강화학습으로 최적화된 시퀀스 투 시퀀스 음성인식
본 논문은 전통적인 최대우도 추정(MLE) 기반 학습이 갖는 학습‑추론 불일치와 오류 전파 문제를 해결하기 위해, 시퀀스‑투‑시퀀스(Seq2Seq) 음성인식 모델에 정책 그래디언트 강화학습을 적용한다. 전체 전사 샘플을 모델 자체 예측으로 생성하고, 부정적인 레벤슈타인 거리(편집 거리)를 보상으로 사용해 직접 CER/WER와 같은 평가 지표를 최적화한다. WSJ 데이터셋 실험에서 MLE만 사용한 경우보다 CER를 13%~30% 정도 감소시킨 성…
저자: Andros Tj, ra, Sakriani Sakti
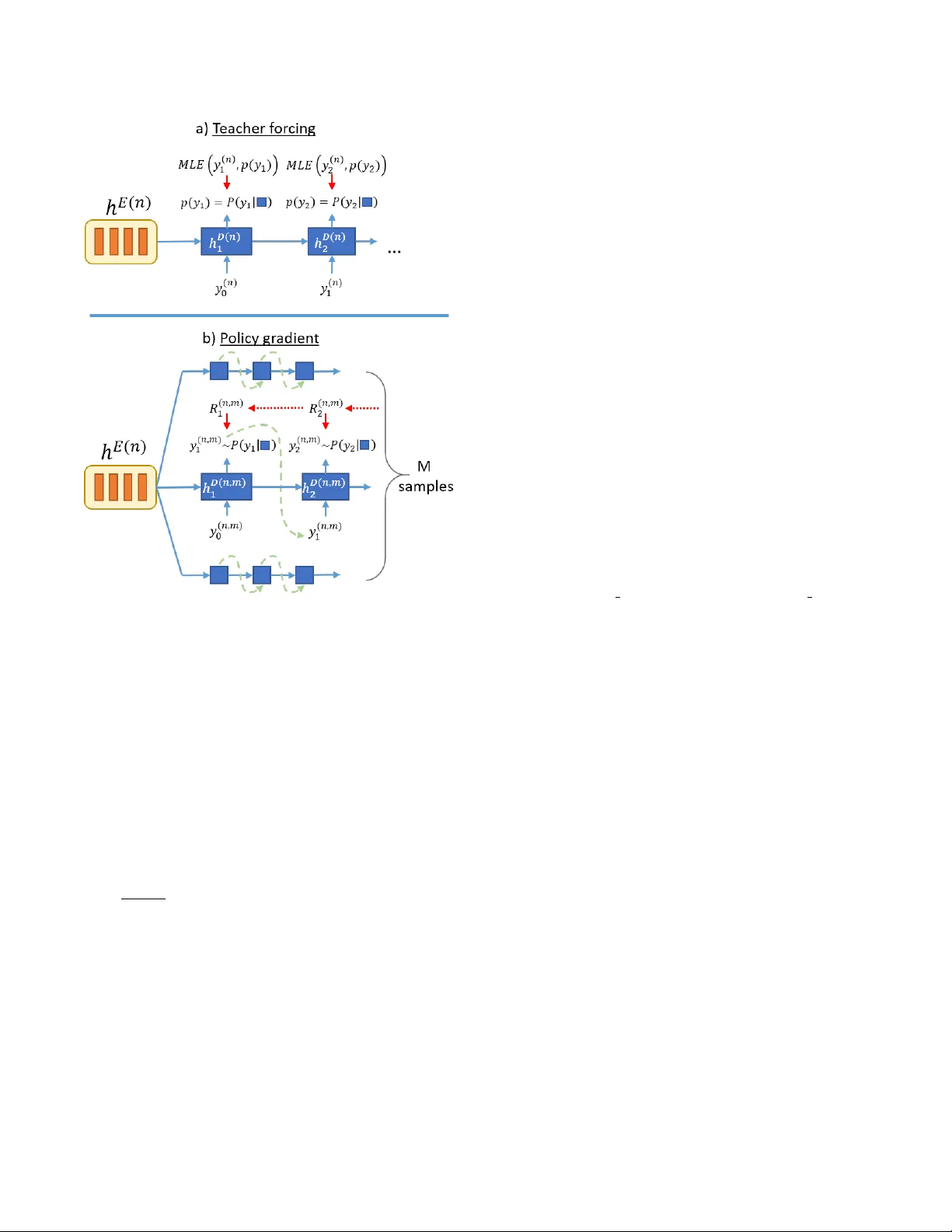
본 논문은 시퀀스‑투‑시퀀스(Seq2Seq) 기반 자동음성인식(ASR) 모델이 직면한 두 가지 핵심 문제, 즉 학습‑추론 불일치와 평가 지표와의 손실 함수 불일치를 해결하고자 강화학습(RL)을 도입한 새로운 학습 프레임워크를 제안한다. 전통적인 Seq2Seq ASR은 인코더‑디코더 구조와 어텐션 메커니즘을 활용해 입력 음성 신호를 문자 시퀀스로 직접 매핑한다. 학습 단계에서는 교사 강제(teacher‑forcing) 방식을 사용해 이전 토큰을 정답으로 고정하고 현재 토큰을 예측하도록 모델을 최적화한다. 그러나 추론 시에는 정답이 없으므로 모델 자체 예측에 의존하게 되며, 초기 오류가 이후 단계에 전파되는 오류 전파(error propagation) 문제가 발생한다. 또한, 모델은 로그우도 최대화를 목표로 하는 최대우도 추정(MLE) 손실을 최소화하지만, 실제 평가에서는 문자 오류율(CER)이나 단어 오류율(WER)과 같은 편집 거리 기반 지표가 사용된다. 이러한 불일치는 최적화 목표와 실제 성능 사이에 괴리를 만든다.
이를 해결하기 위해 논문은 디코더를 정책 네트워크로 간주하고, 정책 그래디언트(REINFORCE) 알고리즘을 적용한다. 상태 s_t는 디코더 은닉 상태 h_D_t와 어텐션 컨텍스트 c_t의 결합으로 정의되며, 행동 a_t는 현재 시점에서 선택되는 grapheme(문자)이다. 행동 공간은 전체 문자 집합과 EOS 토큰을 포함한다. 보상 함수는 편집 거리(Levenshtein distance)를 기반으로 설계되었다. 구체적으로, 시간 단계 t에서의 보상 r_t는 현재까지 생성된 부분 전사 y_{1:t}와 정답 전사 y^{(n)} 사이의 편집 거리 차이로 정의된다. 즉, 새로운 토큰이 편집 거리를 감소시키면 양의 보상이 주어지고, 그렇지 않으면 음의 보상이 부여된다. 전체 문장에 대한 최종 보상 R은 시점별 보상의 할인 누적합 R_t = Σ_{i=t}^{T} γ^{i−t} r_i 로 계산되며, 할인 계수 γ는 미래 보상의 영향력을 조절한다.
그라디언트는 기대 보상 E_y
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기