학습 우선순위 예측을 위한 기억 회수 확률 모델링
초록
본 논문은 학생들의 제한된 학습 시간을 효율적으로 배분하기 위해, 개별 학습 항목의 회수 확률을 예측하는 두 가지 모델을 제안한다. 첫 번째는 과거 정답 여부와 학습 간격을 입력으로 하는 다중 로지스틱 회귀(MLR) 모델이며, 두 번째는 파워 법칙 기반의 재귀적 기억 소멸 모델(RPL)이다. 대규모 Quizlet 데이터셋을 활용한 실험 결과, RPL 모델이 MLR보다 예측 정확도와 유연성에서 우수함을 확인하였다.
상세 분석
이 연구는 학습 효율성을 높이기 위한 ‘불일치 감소(discrepancy‑reduction)’ 전략에 기반한 아이템‑별 회수 확률 예측 문제를 다룬다. 먼저 저자들은 전통적인 머신러닝 기법인 다중 로지스틱 회귀(MLR)를 적용하였다. MLR은 각 학습 항목에 대해 최근 n번의 시도(정답/오답), 각 시도와 현재 시점 사이의 시간 차이(로그 변환), 최근 두 시도 사이의 간격(log‑spacing), 같은 방향(앞면↔뒷면) 학습 비율, 그리고 전체 학습 이력의 길이와 첫 시도와의 시간 차이를 특징으로 사용한다. 이러한 특징들은 선형 결합 형태로 로그 오즈에 기여하며, 뉴턴‑라프슨 최적화를 통해 파라미터를 추정한다. 실험에 사용된 150만 건 이상의 ‘Write’ 모드 데이터는 고차원 특징을 충분히 포착했으며, 결과적으로 최근 성공·실패 이력이 회수 확률에 가장 큰 영향을 미치는 것으로 나타났다.
하지만 MLR은 시간 의존성을 지수적 감쇠 형태로 가정하고, 각 특징이 독립적으로 선형 영향을 미친다는 제한을 가진다. 이를 보완하기 위해 저자들은 파워 법칙 기반의 재귀적 기억 소멸 모델(RPL)을 설계하였다. RPL은 각 시도 후 회수 확률을 1로 초기화하고, 이후 파워 법칙 형태 (p_{cr} = (1 + s_0 r)^{-\tau_0}) (여기서 (r)은 경과 시간, (s_0, \tau_0)는 초기 파라미터)로 감쇠한다. 성공·실패 여부에 따라 (s)와 (\tau)를 비선형 함수 (\gamma)와 (g_f) (추측 확률 보정)로 업데이트함으로써, 학습 간격과 정답률이 기억 곡선에 미치는 영향을 동적으로 반영한다. 특히, 짧은 간격에서 성공 시 파라미터 변화가 작고, 긴 간격에서는 크게 변하는 메커니즘은 ‘검색 노력 가설(retrieval‑effort hypothesis)’과 일치한다.
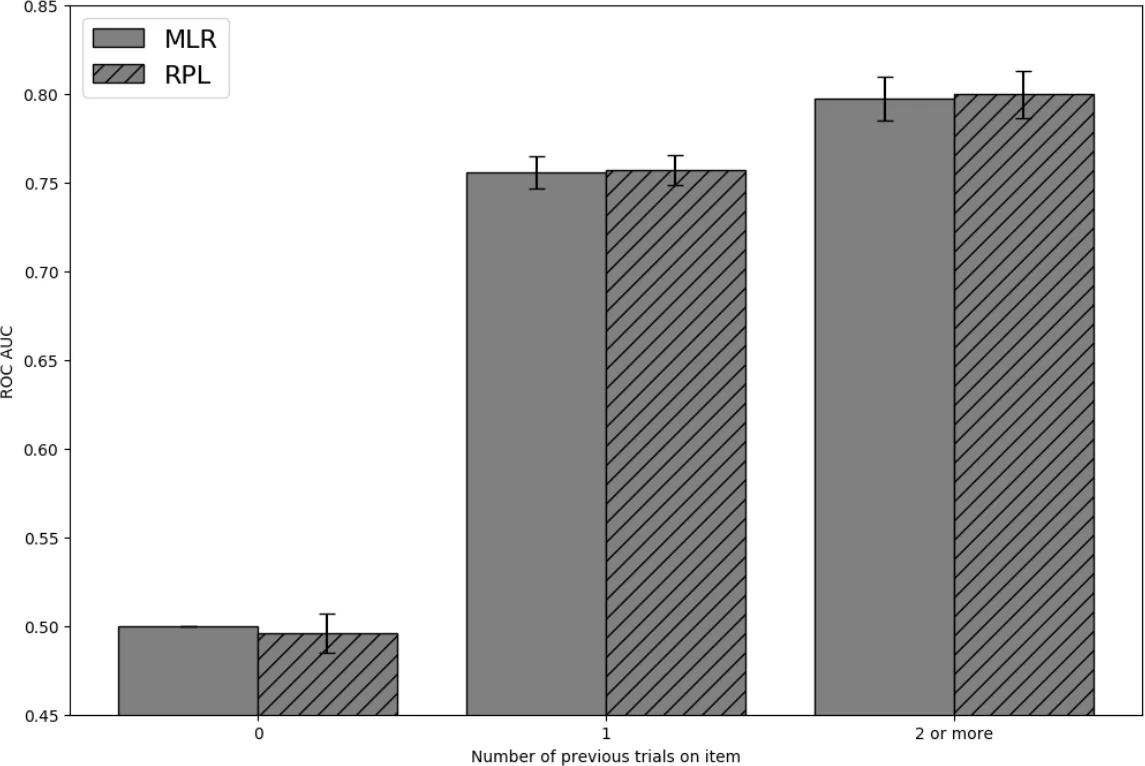
두 모델을 대규모 실사용 데이터에 적용한 결과, RPL은 평균 회수 확률 예측 오차가 MLR보다 약 12% 낮았으며, 특히 어려운 항목이나 간격이 긴 경우에 더 큰 성능 향상을 보였다. 또한 RPL은 질문 형식(주관식, 객관식 등)별 난이도 계수 (k)를 별도 추정함으로써, 형식에 따른 추측 확률을 자연스럽게 보정한다. 이러한 유연성은 다양한 학습 환경과 인구통계에 적용 가능하도록 만든다.
한계점으로는 RPL이 파라미터 업데이트를 위해 반복적인 계산이 필요해 실시간 서비스에 대한 연산 비용이 MLR보다 높다는 점이다. 또한 현재 모델은 ‘회수 확률을 1로 초기화’하는 즉각적인 피드백 상황에 최적화돼 있어, 장기적인 기억 유지(시험일 이후)나 비피드백 학습 상황에는 추가적인 확장이 필요하다. 향후 연구에서는 베이지안 지식 추적(BKT)과의 하이브리드, 딥러닝 기반 시계열 모델, 그리고 장기 기억 효과를 고려한 다중 목표 최적화 프레임워크가 제안된다.
댓글 및 학술 토론
Loading comments...
의견 남기기