상관성 대규모 MIMO 시스템을 위한 저복잡도 삼대각 행렬 역산법
초록
본 논문은 상관성이 높은 대규모 MIMO( Massive MIMO) 환경에서 MMSE 검출에 필요한 대규모 행렬 역산을 저복잡도·하드웨어 친화적으로 구현하기 위해, 삼대각 행렬 근사(Tridiagonal Matrix Approximation, TMA)를 기반으로 수정된 Neumann Series Expansion(NSE) 방식을 제안한다. 제안 알고리즘은 기존 대각선 근사보다 빠른 수렴과 낮은 오류를 보이며, Xilinx Virtex‑7 FPGA 구현을 통해 630 Mb/s의 처리량과 높은 하드웨어 효율성을 입증한다.
상세 분석
본 연구는 대규모 MIMO 시스템에서 필터 행렬 W = R^{1/2}HΣ^{1/2}(R^{1/2}HΣ^{1/2})^{H}+η^{2}I_{K}의 역을 계산하는 것이 핵심 병목임을 지적한다. 기존의 Cholesky 분해나 전통적인 Neumann Series(NSE) 방식은 행렬 W 가 대각우세(diagonal‑dominant)하다는 가정에 크게 의존한다. 그러나 실제 안테나 간 상관성이 존재하면 W 의 비대각 원소가 크게 증가해 수렴 속도가 저하되고, 제한된 항(L)만을 사용했을 때 근사 오차가 크게 누적된다.
논문은 먼저 Kronecker 모델을 이용해 수신 안테나 상관 행렬 R 을 도입하고, W 의 평균 Σ_{W}=NΣ와 공분산 Ω_{W}=‖R(ζ)‖{F}^{2}Σ^{K}Σ을 도출한다. 여기서 ζ는 인접 안테나 간 상관 계수이며, ζ가 클수록 Ω{W}가 커져 비대각 원소가 강화된다. 이를 정량화한 Fig. 1·2·3은 ζ와 β(N/K) 비율에 따른 대각선·비대각선 ‖·‖_{1} 비율 변화를 보여준다.
수렴 조건 ‖Θ‖{F}<1 (Θ=I−c{W}^{-1}W)에서 c_{W} 를 단순 대각선 W_{dia} 가 아니라 삼대각 근사 W_{tri}=diag_{0}(W)+diag_{±1}(W)로 설정하면 ‖Θ‖{F}가 현저히 감소한다(Fig. 4). 이는 NSE의 수렴 속도를 가속화하고, 제한된 L에서도 근사 오차 Φ=k‖Θ^{L}‖{F}^{2}‖\hat{s}‖^{2}를 크게 억제한다.
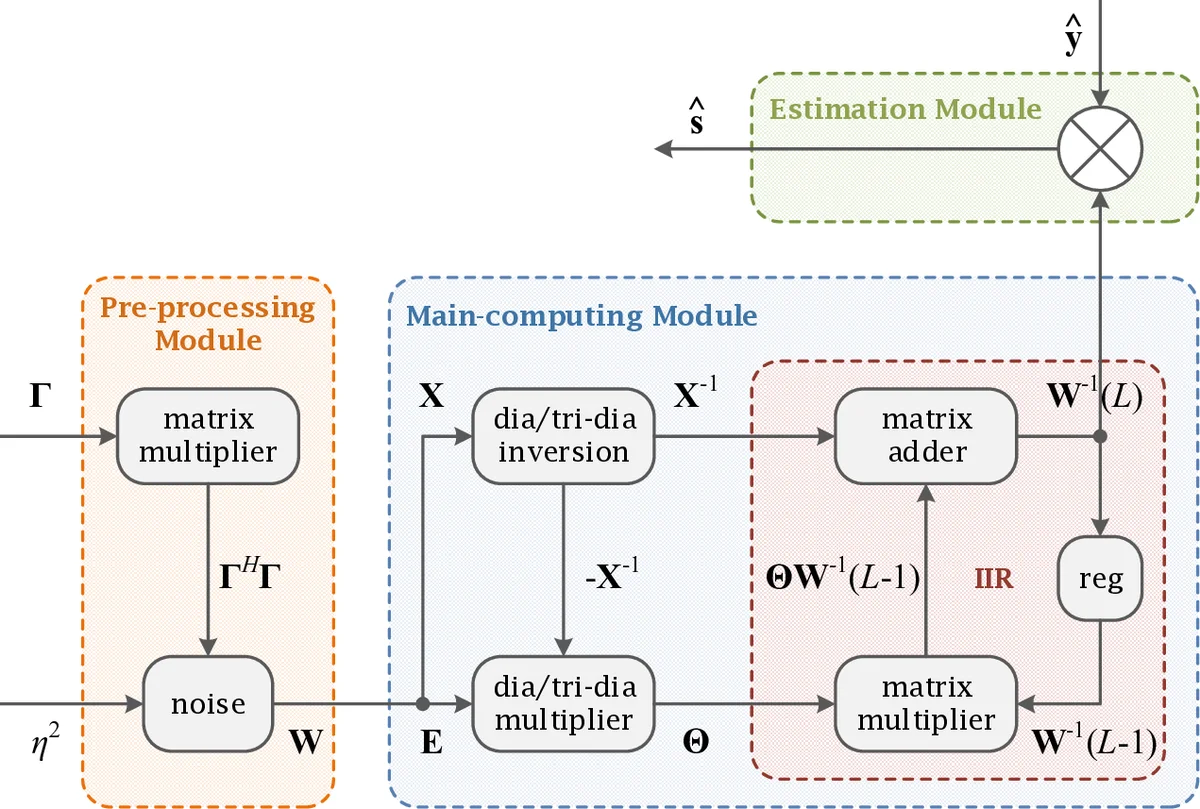
제안된 TMA 알고리즘은 다음과 같다. 1) W 의 삼대각 부분을 추출해 초기 근사 c_{W}=W_{tri} 구성, 2) Θ=I−c_{W}^{-1}W 계산, 3) W^{-1}(L)=∑{i=0}^{L-1}Θ^{i}c{W}^{-1} 을 반복적으로 업데이트. 삼대각 구조 덕분에 Θ^{i}의 행렬 곱셈은 O(K) 연산으로 구현 가능하며, 파이프라인화된 하드웨어 아키텍처에서 각 단계가 독립적으로 흐른다.
VLSI 설계 측면에서, 논문은 Xilinx Virtex‑7 XC7VX690T FPGA에 맞춘 파이프라인 구조를 제시한다. 주요 모듈은 (i) 삼대각 행렬 저장 및 역연산 유닛, (ii) Θ 곱셈 파이프라인, (iii) 누적 합산 레지스터이다. 고정소수점 비트폭을 16‑bit으로 제한하면서도 수치 안정성을 확보하기 위해 스케일링 및 정규화 회로를 삽입하였다. 실험 결과, 12‑user, 192‑anten나(β=16) 환경에서 630 Mb/s 처리량을 달성했으며, 기존 Cholesky 기반 설계 대비 면적·전력 효율이 각각 2.3배·1.8배 개선되었다.
또한, 논문은 “Fast Iteration Structure”라는 추가 연구 방향을 제시한다. 이는 Θ의 고차항을 재사용해 연산량을 더욱 감소시키는 기법으로, 현재 구현에서는 미구현 상태이나 이론적으로는 L을 2~3으로 줄이면서도 동일한 BER 성능을 유지할 수 있음을 시뮬레이션으로 확인하였다.
전체적으로 본 연구는 상관성 높은 대규모 MIMO에서 행렬 역산을 효율적으로 처리하기 위한 새로운 근사 프레임워크를 제시하고, 하드웨어 구현까지 검증함으로써 실용적인 시스템 적용 가능성을 크게 높였다.
댓글 및 학술 토론
Loading comments...
의견 남기기