DFSMN 기반 고품질 실시간 음성 합성
초록
본 논문은 장기 의존성을 효율적으로 모델링하는 Deep Feed‑forward Sequential Memory Network(DFSMN)를 파라메트릭 TTS의 백엔드로 적용한다. BLSTM 기반 시스템과 비교해 모델 크기와 연산량을 크게 줄이면서도 음성 자연성에서 동등하거나 약간 우수한 성능을 달성한다.
상세 분석
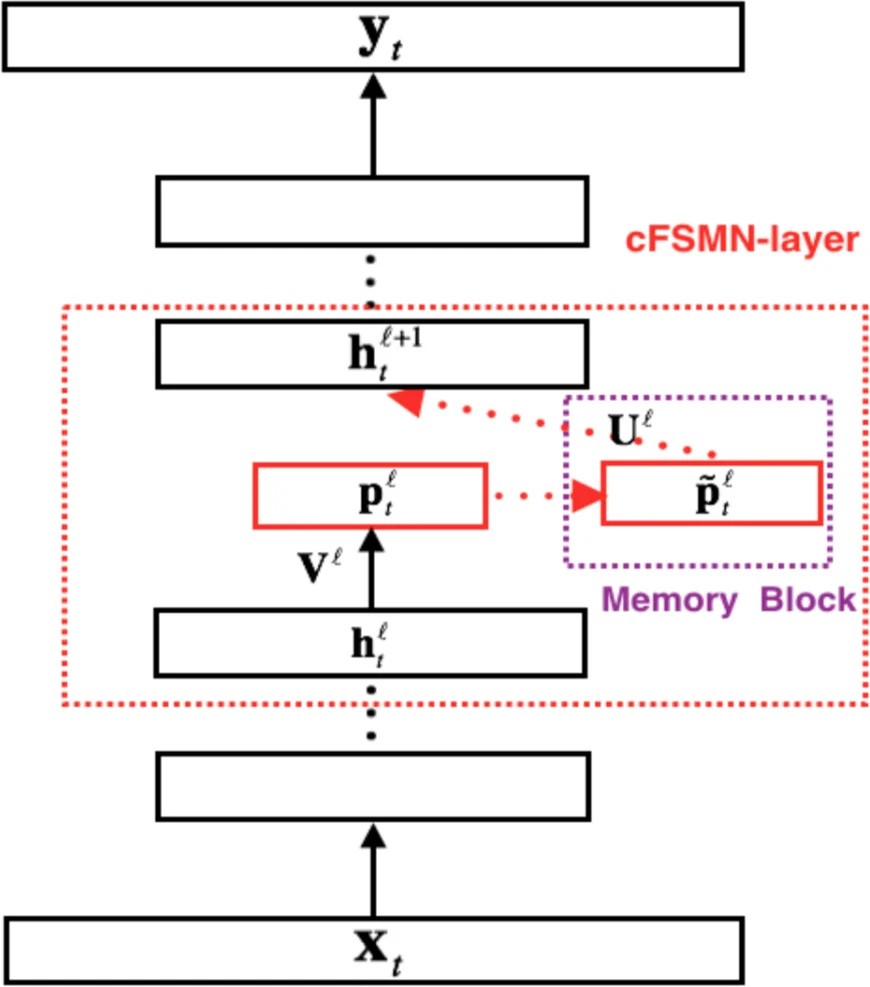
이 연구는 기존의 BLSTM‑RNN 기반 파라메트릭 TTS가 보여준 뛰어난 자연스러움에도 불구하고, 높은 파라미터 수와 실시간 추론 비용이 상용 서비스에 장애가 된다는 점을 출발점으로 삼는다. DFSMN은 순방향 구조에 메모리 블록을 삽입해 과거·미래 프레임을 가중합하는 FIR‑형태의 설계이며, BPTT가 필요 없는 표준 역전파로 학습이 가능해 기울기 소실 문제에 강인하고 학습 속도가 빠르다. 논문은 cFSMN을 저차원 투영과 결합해 파라미터를 절감한 뒤, 이를 다층으로 쌓아 DFSMN을 구성하고, 각 레이어 사이에 스킵 연결을 추가해 깊은 네트워크에서도 그래디언트 흐름을 원활히 한다. 메모리 블록의 ‘order’(look‑back/look‑ahead 프레임 수)와 ‘stride’(프레임 건너뛰기 간격)를 조절함으로써 컨텍스트 윈도우를 유연하게 확장한다. 실험에서는 754 차원의 언어학적 입력을 60 차원 mel‑cepstrum, 3 차원 log‑F0, 11 차원 BAP 등 3개의 음향 스트림과 V/UV 라벨을 동시에 예측하도록 멀티태스크 MSE 손실을 사용했다. BLSTM 베이스라인은 3개의 2048 셀 BLSTM 층(양방향)과 2048 유닛의 전결합층으로 구성돼 약 6.9 MB, 29 G FLOPS를 요구한다. DFSMN은 레이어 수와 order/stride 조합을 다양하게 시험했으며, 특히 10 + 2 레이어(DFSMN 10 + 2)와 order = 40, stride = 2 조합(시스템 H)에서 전체 MSE가 BLSTM보다 낮고, 모델 크기는 6.99 MB(≈½)로 감소, 연산량은 28.9 G FLOPS로 3배 가량 가속되었다. 주관적 MOS 평가에서는 depth = 6, order = 10, stride = 2(시스템 E)가 최고 4.23점을 받아, 약 600 ms(전후 300 ms)의 컨텍스트가 최적임을 시사한다. 더 긴 컨텍스트(≤1200 ms)는 MOS에 유의미한 개선을 주지 못하고 오히려 변동성을 높였다. 따라서 TTS에서 장기 의존성은 필요하지만, 과도한 시간 창은 효율성을 해칠 뿐이다. DFSMN은 FIR‑형 구조이면서도 깊은 스킵 연결을 통해 BLSTM이 구현하는 IIR‑형 장기 기억을 충분히 근사한다는 점에서 이론적·실험적 타당성을 확보한다. 결과적으로 DFSMN은 파라메트릭 TTS의 품질을 유지하면서 메모리와 연산 비용을 크게 절감해, 임베디드·모바일 환경에 적합한 실시간 합성 솔루션으로 자리매김한다.
댓글 및 학술 토론
Loading comments...
의견 남기기