Full‑LN)로 학습하면, 적은 적응 데이터에서는 파라미터 수가 과다해 과적합 위험이 커진다. 이를 해결하기 위해 저‑랭크 + 대각선(LRPD) 분해를 도입한다. LRPD‑LN은 변환 행렬 Wₛ를 대각선 행렬 D와 두 저‑랭크 행렬 U·V의 합으로 근사한다. 차원 k에 대해 파라미터 수를 k²에서 k·(2r + 1)로 감소시키며, r ≪ k인 경우 80 % 이상 파라미터를 절감한다. 대각선 행렬은 초기값을 항등행렬로 고정하고 학습하지 않아, 모델 복잡도는 더욱 낮아진다.
실험은 3명의 중국어 원어민(남성 A, 여성 B, 여성 C) 데이터를 사용했으며, 각 화자당 약 5 000개의 발화를 확보했다. 적응 데이터는 50 ~ 1 000개로 다양하게 설정하고, 200개는 검증, 20개는 청취 테스트용으로 별도 보관했다. 입력 특징은 753차원의 언어학적 바이너리·수치 특징, 출력은 75차원의 음향 특징(멜‑cepstrum 60, log F0 3, 밴드‑aperiodicity 11, V/UV 1)이다. 기본 모델은 1024‑노드 DNN 레이어와 3개의 1024‑노드 BLSTM 레이어로 구성되었다.
목표는 (1) 여성→여성(유사 화자), (2) 남성→여성, (3) 여성→남성(다른 성별) 세 가지 적응 시나리오를 평가하는 것이었다. 객관적 평가지표는 Mel‑Cepstral Distortion(MCD), F0 RMSE, V/UV 오류율, 전체 MSE였으며, 주관적 평가는 자연스러움과 화자 유사도에 대한 MOS를 5점 척도로 측정했다.
결과는 다음과 같다. 적응 데이터가 200개 이상이면 OL + Full‑LN이 가장 낮은 MCD와 RMSE를 기록했지만, 50~100개 수준에서는 LRPD‑LN이 과적합을 방지해 더 안정적인 성능을 보였다. 특히 200개 데이터에서 LRPD‑LN 기반 적응 모델은 SD(스피커‑전용) 모델이 1 000개 데이터를 사용했을 때와 거의 동등한 MOS(자연스러움 ≈ 4.2, 유사도 ≈ 4.0)를 달성했다. 성별이 다른 화자 간 적응에서도 동일한 경향이 나타났으며, LRPD‑LN이 Full‑LN보다 주관적 평가에서 일관적으로 우수했다.
이 연구는 (1) LN을 다중 레이어에 삽입하고 출력 레이어와 공동 미세조정함으로써 기존의 단순 출력 레이어 적응보다 훨씬 높은 적응 효율을 얻었고, (2) LRPD 분해를 통해 파라미터 수를 크게 줄이면서도 적은 데이터 상황에서 과적합을 효과적으로 억제한다는 점을 입증했다. 따라서 실제 서비스에서 새로운 화자를 빠르게 추가해야 하는 TTS 시스템에 매우 유용한 접근법이라 할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기